数据库
数据库
ZEROKO14数据库是为了实现一定的目的按某种规则组织起来的数据的集合, 简单的说,数据库就是存储数据的库.
常见数据库
1 oracle公司的oracle数据库
2 IBM公司的DB2数据库
3 Informix公司的Informix数据库
4 sysbase公司的sysbase数据库
5 Microsoft公司的SQL Server
6 oracle的MySQL数据库(开始属于mysql公司,后来mysql被sun收购,sun又被oracle收购)
7 MongoDB数据库(json键值对的非关系数据库)
数据库理论
软考知识点

考点分值

数据库基本概念
体系结构
- 集中式数据库系统
- 数据是集中的
- 数据管理是集中的
- 数据库系统的素有功能(从形式的用户接口到DBMS核心)都集中在DBMS所在的计算机
- C/S结构
- 客户端负责数据表示服务
- 服务器主要负责数据库服务
- 数据库系统分为前端和后端
- ODBC,JDBC
- 分布式数据库 (最早是为了做容灾的操作)
- 物理上分布,逻辑上集中
- 物理上分布,逻辑上分布
- 并行数据库
- 共享内存式
- 无共享式
分布式数据库
- 数据独立性: 除了数据的逻辑独立性与物理独立性外,还有数据分布独立性(分布透明性)
- 集中与自治共享结合的控制结构: 各局部的DBMS可以独立地管理局部数据库,具有自治的功能.同时,系统又设有集中控制机制,协调各局部DBMS的工作,执行全局应用
- 适当增加数据冗余度: 在不同的场地存储同一数据的多个副本,可以提高系统的可靠性和可用性,同时也能提高系统性能

分布式数据库透明性
- 分片透明(分块透明): 用户不必关心数据是如何分片的,他们对数据的操作在全局关系上进行,即如何分片对用户是透明的
- 复制透明: 用户不用关心数据库在网络中各个节点的复制情况,被复制的数据的更新都由系统自动完成
- 位置透明: 用户不必知道所操作的数据放在何处,即数据分配到哪个或哪些站点存储对用户是透明的
- 局部映像透明性(逻辑透明): 是最低层次的透明性,该透明性提供数据到局部数据库的映像,即用户不必关心局部DBMS支持哪种数据模型,使用哪种数据操纵语言,数据模型和操纵语言的转换是由系统完成的.因此,局部映像透明性对异构型和同构异质的分布式数据库系统是非常重要的

三级模式结构
三级模式和两级映射/映像

两级映射的作用
- 外模式-概念模式映射: 逻辑独立性,数据的逻辑结构发生变化后,用户程序也可以不修改.但是为了保证应用程序能够正确执行,需要修改外模式和概念模式之间的映射
- 概念模式-内模式映射: 物理独立性,当数据的物理结构发生改变时,应用程序不用改变,但是为了能够保证应用程序能够正确执行,需要修改概念模式和内模式之间的映射



数据仓库
数据仓库的特点
- 面向主题: 数据按主题组织
- 集成的: 消除了源数据中的不一致性,提供整个企业的一致性全局信息
- 相对稳定的(非易失的): 主要进行查询操作,只有少量的修改或删除操作(或是不删除)
- 反映历史变化(随着时间变化): 记录了企业从过去某一时刻到当前各个阶段的信息,可对发展历程和未来趋势做定量分析和预测

OLAP 数据仓库(联机分析处理系统)
查询通常是复杂的,涉及大量数据的聚合和计算,查询速度较慢,但可以处理大量数据
通常使用多维数据模型,数据以数据立方体的形式存储,适合复杂的查询和分析
OLTP 数据库(联机事务处理系统)
查询通常是简单的,涉及单条记录的快速读取和写入,查询速度快
通常使用关系型数据库模型,数据以表的形式存储,适合快速的插入、更新和删除操作

概念结构设计
概念设计的过程

集成的方法:
- 多个局部E-R图一次集成
- 逐步集成,用累加的方式一次集成两个局部E-R
集成产生的冲突及解决方法: (针对同一个对象)
- 属性冲突: 包括属性域冲突和属性取值冲突
- 命名冲突: 包括同名异义和异名同义
- 结构冲突: 包括同一个对象在不同应用中具有不同的抽象,以及同一实体在不同局部E-R图中所包含的属性个数和属性排列次序不完全相同
E-R图
实体关系图

属性
简单属性和复合属性
- 简单属性是原子的,不可再分的
- 复合属性可以细分为更小的部分(即划分为别的属性)
单值属性和多值属性:
单值属性: 定义的属性对于一个特定的实体都只有单独的一个值
多值属性: 在某些特定情况下,一个属性可能对应一组值
如一个学生的家长姓名,可以多个:就是多值属性
NULL属性: 表示无意义或不知道
派生属性: 可以从其他属性得来 (如通过身份证号推算出来的年龄就是派生属性)
联系
二元联系
两个不同实体集之间的联系
- 一对一
1:1 - 一对多
1:n - 多对多
m:n
注意如果写的是n:n,表示的是相同数量的多对多

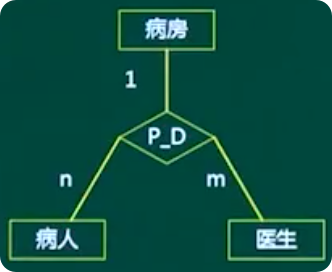
三元联系的关系判断
两个以上不同实体集之间的联系
以三元关系中的一个实体作为中心,假设另两个实体都只有一个实例:
若中心实体只有一个实例能与另两个实体的一个实例进行关联,则中心实体的连通数为“一”
若中心实体有多于一个实例能与另两个实体实例进行关联,则中心实体的连通数为“多”
以病房为核心,一个病人住一个病房,一个医生管理一个病房,因此病房端的连通数为”一”
以病人为核心,一个病房住多个病人,一个医生治疗多个病人,因此病人端的连通数为”多”
以医生为核心,一个病房只有一个医生,一个医生治疗多个病人,因此医生端的连通数为”多”
三元的联系中,以其中一个为核心,另外两个只要有一个和核心的关系为多,则核心端的连通数就是”多”
同一个实体集内的二元联系
一个实体集可以表示多个实体

主队和客队其实都是属于球队这个实体集
扩充的E-R模型
弱实体: 在现实世界中有一种特殊的依赖联系,该联系是指某实体是否存在对于另一些实体具有很强的依赖关系,即一个实体的存在必须以另一个实体为前提,而将这些实体称为弱实体,如家属与职工的联系,附件与邮件
特殊化: 在现实世界中,某些实体一方面具有一些共性,另一方面还具有各自的特性,一个实体集可以按照某些特征区分为几个子实体
聚集: 一个联系作为另一个联系的一端

家属是职工的弱实体
经理是员工的特殊化
经理 与 租赁联系关系整体 有签约关系的联系
逻辑结构设计
逻辑结构设计阶段其实是从概念模型转换为数据模型
数据模型
- 层次模型
- 网状模型
- 关系模型
- 面向对象模型
数据模型三要素
- 数据结构 p.s.这个数据结构与算法中的数据结构不是一个意思
- 数据操作
- 数据的约束条件
关系模式
其实就是二维表的形式
相关概念
目/度: 关系模式中属性的个数
候选码(候选键): 唯一标识元组,且无冗余(多个属性共同作为唯一标识也可以共同作为候选键,但是如果单个属性已经可以唯一标识了,就不能多个这样的属性作为候选键,这就叫无冗余)
候选码的定义要求最小性,也就是不可再分解。比如,如果学号本身就能唯一标识学生,那么(学号,姓名)虽然也能唯一标识,但因为学号单独就可以,所以这个组合就不是候选码
主码(主键): 在候选键中任选一个,通常取决于实际需求
主属性与非主属性: 任一候选码中任一属性都属于主属性,其他就是非主属性
外码(外键): 引用其他关系的主码的属性或属性组
全码(ALL-Key): 关系模式的所有属性组是这个关系的候选键
全码意味着整个属性组合才能唯一标识元组,没有更小的候选码存在
关系的三种类型
- 基本关系
- 查询表
- 视图表
查询表和视图表都是虚表,并没有进行实质的存储
完整性约束
实体完整性约束
主键必须是唯一的并且非空
参照完整性约束
外键,要么是其他关系的主键,要么是空(因为有可能没有分配)
用户自定义完整性约束
使用check自定义的约束
触发器: 可以完成一些复杂的约束条件的设定
E-R图转关系模式
一个实体型必须转换为一个关系模式

