字符编码
字符编码
ZEROKO14有关字符编码的知识点
字符编码
下面介绍多种编码方式:
ANSI编码
原始的ASCII编码
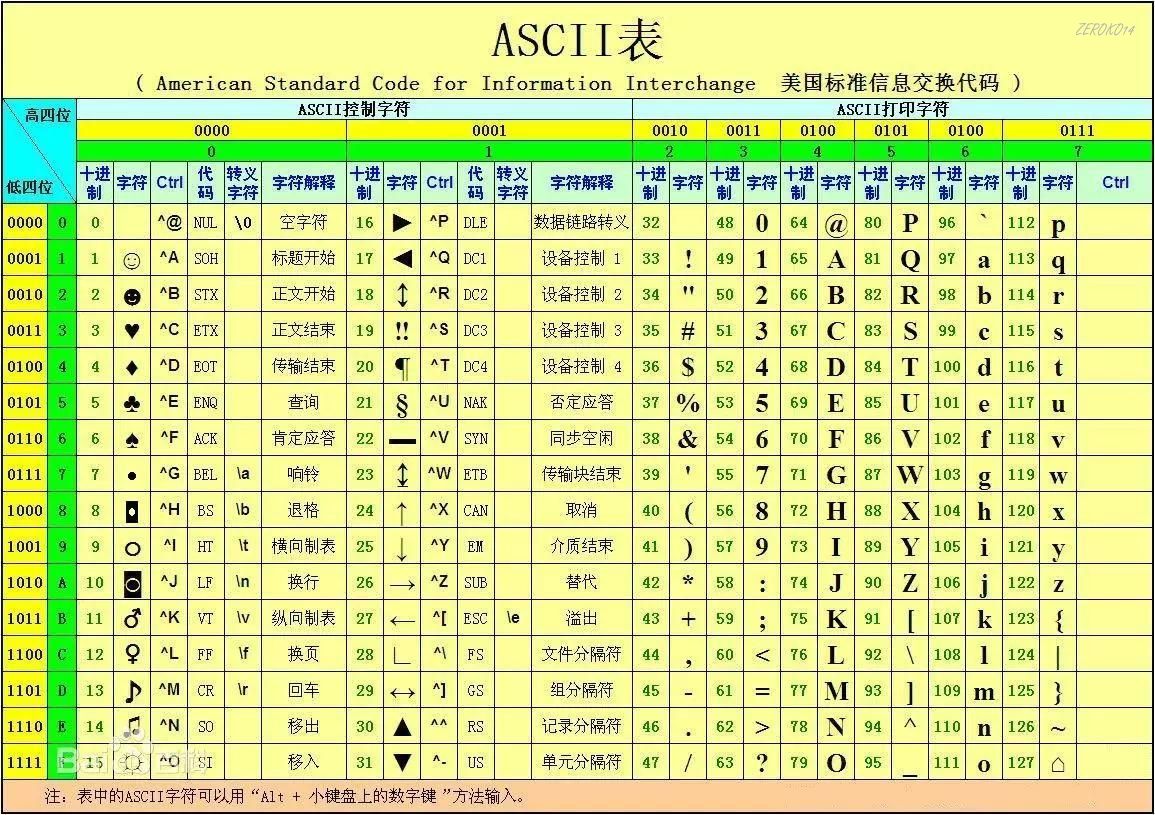
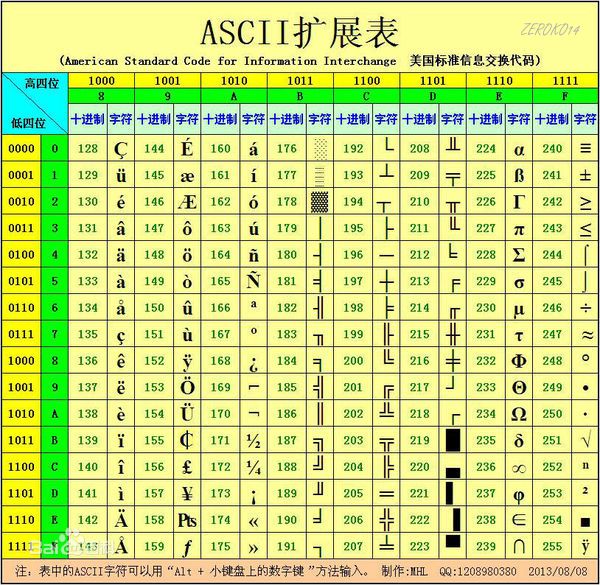
原始的ASCII码只占一个字节
ASCII编码的拓展:GB2312(GBK)或GB2312-80
GB2312或GB2312-80:专门用来表示中文的编码
实现原理
把80~FF的表给占用了,由80~FF开头的两个字节拼在一起表示一个字符
1 | 中国 |
GB2312(GBK)或GB2312-80也就是ANSI编码(各国各自的编码格式统称ANSI)
缺点
其他象形文字国家也是采取和我国一样的策略,所以各个国家看到的同一个编码意思不一致。
ANSI编码也就是GB2312(GBK)或GB2312-80,表示英文字符时用一个字节,表示中文字符时用两个或4个字节
UNICODE编码
一张包含全世界所有文字的一个编码表,Unicode的编码范围是:0~0x10FFFF,可以容纳100多万个符号!
