事件等待
事件等待
ZEROKO14事件等待
并发是指多个线程在同时执行:
- 单核(是分时执行,不是真正的同时)
- 多核(在某一个时刻,会同时有多个线程在执行)
同步则是保证在并发执行的各个环境中可以有序的执行
不同版本的内核文件
- 单核
- ntkrnlpa.exe 2-9-9-12分页
- ntoskrnl.exe 10-10-12分页
- 多核
- ntkrnlpa.exe 2-9-9-12分页
- ntoskrnl.exe 10-10-12分页
同样是这个文件名,单核和多核里面的代码是不一样的
为什么需要事件等待
首先需要明确计算机的核心数和线程数
超线程技术 : 逻辑核心 = 物理核心 * 每个核心的线程数(此线程数是可真正并行的线程数)
操作系统创建的线程是通过对逻辑核心的分片来虚拟出的线程,因此可以存在无数个
单行代码原子操作
也称为原子指令
LOCK指令
1 | mov eax,[0x12345678] |
如果产生线程切换就会出问题,因此是多线程不安全的
1 | INC DWORD ptr ds:[0x12345678] |
如果只有单核在跑,上述指令是安全的,但是在多核下可能会出现两个CPU同时执行这一个汇编指令。
1 | int key = 0; |
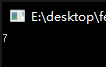
上图表示多核同时执行的时候,多次反复吞掉了中间值,因此不是0。
给dec [x]前加上lock才能保证其是原子操作,即结果为0
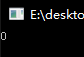
也是说lock后,就是一个原子操作。原子操作是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch (切换到另一个线程),在单处理器系统(UniProcessor,简称 UP)中,能够在单条指令中完成的操作都可以认为是原子操作,因为中断只能发生在指令与指令之间。在多处理器系统(Symmetric Multi-Processor,简称 SMP)中情况有所不同,由于系统中有多个处理器在独立的运行,即使在能单条指令中完成的操作也可能受到干扰。
1 | LOCK INC DWORD ptr ds:[0x12345678] |
这样就真正实现了多核的原子操作(多线程安全),**lock指令锁住了这条指令所在的内存,某一时刻只能有单核访问。**保证了这条指令在多处理器环境中 的原子性
lock只能接如下汇编指令,不然会产生操作码异常(ud)

LOCK前缀只能预加在以下指令前面,并且只能加在这些形式的指令前面,其中目标操作数是内存操作数:add、adc、and、btc、btr、bts、cmpxchg、cmpxch8b,cmpxchg16b,dec,inc,neg,not,or,sbb,sub,xor,xadd和xchg
xchg指令不管有没有声明LOCK前缀,总是会声明LOCK信号。
参考:kernel32.InterlockedIncrement
原子操作相关的API:
- InterlockedIncrement 全局变量++
- InterlockedDecrement 全局变量–
- InterlockedExchange 交换
- InterlockedCompareExchange 比较交换
- InterlockedExchangeAdd
- InterlockedFlushSList
- InterlockedPopEntrySList
- InterlockedPushEntrySList
InterlockedIncrement逆向
1 | .text:7C8097F6 ; LONG __stdcall InterlockedIncrement(volatile LONG *lpAddend) |
多行代码原子操作
临界区:一次只允许一个线程进入直到离开
实现临界区的方式就是加锁
锁:全局变量,进去加1,出去减1

自己实现临界区:
1 | ;全局变量:Flag = 0,临界区标志 |
实验
进入临界区enter函数,退出临界区leave函数
1 | void __declspec(naked) __fastcall enter(PVOID lock) |
未进入临界区
1 | int key = 0; |
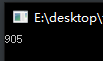
进入临界区
1 | int key = 0; |
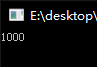
LOCK能保证某个处理器对存储该代码的共享内存的独占使用。
问题
为什么离开临界区也要加lock,不然临界区无效??