联系转关系模式:
| 关系类型 | 实体(独立关系模式) | 关系(独立关系模式) | 关系(归并关系模式) | 备注 |
|---|---|---|---|---|
| 1对1 | ✅ | ✅ | ✅ | 并入任一端 |
| 1对多 | ✅ | ✅ | ✅ | 并入多端 |
| 多对多 | ✅ | ✅ | ❌ | - |
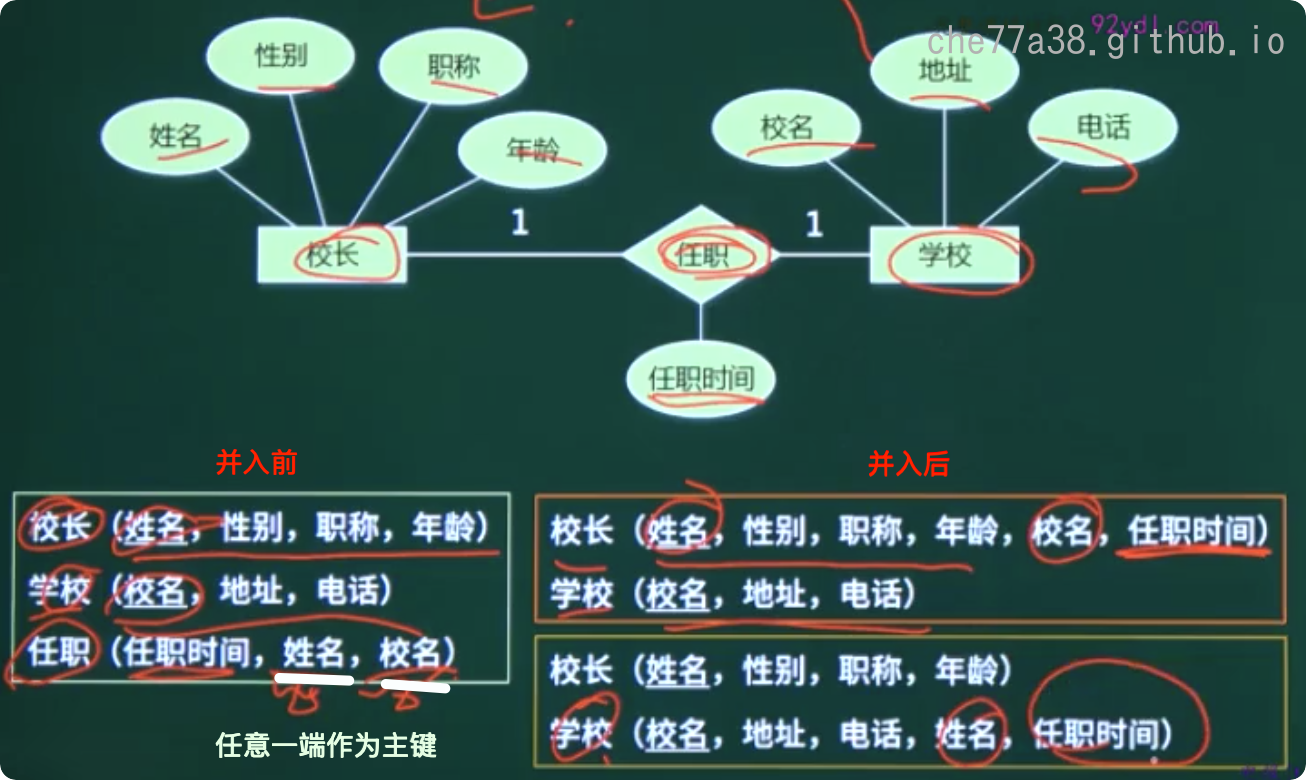
一对一联系的转换有两种方式
独立的关系模式: 并入两端主键及联系自身属性(主键: 任一段主键)
归并(任意一端): 并入另一端主键及联系自身属性(主键: 保持不变)

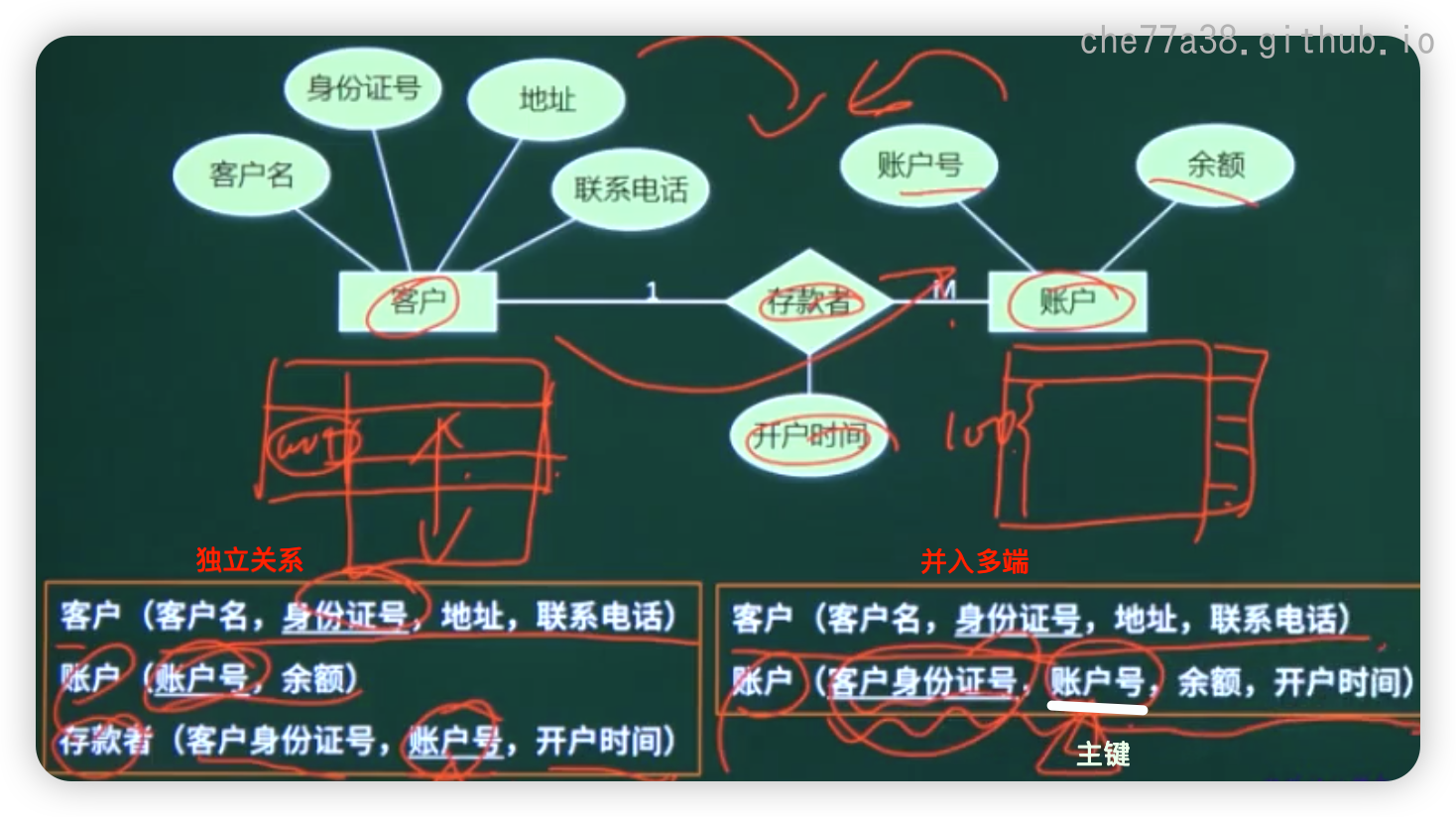
一对多联系的转换有两种方式
独立的关系模式: 并入两端主键及联系自身属性(主键: 多端主键)
归并(多端): 并入另一端主键及联系自身属性(主键: 保持不变)
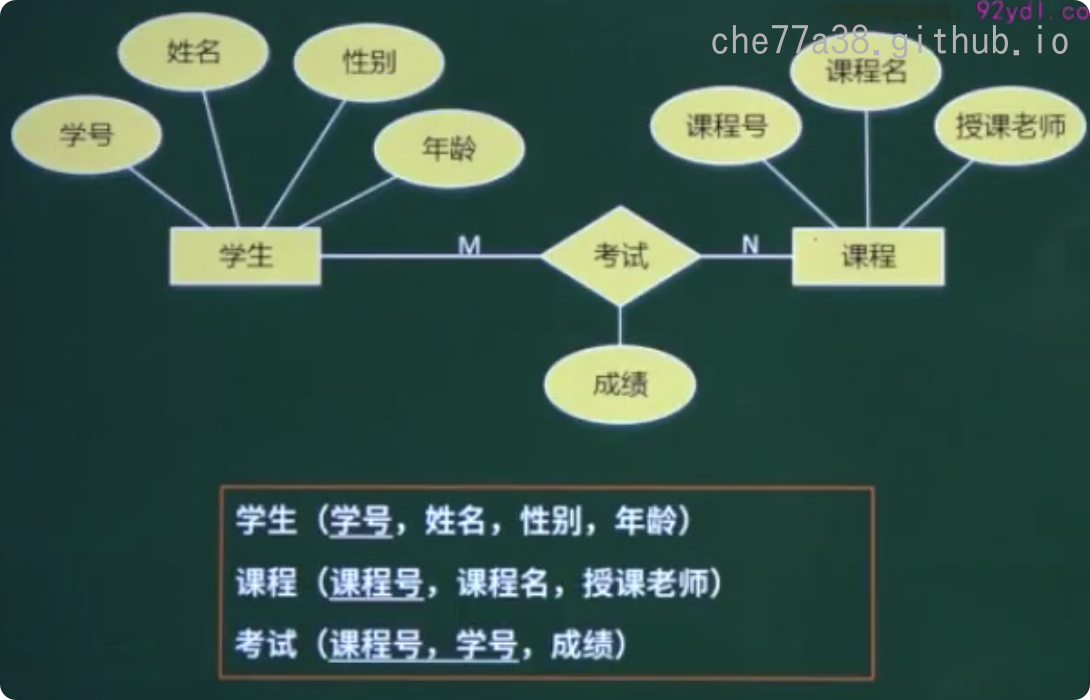
多对多联系的转换只有一种方式
独立的关系模式: 并入两端主键及联系自身属性(主键: 两端主键的组合键)
规范化理论
属于数据库中比较有难点的知识,几乎每次必考,分值范围:2~4分
基本概念
函数依赖: 设R(U)是属性U上的一个关系模式,X和Y是U的子集,r为R的任一关系,如果对于r中的任意两个元组u,v,只要有u[X]=v[Y],就有u[Y]=v[Y],则称X函数决定Y,或称Y函数依赖于X(X函数决定Y函数),记为X->Y。
X为决定因素,Y为被决定因素