但他只是一个符号集,只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
UCS-2和UCS-4
在将UTF8和UTF16、UTF32的区别之前,再先科普两个名词:UCS-2和UCS-4。
Unicode是为整合全世界的所有语言文字而诞生的。任何文字在Unicode中都对应一个值, 这个值称为代码点(code point,也称码值)。代码点的值通常写成
U+ABCD的格式。而文字和代码点之间的对应关系就是UCS-2(Universal Character Set coded in 2 octets)。顾名思义,UCS-2是用两个字节来表示代码点,其取值范围为U+0000~U+FFFF。为了能表示更多的文字,人们又提出了UCS-4,即用四个字节表示代码点。它的范围为
U+00000000~U+7FFFFFFF,其中U+00000000~U+0000FFFF和UCS-2是一样的。
要注意,UCS-2和UCS-4只规定了代码点和文字之间的对应关系,并没有规定代码点在计算机中如何存储。规定存储方式的称为UTF(Unicode Transformation Format),也就是我们下面将要提到的UNICODE编码的存储方式。
UNICODE编码的存储方式
UTF-16
java、js、c#、python默认的字符串内部编码都是utf-16。
UTF-16编码以16位无符号整数为单位,注意是16位为一个单位,不表示一个字符就只有16位。这个要看字符的unicode编码处于什么范围而定的,绝大部分是2个字节,极少数是4个字节(因此可以算是2字节定长编码)。现在机器上的unicode编码一般指的就是UTF-16。
1 | UTF-16小端存储 |
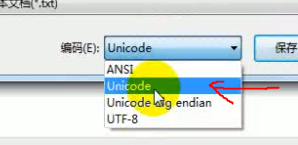
上图箭头所指的没有明确说明是哪种存储方式的Unicode实际上就是UTF-16
优缺点:拆分解析快,浪费空间多(尤其是网络传输,但传输汉字可能比utf8省空间,因为utf8下很多汉字要3字节),需要区分字节序。文件保存一般有个bom头:BE-‘FEFF’、LE-‘FFFE’
U+D800到U+DFFF是没有定义unicode的,utf-16用这段来标识4字节字符。分高低位,共20个有效bit位。如果不支持非UCS-2的unicode,可以直接不认这个范围里的字符。
UTF-8
一种变长的存储方案
网络传输火起来的编码格式
UTF-8的编码规则:
- 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
- 对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码
- UTF-8对于字节的格式有严格要求,当解析某个字符失败时,使用
 代替(UTF-8编码为
代替(UTF-8编码为EF BF BD)
 代替(UTF-8编码为
代替(UTF-8编码为| Unicode符号集 | UTF-8(x表示Unicode符号集) |
|---|---|
| 0~7F | 0xxxxxxx |
| 80~7FF | 110xxxxx 10xxxxxx |
| 800~FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 10000~10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
因此占用1~4个字节都有可能
1 | A中 |
数据大部分是英文字符的话采用UTF-8比较好,中文多的话采用UTF-16比较好
优缺点:拆分解析慢,但节省空间(尤其是网络传输)
获取utf8字符字节数的代码
1 | // 获取UTF-8单字符所占的字节数 |
[[STL#string操作utf8案例|mac上string操作utf8编写案例]]
UTF-32
任何元素都是4个字节为单位。
1 | A 中 |
BOM字节顺序标识
Byte Order Mark
文本文件的起始位置存这几个字节来表示当前文件采用什么格式存储
| 存储格式 | BOM |
|---|---|
| UTF-8 | EF BB BF |
| UTF-16LE(小端存储) | FF FE |
| UTF-16BE(大端存储) | FE FF |
| UTF-32LE | FF FE 00 00 |
| UTF-32BE | 00 00 FE FF |
添加BOM头
1 | std::ofstream ofs("d:\\Temp\\test.txt"); //文件是utf8编码 |
[[QT]]中添加BOM头提供了封装好的函数
1 | QTextStream out(&data); |
ANSI和UTF8之间的转换原理 必须通过UCS-2/UCS-4
操作系统字符集
编译环境和运行环境
- 编译器转换程序源代码时,所处的环境成为编译环境(translation environment);
- 编译后程序执行时,所处的环境称为运行环境(execution environment)
源码字符集和执行字符集
- 源码字符集(the source character set) 源码文件是使用何种编码保存的
- 执行字符集(the execution character set) 可执行程序内保存的是何种编码(程序执行时内存中字符编码)