系统进出临界区函数
有进入临界区函数RtlEnterCriticalSection,以及离开临界区函数RtlLeaveCriticalSection
ntdll中有进入临界区函数RtlEnterCriticalSection,以及离开临界区函数RtlLeaveCriticalSection
Windows自旋锁
关键代码:
1 | lock bts dword ptr [ecx],0; |
LOCK是锁前缀,保证这条指令在同一个时刻只能有一个CPU访问
BTS指令:设置并检测,将ECX指向数据的第0位置1,如果[ECX]原来的值==0,那么CF=1,否则CF=0
参考:KeAcquireSpinLockAtDpcLevel(SpinLock自旋锁)
1 | .text:0040B40B ; __stdcall KeAcquireSpinLockAtDpcLevel(x) |
总结:
- 自旋锁只对多核有意义。(查看不同版本的
KeAcquireSpinLockAtDpcLevel函数) - 自旋锁与临界区,事件,互斥体一样,都是一种同步机制,都可以让当前线程处于等待状态,区别在于自旋锁不用切换线程(自旋,即pause空转)。
线程等待与唤醒
之前讲解了如何自己实现临界区以及什么是Windows自旋锁,这两种同步方案在线程无法进入临界区时都会让当前线程进入等待状态,一种是通过Sleep函数实现的,一种是通过让当前的CPU“空转”实现的,但这两种等待方式都有局限性:
- 通过Sleep函数进程等待,等待时间该如何确定呢?
- 通过“空转”的方式进行等待,只有等待时间很短的情况下才有意义,否则对CPU资源是种浪费,而且自旋锁只能在多核环境下才有意义。
有没有更加合理的等待方式呢?只有在条件成熟的时候才将当前线程唤醒?
Windows的等待与唤醒机制
在Windows中,一个线程可以通过等待一个或者多个可等待对象,从而进入等待状态,另一个线程可以在某些时刻唤醒等待这些对象的其他线程
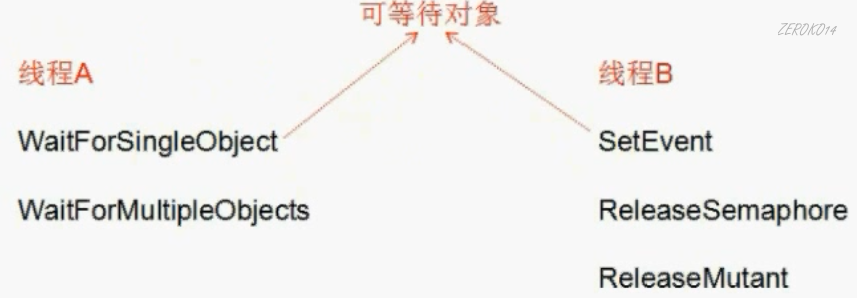
如下可等待对象结构体
| 结构体 | 结构类型 |
|---|---|
| _KPROCESS | 进程 |
| _KTHREAD | 线程 |
| _KTIMER | 定时器 |
| _KSEMAPHORE | 信号量 |
| _KEVENT | 事件 |
| _KMUTANT | 互斥体 |
| _FILE_OBJECT | 文件 |
其共同点是他们都有一个成员是_DISPATCHER_HEADER内嵌结构体。
_FILE_OBJECT没有_DISPATCHER_HEADER内嵌结构体的成员,但它含有_KEVENT内嵌结构体
可等待对象的差异

一个线程等待一个对象
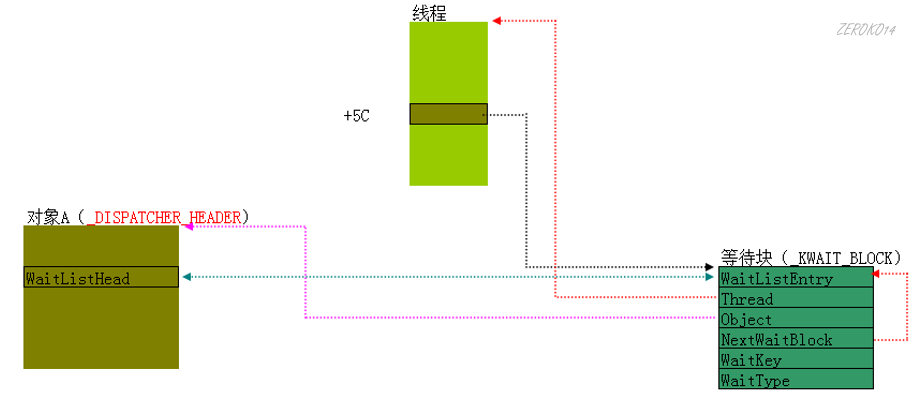
当前线程通过等待块_KWAIT_BLOCK与可等待对象建立起了联系
线程结构体+5C的位置成员WaitBlockList,指向等待块_KWAIT_BLOCK结构体
_KWAIT_BLOCK结构体
1 | typedef struct _KWAIT_BLOCK |
_DISPATCH_HEADER结构体