规范化理论-Amstrong公理体系
关系模式R<U,F>来说,有以下的推理规则:
A1.自反律(Reflexivity): 若$Y \subseteq X \subseteq U$,则X->Y成立
举例理解: 设U是
a,b,c集合,X是a,b集合,y是b集合,则X可以决定Y,即可以唯一找到一个b与之对应A2.增广律(Augmentation): 若$Z \subseteq U$且X->Y,则XZ->YZ成立
A3.传递律(Transitivity): 若X->Y且Y->Z,则X->Z成立
根据A1,A2,A3这三条推理规则可以得到下面三条推理规则:
- 合并规则: 由X->Y,X->Z,有X->YZ (A2,A3)
- 伪传递规则: 由X->Y,WY->Z,有XW->Z (A2,A3)
- 分解规则: 由X->Y及$Z \subseteq Y$,有X->Z (A1,A3)
$\subseteq$ 符号表示集合的包含关系,也就是说,如果 $A \subseteq B$,则集合 A 是集合 B 的子集(或等于 B),用于描述哪些属性是某个集合的一部分
例题

候选键
候选键: 唯一标识元组,且无冗余
图示法求候选键
- 将关系的函数依赖关系,用“有向图”的方式表示。
- 找出入度为0的属性,并以该属性集合为起点,尝试遍历有向图,若能正常遍历图中所有结点,则该属性集即为关系模式的候选键。(入度为0的属性一定至少是候选键的一部分)
- 若入度为0的属性集不能遍历图中所有结点,则需要尝试性的将一些中间结点(既有入度,也有出度的结点)并入入度为0的属性集中,直至该集合能遍历所有结点,集合为候选键。
例题
题1

题2

上面题的有向图如下:

题3

这里要注意: 因为A->BC,通过分解规则,因为B与C都是BC的子集,所以可知A->B,并且A->C

题4

题目需要判断有哪些主属性和哪些非主属性?
先画出有向图:

可知,候选键有两组: ST+CITY 以及 ZIP+ST
因此答案为: 主属性: ST,CITY,ZIP; 非主属性: 不存在
题5

题6

范式判断
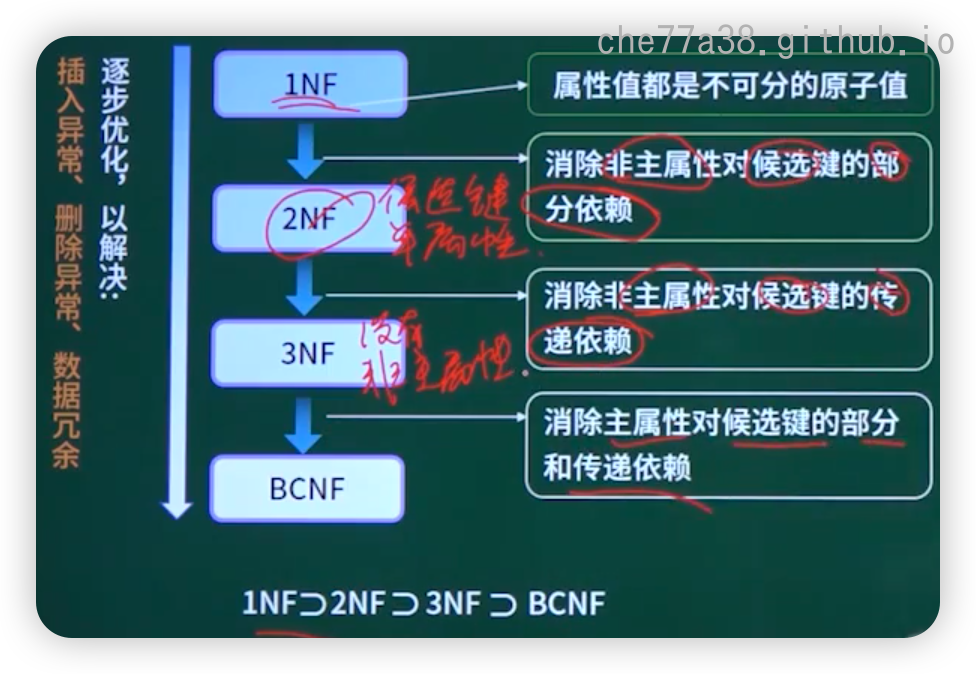
1 | graph TD |
$$
1NF\supset2NF\supset3NF\supset BCNF
$$
| 范式 | 属性不可再分 | 非主属性部分函数依赖于候选键 | 非主属性传递函数依赖于候选键 | 函数依赖左侧决定因素包含候选键 |
|---|---|---|---|---|
| 1NF | √ | 存在 | ||
| 2NF | √ | 不存在 | 存在 | |
| 3NF | √ | 不存在 | 不存在 | 不满足 |
| BCNF | √ | 不存在 | 不存在 | 满足 |
关系模式R(学生姓名,选修课程名,任课教师名,任课教师地址),如下:
| 学生姓名 | 选修课程名 | 任课教师名 | 任课教师地址 |
|---|---|---|---|
| 张三 | 数学 | 王一新 | 五一路107号 |
| 李四 | 数学 | 王一新 | 五一路107号 |
| 王五 | 数学 | 王一新 | 五一路107号 |
| 赵六 | 数学 | 王一新 | 五一路107号 |
| … | … | … | … |
问题如下:
- 数据冗余: 可见上表存在大量相同的数据冗余
- 修改异常: 如果老师发生变化,容易产生修改异常
- 插入异常: 如果有老师来了,暂时还没教学生,则无法插入这样的老师
- 删除异常: 当学生毕业后被删掉了,老师信息会被相应的删掉
第一范式
第一范式(1NF): 在关系模式R中,当且仅当所有域只包含原子值,即每个属性都是不可再分的数据项,则称关系模式R是第一范式
不满足第一范式的话,建表都会失败
如: 关系模式R(系名称,高级职称人数)是否满足1NF? 不满足!