在编译时,编译器会根据源文件的编码(源码字符集)将字符串字面量转换为目标字符串。只要没有进行编码转换,字符串字面量在程序中的表示形式将与其在源代码中的编码相同。
操作系统字符集
除windows平台外大部分其他平台,编译器默认使用的编码都是UTF-8编码,最新版本的Clang编译器只支持UTF-8编码
- windows中文版默认采用gbk编码
- linux,mac默认采用utf-8编码
GCC编译器:
1 | -finput-charset 指定源文件的编码 (若不指定,默认是UTF-8) |
clang编译器:
同上设置方式,但不支持设定为gbk
VCC编译器:
VCC 是指 Visual C++ Compiler,即 Visual Studio 中的 C++ 编译器。MSVC 提供了一个完整的开发环境,包括编译器、链接器、调试器等工具,用于开发和构建 C++ 程序。VCC 是 MSVC 中的核心组件之一,负责将 C++ 代码编译成可执行文件或库。
1 | 项目的属性设置 - C/C++编译器选项 - 附加选项 中添加:/source-charset:utf-8和/execution-charset:utf-8 |
控制台
windows控制台字符编码使用的是系统默认的编码,可以通过
chcp命令查看。如果控制台的编码不是UTF-8(对应编码:65001),显示UTF-8字符串会出现乱码,可通过chcp 65001命令修改控制台的编码,从而正常显示UTF-8字符串。
[[mac及linux_C++环境#windows下的vscode终端乱码|windows下的vscode终端乱码解决]]
字符集转换
如果程序需要在多个平台编译运行,则代码必须使用UTF-8。使用UTF-8可以更容易的在多字节字符串(char*, std::string)和宽字符(wchar_t* std::wstring)直接转换,更容易避免程序乱码,中文路径错误等问题。
C++11 中引入的 char16_t 和 char32_t
主要使用C++11引入的wstring_convert和codecvt相结合进行转换。但在C++17遭到废弃
windows下常用转码需求
下面的代码在windows上完美运行(linux转码需求小)。GBK在linux下的locale名可能是”zh_CN.GBK”,而windows下是”.936”),因此做跨平台的话仍然要给不同的系统做适配
utf8的宽窄字符转换
std::string 转为 std::wstring
1
2
3
4
5std::wstring utf8_to_wstr(const std::string& src)
{
std::wstring_convert<std::codecvt_utf8<wchar_t>> converter;
return converter.from_bytes(src);
}注意:使用这个函数的时候需要求std::string的编码是utf-8,不然会抛异常。
std::wstring转为std::string
1
2
3
4
5std::string wstr_to_utf8(const std::wstring& src)
{
std::wstring_convert<std::codecvt_utf8<wchar_t>> convert;
return convert.to_bytes(src);
}
utf8与gbk互转
下面utf-8和gbk互转的代码,都是先转化为std::wstring的,我们可以再拆分。得到std::wstring和gbk互转。
utf-8转gbk
1 | std::string utf8_to_gbk(const std::string& str) |
gbk转utf-8
1 | std::string gbk_to_utf8(const std::string& str) |
gbk的宽窄字符互转
std::string 转为 std::wstring
1
2
3
4
5
6
7std::wstring gbk_to_wstr(const std::string& str)
{
//GBK locale name in windows
const char* GBK_LOCALE_NAME = ".936";
std::wstring_convert<std::codecvt_byname<wchar_t, char, mbstate_t>> convert(new std::codecvt_byname<wchar_t, char, mbstate_t>(GBK_LOCALE_NAME));
return convert.from_bytes(str);
}std::wstring转为std::string
1
2
3
4
5
6
7std::string wstr_to_gbk(const std::wstring& wstr)
{
// GBK locale name in Windows
const char* GBK_LOCALE_NAME = ".936";
std::wstring_convert<std::codecvt_byname<wchar_t, char, mbstate_t>> convert(new std::codecvt_byname<wchar_t, char, mbstate_t>(GBK_LOCALE_NAME));
return convert.to_bytes(wstr);