1 | struct _DISPATCHER_HEADER |
一个线程等待多个对象
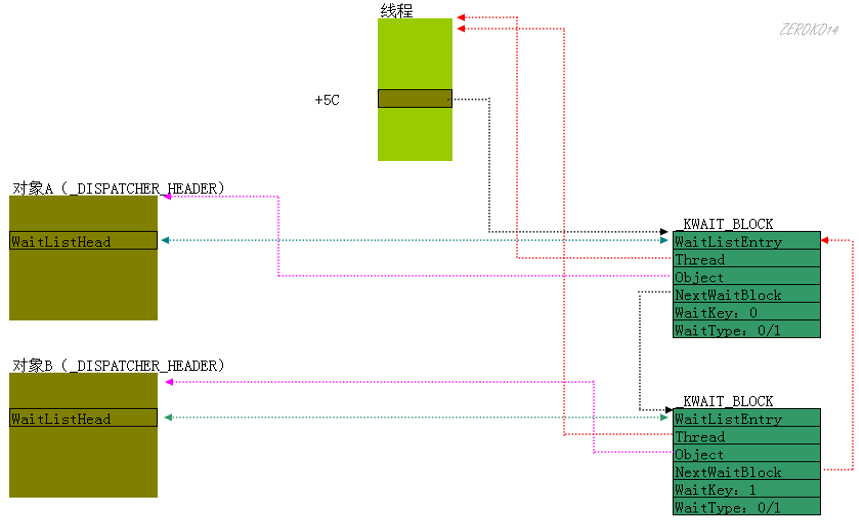
等待网
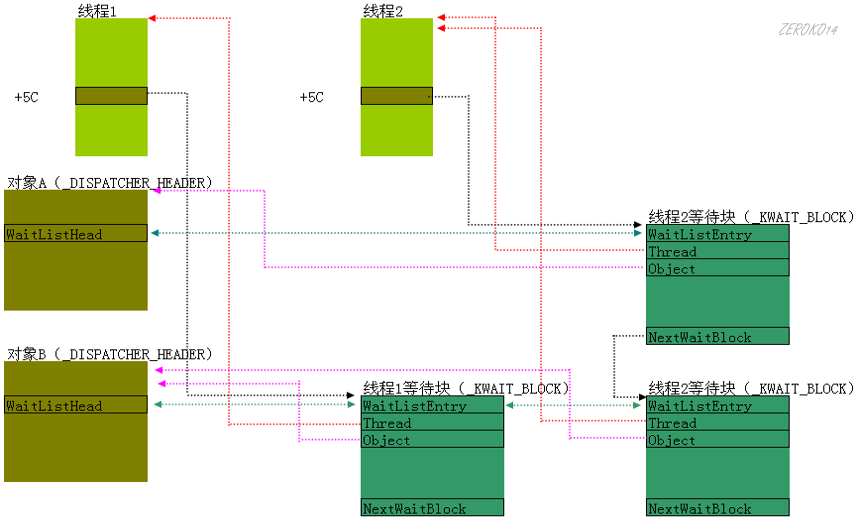
一个线程只要进入等待链表,他一定在这张网上挂着(Sleep的线程也在这个网上挂着,只是他等待的可等待对象是定时器)
总结
- 等待中的线程,一定在等待链表中(KiWaitListHead),同时也一定在这张网上(KTHREAD+5C的位置不为空)
- 线程通过调用WaitForSingleObject/WaitForMultipleObjects函数将自己挂到这张网上。
- 线程什么时候会再次执行取决于其他线程何时调用相关函数,等待对象不同调用的函数也不同。
WaitForSingleObject函数分析
无论可等待对象是何种类型,线程都是通过:
- WaitForSingleObject
- WaitForMultipleObjects
进入等待状态的,这两个函数是理解线程等待与唤醒机制的核心
1 | //WaitForSingleObject对应的内核函数: |
参数解读:
- Handle—用户层传递的等待对象的句柄
- Alertable—对应KTHREAD结构体的Alertable属性,若为1,在插入用户APC的时候,该线程将被吵醒
- Timeout—超时时间
WaitForSingleObject函数流程
- 调用ObReferenceObjectByHandle函数,通过对象句柄找到等待对象结构体地址
- 调用KeWaitForSingleObject函数,进入关键循环
KeWaitForSingleObject函数流程
1 | //_KTHREAD结构体节选: |
+0x070的WaitBlock预留4个等待块空间。第四个等待块空间是固定给定时器使用的。
如果等待的可等待对象数量>3个,那么就会新分配空间,而不是存在默认的这个空间。
上半部分
- 向_KTHREAD(+70)位置的等待块赋值
- 如果超时时间不为0(这种情况下,即使只等待一个可等待对象,也实际上是等待两个对象,这种情况下第四个等待块位置是固定给定时器用的),KTHREAD(+70)第四个等待块与第一个等待块关联起来:第一个等待块指向第四个等待块,第四个等待块指向第一个等待块
(就是等待块中的NextWaitBlock成员指向,如果不设置超时时间,NextWaitBlock是指向自己) - KTHREAD(+5c)指向第一个_KWAIT_BLOCK
- 进入关键循环
下半部分
1 | while(true)//每次线程被其他线程唤醒,都要进入这个循环 |
KeWaitForSingleObject和KeWaitForMultipleObjects的唯一区别仅仅:是前者挂一到两个等待块,后者挂多个等待块。
**【重点理解】**妙不可言
不同的等待对象,用不同的方法来修改_DISPATCHER_HEADER(SignalState)比如:如果可等待对象是EVENT,其他线程通常使用SetEvent来设置SignalState = 1,并且将正在等待该对象的其他线程临时唤醒,也就是从等待链表(KiWaitListHead)中摘出来(线程临时复活)。但是,SetEvent函数并不会将线程从等待网上摘下来,是否要下来由当前线程自己来决定。