第二范式
第二范式(2NF): 当且仅当关系模式R是第一范式(1NF),且每一个非主属性完全依赖候选键(没有不完全依赖)时,则称关系模式R是第二范式
思考题:关系模式SC(学号,课程号,成绩,学分),其中:(学号,课程号)->成绩,课程号->学分,会存在哪些问题(从数据冗余、更新异常、插入异常、删除异常这几个方面来考虑),解决方案是什么?
| 学号 | 课程号 | 成绩 | 学分 |
|---|---|---|---|
| S01 | C01 | 75 | 4 |
| S02 | C01 | 92 | 4 |
| S03 | C01 | 87 | 4 |
| S04 | C01 | 55 | 4 |
| S01 | C02 | 87 | 2 |
| S02 | C02 | 95 | 2 |
| S01 | C03 | 94 | 5 |
| … | … | … | … |
判断第二范式流程演示
找候选键
(学号,课程号)
找非主属性
(成绩,学分)
判断每个属性是否不可再分的数据项
是,符合第一范式
判断是否存在非主属性对主属性的部分依赖,若存在则说明不满足每一个非主属性完全依赖候选键,因此不符合第二范式
学分依赖于课程号,不符合第二范式
解决方案:模式分解
通过消除部分依赖和传递依赖,将SC分解为两个符合2NF和3NF的关系模式:
- SC1(学号,课程号,成绩)
- 主键:(学号,课程号)
- 函数依赖:(学号,课程号) → 成绩
- 说明:存储学生选课与成绩的关联,无冗余和异常。
- Course(课程号,学分)
- 主键:课程号
- 函数依赖:课程号 → 学分
- 说明:独立存储课程与学分的关联,避免重复存储。
第三范式
第三范式(3NF): 当且仅当关系模式R是第二范式(2NF),且R中没有非主属性传递依赖于候选键时,则称关系模式R是第三范式
思考题:学生关系(学号,姓名,系号,系名,系位置)各属性分别代表学号,姓名,所在系号,系名称,系地址。思考该关系模式会存在哪些问题(从数据冗余、更新异常、插入异常、删除异常这几个方面来考虑),解决方案是什么?
| 学号 | 姓名 | 系号 | 系名 | 系位置 |
|---|---|---|---|---|
| S01 | 张三 | D01 | 计算机系 | 1号楼 |
| S02 | 李四 | D01 | 计算机系 | 1号楼 |
| S03 | 王五 | D01 | 计算机系 | 1号楼 |
| S04 | 赵六 | D02 | 信息系 | 2号楼 |
| … | … | … | … | … |
判断第三范式流程演示
判断主键
学号
判断是否属性不可再分
符合第一范式
判断是否每一个非主属性完全依赖候选键
只有一个候选键的情况下,每一个非主属性必然是完全以来候选键的,因此符合第二范式
判断是否没有非主属性传递依赖于候选键
学号决定系号,系号决定系名和系位置;即非主属性(系名和系位置)通过非主属性(系号)传递依赖于候选键(学号)
因此不符合第三范式
解决方案:
把传递依赖的部分分割出来
- (系号,系名,系位置)
- (学生,姓名,系号)
这样就满足第三范式了
BC范式
软考只需要掌握其判断依据就可以了,考试中实际拆分项目的时候,只需要拆到第三范式就够了
BC范式(BCNF): 设R是一个关系模式,F是它的依赖集,R属于BCNF当且仅当其F中每个依赖的决定因素必定包含R的某个候选码
BC范式(BCNF)要求:
所有决定因素(左侧的X)必须是候选键,即,若存在函数依赖 X → Y,则X必须是候选键。
例:关系模式STJ(S,T,J)中,S表示学生,T表示老师,J表示课程。每一老师只教一门课程。每门课程有若干老师,某一学生选定某门课,就对应一个固定老师.这种设计是否符合BCNF范式,若不满足如何解决?
解析如下:
根据题意,学生(S)选定某门课程(J)时对应固定的老师(T),因此 (S, J) 可以唯一确定T,即**(S,J)→T**;同时,每个老师(T)只教一门课程(J),即 T→J;
列出关系式:
- T->J
- (S,J)->T
是否每个依赖的决定因素必定包含R的某个候选码 候选码应该是(S,J),T作为依赖却不包含(S,J),因此不符合BCNF范式
p.s.这种非候选键决定主属性的情况导致冗余和更新异常
解决思路: 分解为TJ表和ST表,则符合BCNF范式

例题
例题1

注意实际上第三个空是可以填BC范式的,但选项中没有BFNF可供选择
题目选项中的第四范式,4NF是特指多值函数依赖,多值函数依赖与我们平时说的函数依赖是不一样的
模式分解
保持函数依赖分解
设数据库模式ρ={R₁,R₂,…,Rₖ}是关系模式R的一个分解,F是R上的函数依赖集,ρ中每个模式Rᵢ上的FD集是Fᵢ。如果{F₁,F₂,…,Fₖ}与F是等价的(即相互逻辑蕴涵),那么称分解ρ保持FD
冗余函数依赖无需保留,如有A→B 和 B→C,则 A→C无需保留
例子:
设关系模式 R(U,F),其中:
- 属性集 U={A,B,C,D,E}
- 函数依赖集 F={A→BC,C→D,BC→E,E→A}
分解情况:
分解 ρ={R₁(ABCE),R₂(CD)} 是否保持函数依赖?
分解后保留原关系模式的情况如下:
R₁保留{A→BC,BC→E,E→A}
R₂保留{C→D}
是✅
分解 ρ={R₁(ABE),R₂(CD)} 是否保持函数依赖
分解后保留原关系模式的情况如下:
R₁无法保留{A→BC,BC→E}
否❌
例2:
设关系模式 R(U,F),其中:
- 属性集 U={A,B,C}
- 函数依赖集 F={A→B,B→C,A→C}
分解情况:
分解 ρ={R₁(A→B),R₂(B→C)} 是否保持函数依赖?A→C可以推导得出,是冗余函数依赖,因此是保持函数依赖的✅
无损分解
有损: 不能还原 ; 无损: 可以还原
无损连接分解: 指将一个关系模式分解成若干个关系模式后,通过自然连接等运算仍能还原到原来的关系模式
自然连接: 存在同名属性列,以该属性列为左侧决定因素的函数依赖保留下来了
下面表格法判断分解是否为无损分解
将一个具有函数依赖:学号->姓名 课程号->课程名,(学号,课程号)->分数的关系模式:成绩(学号,姓名,课程号,课程名,分数),分解为:成绩(学号,课程号,分数);学生(学号,姓名);课程(课程号,课程名)
初始表如下:


例1:
例:设R=ABC,F={A->B},则分解P1=(R₁(AB),R₂(AC)}与分解P2={R₁(AB),R₂(BC)}是否都为无损分解?
表格法分析如下:
P1是无损分解,P2不是无损分解
例2:
例3:
例:设R=ABC,F={A->B},则分解P1={R₁(AB),R₂(AC)}与分解p2={R₁(AB),R₂(BC)]是否都为无损分解?


关系代数
上午题考得比较频繁,2到4分分值范围
一个表格
垂直的是: 属性列,属性列的个数叫目或度,也叫数据维度
水平的是: 元组行,也叫一条记录,或一个实例
关系代数
并交差

笛卡尔积
参与笛卡尔积的两个表格可以相同可以不同
$$
笛卡尔积的属性列数 = 两个表格属性之和
$$
$$
笛卡尔积的元组行数 = 两个表格属性数量的乘积
$$

效率优化: 做自然连接和笛卡尔积的时候,为了效率,应该让双方尽可能小,这样效率才会更高
投影与选择
选择(Selection):用于从一个数据集中提取满足特定条件的记录。它帮助我们过滤出我们感兴趣的数据。
投影(Projection):用于从一个数据集中提取特定的列。它可以减少数据的维度,帮助我们只关注我们需要的信息,去掉不必要的列。
sql语句讲解:
1 | #选择,投影与sql的关系 |
选择不会改变表格结构,而笛卡尔积和投影会改变表格结构
自然连接
**自然连接(Natural Join)**是关系数据库中一种非常重要的连接操作,它用于将两个或多个表根据它们的公共属性(列)进行连接。自然连接的主要特点是自动识别两个表中相同名称的列,并根据这些列的值进行匹配
$$
自然连接的属性列数 = 两个表格属性之和 - 重复列的数量
$$
$$
自然连接的元组行数 = 同名属性列取值相等的元组行数
$$
 $$
\pi_{1,2,3,5}(\sigma_{1=4}(S1\times S2))
$$
针对S1和S2的笛卡尔积选择第1和第4列相等,然后投影1,2,3,5列
$$
\pi_{1,2,3,5}(\sigma_{1=4}(S1\times S2))
$$
针对S1和S2的笛卡尔积选择第1和第4列相等,然后投影1,2,3,5列
这个操作与自然连接是等价的,但是自然连接的性能会比笛卡尔积选择再投影的性能更优
例题1

第二空解法:
自然选择的连接可以看出来两个表中需要满足的选择条件为1=5以及3=6,还有2>7三个条件同时满足,就已经能排除到答案是B了
p.s. C选项和D选项中的带引号的7表示的不是列号,而是7这个值本身
例题2

笛卡尔积或自然选择的两方,数据量越小,效率越高
SQL语言
普通查询
| 分类 | 动词 |
|---|---|
| 数据查询 | SELECT |
| 数据定义 | CREATE、DROP、ALTER |
| 数据操纵 | INSERT、UPDATE、DELETE |
| 数据控制 | GRANT(授予权限)、REVOKE(撤销权限) |
1 | SELECT [ALL|DISTINCE]<目标表达式>[,<目标表达式>]... #选择显示列 |
例题

R和S针对2<7进行自然连接,存在的列为:
1 | A B C D E F G |
因此2<7在自然连接中的条件为 R.B<S.G
因为后面的问题中的FROM是R,S表示后面的SELECT和WHERE都是针对笛卡尔积的结果:
1 | A B C D E B C F G |
R.B<S.G并且自然连接的条件笛卡尔积中则为C选项,因为自然连接要求同名的属性相等
分组查询
注意: [GROUP BY[列名1] [HAVING<条件表达式>]]
针对分组后的结果进行过滤应该使用HAVING,而不是WHERE
| 处理类型 | 处理子类 | 示例/语法 |
|---|---|---|
| 结果排序 | 升序或降序 | ORDER BY 字段名 DESC | ASC |
| 集函数 | 统计 | COUNT([DISTINCT|ALL] <列名>) |
| 集函数 | 计算一列中值的总和 | SUM([DISTINCT|ALL] <列名>) |
| 集函数 | 计算一列值的平均值 | AVG([DISTINCT|ALL] <列名>) |
| 集函数 | 求一列值中的最大值 | MAX([DISTINCT|ALL] <列名>) |
| 集函数 | 求一列值中的最小值 | MIN([DISTINCT|ALL] <列名>) |
| 对结果分组 | 将查询结果按列值分组 | GROUP BY <列名> |
| 对分组结果筛选 | 对分组结果筛选 | HAVING <条件列表达式> |
DISTINCT表示去重
例题