}
两个比较好的两个第三方库分别是 UTF8-CPP以及Boost.Locale。
UTF8和UTF16互转
1 |
|
上面在C++17被废弃了
转而:
1 | //c++17 |
UTF8和UTF32互转
1 | std::u32string to_utf32(const std::string& str) // UTF-8 to UTF-32 |
u8string转换为string
可以通过这种方式转换为string类型,本质上就是字节流拷贝
1 | u8string u8str =u8"你好,世界"; |
wchart_t*转char*
1 |
|
将宽字符(wchar_t)转换为多字节字符(char),在 UNICODE 模式下使用。
char*转wchar_t*
1 |
|
将多字节字符(char)转换为宽字符(wchar_t),在 UNICODE 模式下使用。
字符集总结
| 字符类型 | 字符串类型 | 字符长度(bit) | 引入的C++版本 |
|---|---|---|---|
| char | string | 8 | 开始就存在 |
| char8_t | u8string | 8 | 20 |
| char16_t | u16string | 16 | 11 |
| char32_t | u32string | 32 | 11 |
| wchar_t | wstring | 在不同的编译器和操作系统上不同 | 开始就存在 |
cout不支持直接对u8string,u16string,u32string,wstring等的输出.可以通过下面方式:
- wstring使用wcout来输出
- u8string,u16string,u32string使用转换方式来输出
一些建议:
-
char8_t及u8string在标准中不受支持,任何系统API都不支持(而且可能永远不会,因为兼容性原因)。在大多数平台上,普通的
char字符串已经是UTF-8,在Windows上,您可以使用/utf-8进行编译,这将在主要的操作系统上为您提供可移植的Unicode支持。您甚至不能使用u8字符串在C++20中编写Hello程序: wchar_t因为平台之间的兼容性的问题,同样不建议用
C语言中的宽字符
宽字符类型
- char:多字节字符类型
- wchar_t:宽字符类型
wchar_t在windows是 16 位,而在linux上是 32 位。这使得移植变得困难。linux平台的std::wstring就是std::u32string, wchar_t 就是char32_t (utf-32编码)
1 | char szStr[]="中国";//使用的是ANSI编码 D6 D0 B9 FA 00 (一个字节的零表示结尾) |
字符常用函数
使用的函数版本根据编码不同也被提供了两套
| 多字节字符函数 | 宽字符函数 | 作用 |
|---|---|---|
| printf | wprintf | 打印到控制台函数 |
| strlen | wcslen | 获取长度 |
| strcpy | wcscpy | 字符串复制 |
| strcat | wcscat | 字符串拼接 |
| strcmp | wcscmp | 字符串比较 |
| strstr | wcsstr | 字符串查找功能 |
===
下面是Windows定义的一组字符串函数,这些函数用来计算字符串长度、复制字符串、连接字符串和比较字符串:
1 | ILength = lstrlen (pString) ; |
这些函数与C链接库中对应的函数功能相同。如果定义了UNICODE标识符,那么这些函数将接受宽字符串,否则只接受常规字符串。宽字符串版的lstrlenW函数可在Windows 98中执行。
设置字面量的编码方式
C++11 标准引入了原始字符串字面量(Raw String Literal)和 Unicode 字符串字面量(Unicode String Literal)的语法,其中 u”” 用于表示 Unicode 字符串字面量。这种格式允许在字符串中直接使用 Unicode 字符,而无需进行转义或使用特殊的编码方式
字符串字面量(string literals)前面可以加上不同的前缀来表示不同的含义。以下是常用的字符串字面量前缀及其含义:
L前缀:表示宽字符(wide character)字符串。宽字符字符串是由 wchar_t 类型表示的字符串,每个字符占用 2 个字节。例如,L"Hello"表示一个由宽字符组成的字符串。u8前缀:表示 UTF-8 编码的字符串。UTF-8 是一种可变长度的 Unicode 编码,每个字符占用 1 到 4 个字节。例如,u8"你好"表示一个由 UTF-8 编码的字符串。u前缀:表示 Unicode(UTF-16) 编码的字符串。Unicode 编码是一种固定长度的字符编码,每个字符占用 2或4 个字节。例如,u"こんにちは"表示一个由 Unicode 编码的字符串。U前缀:表示 UTF-32 编码的字符串。UTF-32 是一种固定长度的 Unicode 编码,每个字符占用 4 个字节。例如,U"🌞"表示一个由 UTF-32 编码的字符串。R前缀:表示原始字符串(raw string)。原始字符串中的特殊字符不会被转义,可以直接包含在字符串中。例如,R"(C:\Windows\System32)"表示一个包含反斜杠的字符串,而不需要对反斜杠进行转义。