强制唤醒
在APC专题,当我们插入一个用户APC时(Alertable=1),当前线程是可以被唤醒的,当并不是真正的唤醒。因为,如果当前的线程在等待网上,执行完用户APC后,仍然要进入等待状态
不同的可等待对象的两点差异:
- 符合激活条件处不同
- 修改SignalState处不同
事件EVENT
事件的**_DISPATCHER_HEADER中的Type为0或1**
线程在进入临界区之前会调用WaitForSingleObject或者WaitForMultipleObjects
- 此时如果有信号,线程会从函数中退出并进入临界区
- 如果没有信号,那么线程将自己挂入等待链表,然后将自己挂入等待网,最后切换线程。
其他线程在适当的时候,调用方法修改被等待对象的SignalState为有信号(不同的等待对象会调用不同的函数),并将等待该对象的其他线程从等待链表中摘掉,这样,当前线程便会在WaitForSingleObject或者WaitForMultipleObjects恢复执行(在哪线程切换在哪恢复执行),如果符合唤醒条件此时会修改SignalState的值,并将自己从等待网上摘下来,此时的线程才是真正的唤醒。
创建事件对象
1 | CreateEvent(NULL,TRUE,FALSE,NULL); |
- 上面函数的第三个参数就是代表了信号初始值,即_DISPATCHER_HEADER中的SignalState成员。
- 第二个参数本质就是_DISPATCHER_HEADER中的Type成员(反值)
- TRUE—-通知类型对象—-_DISPATCHER_HEADER中的Type成员为0
- FALSE—-事件同步对象—-_DISPATCHER_HEADER中的Type成员为1
SetEvent函数分析
SetEvent对应的内核函数:KeSetEvent
- 修改信号值SignalState为1
- 判断对象类型
- 如果类型为通知类型对象(0),唤醒所有等待该状态的线程
- 如果类型为事件同步对象(1),从链表头找到第一个WaitType为1(表示等待一个而非等待全部)的等待块
节选KeWaitForSingleObject单内核版
1 | .text:00405168 loc_405168: ; CODE XREF: KeWaitForSingleObject(x,x,x,x,x)+C0↓j |
信号量Semaphore
信号量的**_DISPATCHER_HEADER中的Type为5**
上面讲到了事件(EVENT)对象,线程在进入临界区之前会通过调用WaitForSingleObject或者WaitForMultipleObjects来判断当前的事件对象是否有信号(SignalState>0),只有当事件对象有信号时,才可以进入临界区(只允许一个线程进入直到退出的一段代码),不单指用EnterCriticalSection()和LeaveCriticalSection()而形成的临界区)。