第一个空分析流程
- 以供应商为核心,每个供应商可以供应多种零件,只要有一边多,则供应商分支为”多”
- 以项目为核心,每个项目可以存在多个供应商,只要有一边多,则项目分支为”多”
- 以零件为核心,每个项目多种零件,只要有一边多,则零件分支为”多”
因此,其联系关系为 *:*:*
第二个空分析:
单查三个表中的任意一个肯定都不够,只能查SP_P
第三个空分析:
- 首先是针对分组进行过滤,因此必然是A或C
- 其次,由于一个供应商的多个同名项目,有不同的零件,因此需要对同名项目进行去重
权限控制
软考考得不多,主要是了解关键字
1 | #授权语句 |
例题

并发控制
事务的特性
ACID
原子性(Atomicity): 事务是原子性的,要么做,要么都不做
实现是基于回滚操作机制
一致性(Consistency): 事务执行的结果必须保证数据库从一个一致性状态变到另一个一致性状态
隔离性(Isolation): 事务相互隔离,当多个事务并发执行时,任一事务的更新操作直到其成功提交的整个过程,对其他事务都是不可见的
持久性(Durability): 一旦事务成功提交,即使数据库崩溃,其对数据库的更新操作也永久有效
因为数据库是先写日志,再写数据的!当数据库崩溃的时候,重启数据库的时候会扫描日志,对一切拥有COMMIT提交标志的事务,放到REDO队列中,重新进行这些操作

事务相互之间是并发的,因此需要考虑并发控制
并发控制
事务在并发中产生的问题盘点:
丢失更新
两个以上的事务对同一个数据做了修改,前一个修改会被后一个修改覆盖掉(多次写回)
不可重复读问题
验算前,其他事务对数据进行了修改,导致验算不正确
读”脏”数据
回滚前,被其他事务读取到了无效的中间数据

针对并发控制产生的问题,可以使用封锁协议进行处理
封锁协议
封锁协议是数据库管理系统(DBMS)中用于控制并发事务访问数据资源的规则集合,旨在解决并发操作中的数据不一致问题(如丢失修改、脏读、不可重复读、幻读)
封锁协议非常灵活,并且有很多种,但是在软考中只涉及到S锁和X锁
主要有两类锁
共享锁/S锁/读锁:
若事务T对数据对象A加上S锁,其他事务只能对A再加S锁,不能再对A添加X锁
排他锁/独占锁/X锁/写锁:
若事务T对数据对象A加上X锁,其他事务不能再对A添加任意锁
存在加锁的情况就有可能存在死锁问题

基本锁类型
共享锁(S锁/读锁)
允许多事务同时读取同一数据,但禁止写入操作。适用于高并发读场景(如报表查询)
排他锁(X锁/写锁)
仅允许单事务读写数据,其他事务无法加任何锁。用于数据修改操作(如账户转账)
意向锁(IS/IX锁)
表级锁,用于快速判断表中是否存在行级锁。例如,事务对某行加X锁前需先对表加IX锁,避免逐行检测锁冲突
封锁协议分级
两阶段封锁协议(2PL)
扩展阶段:事务仅可申请锁,不可释放。
收缩阶段:事务仅可释放锁,不可申请。
确保可串行化调度,但可能导致死锁
严格两阶段封锁协议(S2PL)
所有锁在事务提交后统一释放,解决脏读和不可重复读问题(如MySQL的InnoDB引擎默认使用)
多版本并发控制(MVCC)
通过维护数据快照实现无锁读(如PostgreSQL、Oracle),减少锁争用,提高高并发场景性能
封锁粒度选择
- 行级锁:细粒度锁,并发度高但管理开销大(如电商库存扣减)
- 表级锁:粗粒度锁,管理简单但并发度低(如全表统计更新)
- 页级锁:折中方案(如SQL Server)
| 数据库 | 锁机制特性 |
|---|---|
| MySQL | InnoDB支持行级锁、间隙锁;MyISAM仅表级锁 |
| PostgreSQL | 基于MVCC实现无锁读,行级写锁兼容快照隔离 |
| Oracle | 多版本一致性读(MVCR)+行级锁,支持自动锁升级 |
封锁协议是数据库并发控制的基石,需结合业务场景选择锁类型、粒度和隔离级别。实际开发中应优先考虑MVCC、行级锁等机制平衡性能与一致性,并通过事务设计、死锁预防策略规避风险。未来随着分布式数据库普及,智能锁管理和跨节点一致性协议(如Raft)将成为关键技术方向
数据库设计
15分
数据库设计过程


数据库设计例题
例1
补充E-R图题如下:

例2

a. 部门号
b. 客户号,单位名称
c. 申请号,客户号
d. 身份证号,入住时间
例3(精华)

简要分析上图如下
(5)说明了顾客和商品之间的订单关系是”多对多”
(6)说明了代购员和订单之间的代购关系是”多对多”
(7)正是我们需要的概念模型设计图补充条件


【问题1】(3分)
报据问题描述,补充概念模型设计图的实体联系图。
根据图1第7条数据,题目没有描述具体的多元关系,因此需要我们自己猜测情况,补充如下:

【问题2】(6分)
补充逻辑结构设计结果中的(a)、(b)两处空缺。
a空缺:
由于顾客和商品的关系是多对多,因此应该归并商品和顾客的主键,分别是编号(顾客编号),条码
因为这两项不存在,因此a空缺至少应该填这两项
b空缺:
根据第6条可知:多名代购员可以从多个超市采购一个订单内的某部分商品,因此商品编码也是必须的
由于代购针对的是订单内部的商品,而不是针对订单
订单ID和支付凭证编号都可以作为订单的主键
因此答案是 订单ID和商品条码 或 支付凭证编号和商品编码
有订单ID优先使用订单ID
【问题3】(6分)
为方便顾客,允许顾客在系统中保存多组收货地址。请根据此需求,
增加“顾客地址”弱实体,对概念模型设计图进行补充,并修改“运送”关系模式。
此题相对困难,可放弃
因为如果允许一个顾客有多个顾客地址,那么运送关系中就没办法只靠找到顾客来确定顾客地址了,而是需要在运送关系中明确顾客地址是哪里,才能送到
因此对概念模型设计图进行补充如下:

例4(精华)
对应4.3.3
暂未看,待补充
事务隔离相关
隔离级别
用来解决并发事务所产生的一些问题
当不设置事务隔离级别将使用数据库的默认事务隔离级别
MVCC
多版本并发控制(Multiversion Concurrency Control)
事务隔离级别的无锁的实现方式
用于提高事务的并发性能
MVCC如何解决并发问题?
读写不阻塞
MVCC 的核心是通过维护数据的多个版本,让读操作和写操作互不阻塞
- 读操作:事务会读取其启动时的快照版本,即使其他事务正在修改同一数据,也不会影响当前事务的读取结果
- 写操作:修改数据时会创建新版本,旧版本对其他事务仍然可见,直到旧版本被清理
解决脏读、不可重复读
- 默认的
READ COMMITTED隔离级别下,事务只能看到已提交的数据,避免了脏读。- 在
REPEATABLE READ或SERIALIZABLE隔离级别下,事务会看到启动时的快照,解决了不可重复读问题写-写冲突的处理
PostgreSQL 的 MVCC 会隐式处理写-写冲突:如果两个事务同时修改同一行,后提交的事务会失败并抛出
SerializationFailure异常,需由应用层重试或处理
MVCC 的局限性
尽管 MVCC 解决了大部分并发问题,但在以下场景仍需开发者主动处理
高竞争写操作(如库存扣减)
MVCC 默认允许后提交的事务覆盖前事务的修改,可能导致数据逻辑不一致(如超卖)。此时需结合 乐观锁(版本检查) 或 悲观锁(
SELECT FOR UPDATE) 来保证业务逻辑的正确性幻读问题
在
REPEATABLE READ隔离级别下,PostgreSQL 通过快照避免了幻读,但SERIALIZABLE隔离级别可能因检测到“谓词冲突”而回滚事务,需应用层处理重试事务隔离级别的选择
默认的
READ COMMITTED隔离级别无法完全避免不可重复读,需根据业务需求调整隔离级别
实际开发中的综合方案
默认依赖MVCC
对于大多数场景(如读多写少),MVCC 已足够解决并发问题。例如,多个程序同时查询数据不会互相干扰
补充乐观锁
在实体类中添加版本字段(如
Version),通过 EF Core 的并发令牌机制(IsConcurrencyToken())主动检测版本冲突,并处理DbUpdateConcurrencyException必要时使用悲观锁
在高竞争写场景(如抢购),使用
SELECT ... FOR UPDATE锁定目标行,确保同一时间只有一个事务能修改数据
只需正常配置 数据库 ,无需显式启用 MVCC 就可以满足基本需求
但是有需要注意的边界情况
写冲突的显式处理
当多个程序同事修改同一行时,后提交的事务会被中止.此时需要通过重试策略或乐观锁(版本字段)主动处理冲突
1
2
3
4
5
6
7
8try
{
await context.SaveChangesAsync();
}
catch (DbUpdateConcurrencyException ex)
{
// 合并数据或提示用户重试
}场景 推荐策略 注意事项 简单字段更新 基础重试循环 + Reload 避免业务逻辑复杂化 多字段表单提交 数据合并策略 需明确合并规则(如保留用户输入字段) 高并发写操作(如库存) 悲观锁( SELECT FOR UPDATE)显式锁定行,牺牲部分性能换取强一致性 微服务/分布式系统 Polly 重试 / 指数退避 结合熔断机制(Circuit Breaker) 高隔离级别的需求
如果需要 可重复读(Repeatable Read) 或 串行化(Serializable) 隔离级别,需显式配置事务
1
await using var transaction = await context.Database.BeginTransactionAsync(IsolationLevel.RepeatableRead);
长事务的性能影响
MVCC 可能导致旧版本数据堆积,需定期运行
VACUUM命令清理过期版本(PostgreSQL 自动执行,但可手动优化)
oracle
Oracle是殷墟(yīn Xu)出土的甲骨文(oracle bone inscriptions)的英文翻译的第一个单词。
Oracle公司成立于1977年,总部位于美国加州;
Oracle数据库是Oracle(中文名称叫甲骨文)公司的核心产品,Oracle数据库是一个适合于大中型企业的数据库管理系统。在所有的数据库管理系统中(比如:微软的SQL Server,IBM的DB2等),Oracle的主要用户涉及面非常广, 包括: 银行、电信、移动通信、航空、保险、金融、电子商务和跨国公司等。
Oracle数据库的一些版本有:Oracle7、Oracle8i、Oracle9i,Oracle10g到Oracle11g,Oracle12c, 各个版本之间的操作存在一定的差别,但是操作oracle数据库都使用的是标准的SQL语句,因此对于各个版本的差别不大。
2008年1月16日 收购bea,目的是为了得到weblogic(web服务器的框架,免费的对应的tomcat)。
2008年1月16日 sun公司收购了mysql 。
2009年4月20日 oracle收购了sun 。
Oracle服务器:是一个数据管理系统(RDBMS),它提供开放的, 全面的, 近乎完整的信息管理。由1个数据库和一个(或多个)实例(可以简单理解成就是进程)组成。数据库位于硬盘上,实例位于内存中。
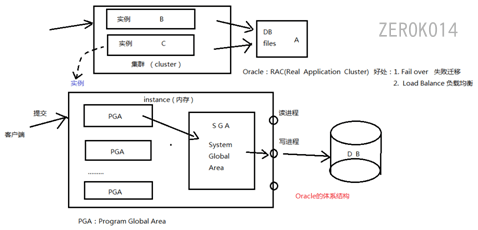
oracle非常耗费内存
表空间和数据文件
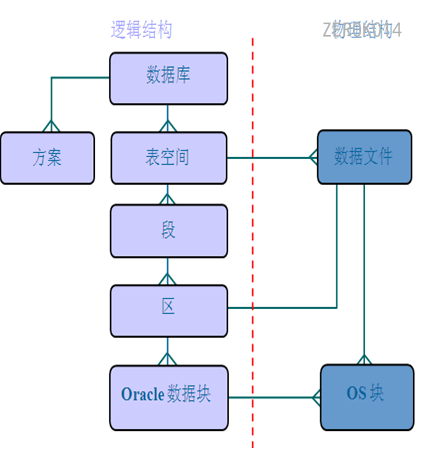
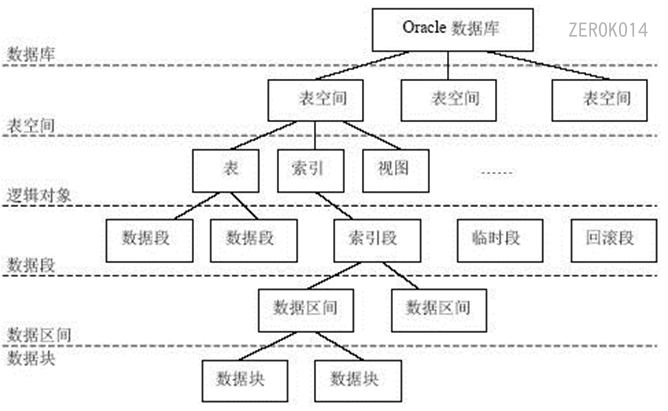
逻辑概念:表空间是由多个数据文件组成,位于实例上,在内存中。
物理概念:数据文件,在磁盘上(/home/oracle_11/app/oradata/orcl目录中的.DBF文件);
一个表空间包含一个或者多个数据文件。