通过我们对EVENT对象相关函数的分析,我们发现,EVENT对象的SignalState值只有2种可能:
- 1 ==== 初始化时 或者 调用SetEvent时
- 0 ==== WaitForSingleObject,WaitForMultipleObjects,ResetEvent
信号量和事件的区别
信号量和事件的区别在于,信号量允许同时有几个线程进入临界区
创建信号量对象
1 | HANDLE WINAPI CreateSemaphore( |
内核结构解析:
1 | _KSEMAPHORE |
释放信号量对象
1 | ReleaseSemaphore(); |
KeReleaseSemaphore功能描述
- 设置SignalState = SignalState +N(参数)
- 通过WaitListHead找到所有等待当前信号量的线程,从等待链表中摘掉
互斥体MUTANT
为什么要有互斥体的两个原因
- 解决等待对象被遗弃
- 允许重入
解决等待对象被遗弃
互斥体(MUTANT)与事件(EVENT)和信号量(SEMAPHORE)一样,都可以用来进行线程的同步控制。
但需要指出的是,这几个对象都是内核对象,这就意味着,通过这些对象可以进行跨进程的线程同步控制。
1 | A进程中的X线程---》 |
互斥体可以有效解决该问题,系统会处理
当进程意外结束的时候,操作系统的函数会找到正在被当前线程占用的互斥体
允许重入
1 | WaitForSingleObject(A)//A走完这一步已经无信号了 |
互斥体结构
1 | _KMUTANT |
创建互斥体
1 | HANDLE CreateMutexW( |
1 | CreateMutex -> NtCteateMutant(ApcDisable==0)(内核函数) -> KeInitializeMutant(内核函数)//3环调用CreateMutex宏一定创建的是Mutant(ApcDisable==0) |
- ApcDisable==0 NtCteateMutant
- ApcDisable==1 NtCreateMutex
KeInitializeMutant主要功能:初始化MUTANT结构体
- MUTANT.Header.Type=2;
- MUTANT.Header.SignalState=bInitialOwner?0:1;
- MUTANT.Header.OwnerThread=当前线程 or NULL;
- MUTANT.Header.Abandoned=0;
- MUTANT.Header.ApcDisable=0;
- bInitialOwner == TRUE 将当前互斥体挂入到当前线程的互斥体链表(KTHREAD+0x10 MutantListHead)
释放互斥体
1 | BOOL WINAPI ReleaseMutex(HANDLE hMutex); |
如何解决等待对象被遗弃问题
意外终结的时候,系统会调用如下函数
1 | MmUnloadSystemImage->KeReleaseMutant(X,Y,Abandon,Z)//这个调用流程的Abandon一定是TRUE,表示释放的是非正常释放的互斥体 |