段存在于表空间中,段是区的集合,区是数据块的集合,数据块会被映射到磁盘块。
DBA
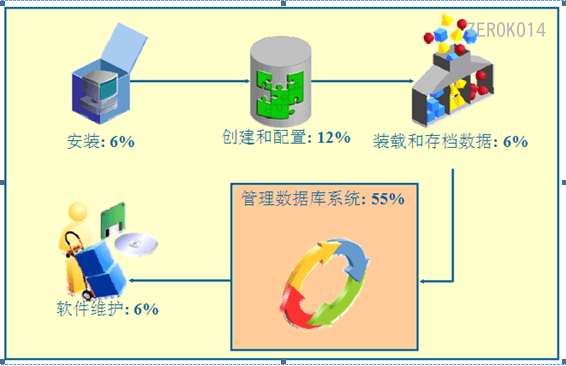
数据库管理员(Database Administrator,简称DBA),是从事管理和维护数据库管理系统(DBMS)的相关工作人员的统称,属于运维工程师的一个分支,主要负责业务数据库从设计、测试到部署交付的全生命周期管理。DBA的核心目标是保证数据库管理系统的稳定性、安全性、完整性和高性能。从时间开销上看:安装占用6%,创建和配置占用12%,装载和存档数据占6%, 软件维护占6%,管理数据库系统占55%,可见,管理数据库系统占用了大部分的时间开销。
启动数据库服务
Windows
windows下创建数据库参考此处(注意,安装过程中主机名不要修改,默认的是对的,吃过亏了)
Windows启动oracle数据库服务:
启动服务:services.msc,找到下列两个服务,并启动。
OracleServiceORCL: oracle数据库服务系统home1TNSListene: 监听服务,用于远程连接的侦听
注意:若把数据库默认设置为自启动,则开机时间会延长。
Linux
Linux启动oracle数据库服务步骤(oracle数据库系统安装到linux系统上)
- 执行
sqlplus / as sysdba或sqlplus sys/sys as sysdba进入到命令行界面 - 执行
startup启动数据库服务 - 执行
exit退出sqlplus命令行界面 - 执行
lsnrctl start启动监听服务
注意:通过远程客户端连接oracle服务端必须要启动监听服务,否则客户端连接不上。
sqlplus命令行界面下还可以使用 shutdown immeidate停止数据库服务
容器数据库
容器数据库(CDB)和可插拔数据库(PDB)是Oracle 12C引入的一种特性,它允许在CDB容器数据库中创建并维护多个数据库。这个特性的优点之一是可以在一个数据库服务器上创建多个独立的数据库,每个PDB在CDB中是相互独立存在的。这样可以更有效地利用服务器资源,避免浪费。此外,CDB根容器数据库的主要作用就是容纳所有相关的PDB元数据,以及在CDB中对现有PDB进行管理
MYSQL没有容器数据库的概念
ROOT:ROOT容器数据库,是CDB环境中的根数据库,在根数据库中含有主数据字典视图,其中包含了与ROOT容器有关的元数据和CDB中包含的所有PDB信息,在CDB环境中被标识为**CDB$ROOT**,每个CDB环境中只能有一个ROOT容器数据库。PDB SEED:PDB SEED为PDB的种子,其中提供了数据文件,在PDB环境中被标识为PDB$SEED,是创建PDB的模板,可以连接PDB$SEED但是不能执行任何事务,因为PDB$SEED是只读的,不可修改。PDBS:PDBS数据库,在CDB环境中每个PDB都是独立存在的,与传统ORACLE数据库无差别,每个PDB拥有自己的数据文件和OBJECTS,唯一的区别就是PDB可以插入到CDB中,以及从CDB中拔出。当用户连接到PDB时不会感觉到根容器和其他PDB的存在。
容器数据库基本操作
show pdbs;查看当前数据库下有哪些PDBshow con_name;查看当前连接的是哪个数据库alter session set container=数据库名;切换数据库- 等等点击跳转详解
登录数据库服务
本机登陆
普通用户身份登陆
sqlplus 用户名/密码,如sqlplus scott/tiger以管理员身份登陆
sqlplus / as sysdba(此处不用输入密码,在安装的时候已经输入密码)sqlplus sys/sys as sysdba
oracle自带两个用户
- **
SYS**用户是Oracle数据库的超级用户,它拥有最高权限,可以执行任何操作。SYS用户拥有所有的数据字典表和视图,这些对象都存储在SYS模式下。通常情况下,不建议使用SYS用户进行日常操作,因为它拥有非常高的权限,可能会对数据库造成不可逆的影响。 - **
SYSTEM**用户也是一个具有高权限的用户,它主要用于执行数据库管理任务。与SYS用户不同的是,SYSTEM用户并不拥有所有的数据字典表和视图,它只能访问那些授权给它的对象。通常情况下,可以使用SYSTEM用户来执行一些日常的数据库管理任务。
远程登陆
远程通过网络登陆数据库需要安装oracle客户端软件,并进行配置才能使用,可通过使用net manager进行配置,配置完成之后可以使用连接字符串进行登陆,连接字符串中包含了数据库服务的IP地址和端口,以及实例名。
注意:安装oracle客户端的时候,安装路径中不能出现中文和空格,安装的时候选择管理员模式。
普通用户登陆
sqlplus 用户名/密码@连接字符串,如sqlplus scott/tiger@oracle_orcl管理员用户登陆
sqlplus sys/sys@oracle_orcl as sysdba
此外:还可以执行: sqlplus scott/tiger@//IP地址/实例名 进行登陆。
使用scott用户或者sys用户登陆完之后,可以使用show user测试一下,如果显示用户名就表明已经登陆成功了,或者是执行select * from tab;进行一次查询, 有结果显示就表名已经登陆成功了.
相关命令
解锁用户:
alter user scott account unlock(管理员身份登陆,给scott用户解锁。用户默认锁定)锁定用户:
alter user scott account lock,(必须用管理员用户登陆)修改用户密码:
alter user scott identified by 新密码(管理员身份登陆,给scott用户修改密码)修改用户密码也可以直接
password scott 新密码(scott用户本身修改自身密码的话可以省略scott)查看当前语言环境:
select userenv('language') from dual;
加锁后,对应加锁的用户就不能登录了,解锁后该用户才能登录
oracle创建案例脚本
1 | -- 01 创建表空间 |
sql和sqlplus
sql和sqlplus的区别:
- SQL是语言,关键字不能缩写。
- sqlplus是oracle提供的工具,可在里面执行SQL语句,它配有自己的命令(ed、c、set、col、spool) 特点是缩写关键字。
sqlplus常用命令
显示当前用户:
SQL> show user;查看当前用户下的表:
SQL> select * from tab; tab: 数据字典(记录数据库和应用程序源数据的目录),包含当前用户下的表。
查看员工表的结构:
SQL> desc emp;(desc → description 描述)设置行宽:
set linesize 120;设置页面:
set pagesize 100;或者将上述两行写入如下两个配置文件,可永久设置:
C:\app\Administrator\product\11.2.0\client_1\sqlplus\admin\glogin.sqlC:\app\Administrator\product\11.2.0\dbhome_1\sqlplus\admin\glogin.sql
设置员工名列宽:
col ename for a20(a表示字符串)设置薪水列为4位数子:
col sal for 9999(一个9表示一位数字)若想将显示结果保存到文件中
1
2
3spool d:\result.txt;
select * from emp;
spool off;ed(或者edit)命令打开文件来编写sql语句,注意, sql语句末尾不要加
;, 然后换行加上/表示结束修改日期格式,日期格式默认为
DD-MON-RR,修改日期格式方式为:alter session set NLS_DATE_FORMAT = 'yyyy-mm-dd hh24:mi:ss';查看当前会话使用的日期格式 :select * from v$nls_parameters;开关显示SQL的执行时间:
set timing on/off/表示重复刚刚执行过的sql语句.start sql脚本路径或@ sql脚本路径可以运行sql脚本set feedback on/off开关回显
管理员创建用户
create user 用户名 identified by 密码; 创建用户(刚创建的用户连连接数据库的权限都没有)
grant connect ,resource to 用户名; 一般都要赋予最基本的连接数据库权限connect和访问资源的权限 resource
赋予对USERS表空间的权限ALTER USER 数据库用户名 QUOTA UNLIMITED ON USERS ;
SQL语言的类型
- 数据库中,称呼 增 删 改 查,为DML语句。(Data Manipulation Language 数据操纵
语言),就是指代:insert、update、delete、select这四个操作。 - DDL语句。(Data Definition Language 数据定义语言)。
如:truncate table(截断/清空一张表)create table(表)、create view(视图)、create index(索引)、create sequence(序列)、create synonym(同义词)、alter table、drop table。 - DCL语句。DCL(Data Control Language数据控制语言)如:
commit(提交)、rollback(回滚)
数据库对象
数据库对象共有12个,分别是: 表,视图,索引,序列,同义词,存储过程,存储函数,触发器,包,包体,数据库链路(datalink),快照
常见的数据库对象
表
基本的数据存储集合,由行和列组成。表名和列名遵循如下命名规则:
- 必须以字母开头
- 必须在 1–30 个字符之间
- 必须只能包含 A–Z, a–z, 0–9, _, $, 和#
- 必须不能和用户定义的其他对象重名
- 必须不能是Oracle 的保留字
- Oracle默认存储是都存为大写
- 数据库名只能是1~8位, datalink可以是128位, 和其他一些特殊字符
创建表
关键词 Create Table
创建一张表必须具备:1. Create Table的权限 2. 存储空间。
1 | create table test1 (tid number, tname varchar2(20), hiredate date default sysdate); |
default的作用是, 当向表中插入数据的时候, 没有指定时间的时候, 使用默认值sysdate。
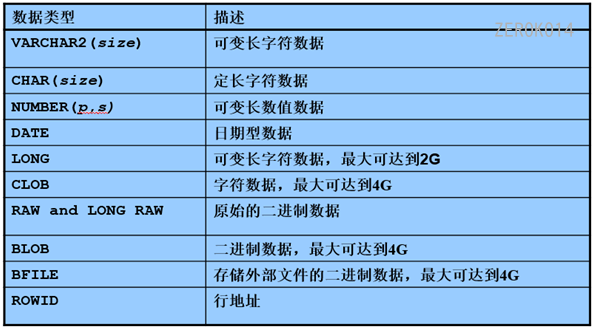
创建表时,列所使用的数据类型:
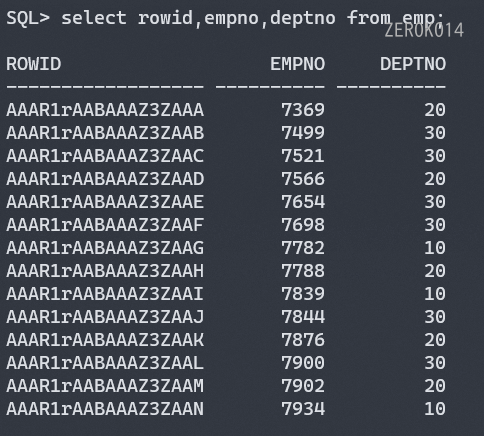
varchar2(size)中的size表示可变长的最大值number(p,s)中的p表示数值的总长度,s表示小数点长度(6200.00,p为6,s为2)rowid:行地址 ——伪列select rowid, empno, deptno from emp;
看到该列存储的是一系列的地址(指针), 创建索引用.
[ [注意] ] create table as select子句的格式中,后面select后的表达式要取别名(语法要求)
修改表
关键词 ALTER TABLE
追加一列:
add向test1表中加入新列 image 类型是blobalter table test1 add image blob;修改一列:
modify将tname列的大小由20→40.alter table test1 modify tname varchar2(40);删除一列:
dropcolumn将刚加入的新列image删除.alter table test1 dropcolumn image;重命名一列:
renamecolumn将列tname重命名为username.alter table test1 renamecolumn tname to username;
注意: 若是修改表的字段的长度, 若是增加长度没有问题, 若是减少字段的长度, 有可能会报错.
修改表名: rename 原表名 to 新表名
删除表
关键词 drop table
当表被删除:
- 数据和结构都被删除
- 所有正在运行的相关事物被提交
- 所有相关索引被删除
DROP TABLE语句不能回滚,但是可以闪回
1 | select * from tab; 查看当前用户下有哪些表, 拷贝保存表名。 |
Oracle的回收站
- 查看回收站:
show recyclebin(sqlplus 命令)那个复杂的命名即是testsp在回收站中的名字。 - 清空回收站:
purge recyclebin - 将表从回收站闪回
flashback table t2 to before drop;
注意:并不是所有的用户都有“回收站”,对于没有回收站的用户(管理员)来说,删除操作是不可逆的.
两种删除方式
drop table tbl;删除的表可以闪回drop table tbl purge;purge的作用:删除不经过回收站,删除的表不可以闪回
表的约束
表的约束有5种: (关键词)
- 检查 值是否符合预设的规则(比如性别只能男或女) (
check) - 非空 ** (
not null**) - 唯一 不能重复 (
unique) - 主键 非空+唯一 (
primary key) - 外键(foreign key) 取值必须在另外一个表中存在 (
references)
[注意] 设置外键的目标必须是父表的主键.
修改表增加主键约束
1 | alter table dept_bak add constraint pk_dept_bak primary key (deptno); |
create table中设置约束:
1 | create table student |
上述代码中,deptno number constraint student_FK references dept 设置了删除了dept表中的某个deptno后,student表中的所有那个值的deptno的全部设置空.如果不加 ON DELETE SET NULL则删除dept表中的值会报错,除非删除行的deptno值在student表中不存在.
外键的删除相关
cascade 级联删除,主表记录删除的时候,子表引用了该字段的数据跟着删除
drop table dept_bak cascade constraints;set null 设置为null,主表删除的时候,子表该字段设为null
默认方式 主表删除的时候,如果子表引用了该字段的数据,不能删除,要先删子表
通过references定义外键的时候可以用如下参数
on delete cascadeon delete set null(多数情况下使用这种方法)
check检查性约束
格式 check(条件)
违反检查约束插入报错: ORA-02290:违反检查约束条件
定义约束时没有显式指定名字,系统会默认给一个名称.建议创建约束的时候自定义一个含义清晰的约束名
constraint: 使用该关键字,来给约束起别名。
查看指定表的约束:
1 | select constraint_name, constraint_Type, search_condition from user_constraints where table_name='STUDENT'; |
注意:上面STUDENT位置的表名必须大写
视图
视图是一种常见数据库对象, 它是从表中抽出的逻辑上相关的数据集合。
- 视图基于表
- 视图是逻辑概念
- 视图本身没有数据
使用视图的好处:
- 可以简化查询,将视图看做是表的复杂的SQL一种封装
- 可以限制用户对某些数据的访问
[注意] 建议不要通过视图去修改表的数据,即使不是只读视图
视图相关操作
创建视图
create view 视图名 as sql查询语句;创建视图需要
create view权限创建只读视图
create view 视图名 as sql查询语句 with read only;with check option要符合视图创建时的条件才能修改原数据创建或更新视图
create or replace view 视图名 as 查询语句;(replace不能单独使用)查看所有已创建的视图
select view_name from user_views;删除视图
drop view 视图名;
创建视图需要 create view 权限,添加权限步骤:
- 使用管理员登陆:
sqlplus / as sysdba - 给scott用户增加权限
grant create view to scott;(revoke关键词可以撤销权限)
视图中使用DML的规定:
一:
当视图定义中包含以下元素之一时不能使用delete:
组函数
GROUP BY 子句
DISTINCT 关键字
ROWNUM 伪列
二:
当视图定义中包含以下元素之一时不能使用update :
组函数
GROUP BY子句
DISTINCT 关键字
ROWNUM 伪列
列的定义为表达式
三:
当视图定义中包含以下元素之一时不能使用insert :
组函数
GROUP BY 子句
DISTINCT 关键字
ROWNUM 伪列
列的定义为表达式
表中非空的列在视图定义中未包括
总结一句话:不通过视图做insert、update、delete操作。因为视图提供的目的就是为了简化查询。
索引
索引,相当于书的目录,提高数据检索速度。提高效率(视图不可以提高效率)
- 一种独立于表的模式对象, 可以存储在与表不同的磁盘或表空间中
- 索引被删除或损坏, 不会对表产生影响, 其影响的只是查询的速度
- 索引一旦建立, Oracle 管理系统会对其进行自动维护, 而且由 Oracle 管理系统决定何时使用索引. 用户不用在查询语句中指定使用哪个索引
- 在删除一个表时, 所有基于该表的索引会自动被删除
- 通过指针加速 Oracle 服务器的查询速度
- 通过快速定位数据的方法,减少磁盘 I/O
使用索引注意点: 使用索引的列值的分布要广泛,重复的概率非常低,唯一最好.
索引的原理:若一个表有索引,则oracle会在内部维护一个索引表,查询的时候要使用索引的列,优先会到索引表中去查,通过索引的列找到对应的行地址,找到行地址就可以找到数据.
索引表中的列的值是有序的.
使用主键查询数据最快速,因为主键本身就是“唯一索引”,所以检索比较快
Oracle的数据库中,索引有 B树索引(默认)和位图索引两种。
推荐创建索引的三种情况:
- 列中数据值分布范围很广
- 列经常在 WHERE 子句或连接条件中出现
- 表经常被访问而且数据量很大, 访问的数据大概占数据总量的2%到4%
下列情况不要创建索引
- 表很小
- 列不经常作为连接条件或出现在WHERE子句中
- 查询的数据大于2%到4%
- 表经常更新
对索引的理解可以理解为: 系统自动维护的一张顺序表加快了他查询的速度.
索引的操作
查看所有已创建的索引
select index_name from user_indexes;创建索引
create index 索引名 on 表名(列名1,列名2…);创键唯一索引
create unique index 索引名 on 表名(列名1,列名2…);(唯一索引要求列值不重复)删除索引
drop index 索引名;
索引的种类
未完待续
序列
可以理解成数组:默认,从[1]开始,长度[20] [1, 2, 3, 4, 5, 6, …, 20] 在内存中。
由于序列是被保存在内存中,访问内存的速率要高于访问硬盘的速率。所以序列可以提高效率。
序列的用处:主要用于插入主键,并保证他的非空和唯一性
序列的操作
- 创建序列
create sequence 序列名; - 删除序列
drop sequence 序列名; - 显示所有已创建序列
select sequence_name from user_sequences;
序列的使用
- 初始状态下:指针*指向1前面的位置。欲取出第一个值,应该将指针向后移动。每取出一个值指针都向后移。
- 常常用序列来指定表中的主键。
创建序列的完整格式
1 | CREATE SEQUENCE sequence |
序列的两个属性
currval当前值nextval下一个值
NextVal 必须在CurrVal之前被指定。因为初始状态下,CurrVal指向1前面的位置,无值
对于新创建的序列使用select myseq.currval from dual; 得到出错。
但select myseq.nextval from dual; 可以得到序列的第一值1.
此时再执行select myseq.currval from dual; currval的值也得到1
只有nextval取完会向后移动,使用currval不会移动。
使用时按如下方式插入序列值
insert into tableA values(myseq.nextval, &name)
修改序列:
必须是序列的拥有者或对序列有 ALTER 权限
只有将来的序列值会被改变
改变序列的初始值只能通过删除序列之后重建序列的方法实现
使用序列需要注意的问题
序列是公有对象,所以多张表同时使用序列,会造成主键不连续。
回滚也可能造成主键不连续。
如:多次调用insert操作使用序列创建主键。但是当执行了rollback后再次使用insert借助序列创建主键的时候,nextval不会随着回滚操作回退。
掉电等原因,也可能造成不连续。由于代表序列的数组保存在内存中,断电的时候内存的内容丢失。恢复供电时候,序列直接从21开始。
插入失败的情况,但序列的值已经取了,此时的情况也会造成主键不连续
同义词
同义词就是指表的别名。
使用场景
scott用户想访问hr用户下的表employees。默认是不能访问的。需要hr用户为scott用户授权.
sqplus hr/11或conn hr/11(已登录界面,切换登陆)hr用户为scott用户开放了employees表的查询权限。
授权 grant select on employees to scott;
这时scott用户就可以使用select语句,来查询hr用户下的employees表的信息了。
select count(*) from hr.employees;(若用户名叫zhangsanfeng则zhangsanfeng.employees)hr.employees名字过长,为了方便操作,scott用户为它重设别名(同义词):
create synonym hremp for hr.employees;为hr.employees创建了同义词。
创建同义词需要权限:管理员添加设置同义词权限操作如下:
conn / as sysdbagrant create synonym to scott;select count(*) from hremp;使用同义词进行表查询操作。
同义词、视图等用法在数据保密要求较高的机构使用广泛,如银行机构。好处是既不影响对数据的操作,同时又能保证数据的安全。
同义词的操作
- 创建同义词
create synonym 同义词名(想设置的别名) fot 表名 - 删除同义词
drop synonym 同义词名; - 查询所有已经创建的同义词
select synonym_name from user_synonyms;
sql插入相关
关键字: insert into
格式如下
1 | INSERT INTO table [(column [, column...])] |
案例
插入全部列
insert into dept values(51,'51name','51loc');插入部分列(没有写出的列自动填NULL)
insert into dept(deptno,dname) values(55,'55name');&符号的使用 (使用&会让用户输入值)
insert into dept(deptno,dname,loc) values(&t1,&t2,&t3);
&符号可以用于所有DML语句中供用户输入,并不仅仅是插入语句.
批处理
拷贝表结构(不拷贝数据) 通过
where 1=2这个必定错条件不让数据拷贝过去create table tname_YYYY_MM_DD as select * from tname_xxxxx where 1=2;(as不能省略)拷贝表(拷贝数据)
create table tname_YYYY_MM_DD as select * from tname_xxxxx;(as不能省略)批量插入
insert into tname_bak select * from tname where .....;
sql修改相关
关键词 : update
格式: update 表名 set col=值 where condtion
对于更新操作来说,一般会有一个“where”条件,如果没有这限制条件,更新的就是整张表[危险]。
案例 : update emp10 set sal=4000, comm=300 where ename = 'CLARK';
sql删除相关
关键词 : delete
格式: delete from 表名 where condtion
注意: 如不加“where”会将整张表的数据删除。[危险]
from关键字在Oracle中可以省略不写,但MySQL中不可以;
但在使用的时候建议还是加上from.
案例: delete from emp10 where empno=7782;
truncate table dept_0915 也可以清空一张表,但留下表结构
truncate和delete的区别
- delete 逐条删除表“内容”,truncate 先摧毁表再重建。
(由于delete使用频繁,Oracle对delete优化后delete快于truncate) truncate不能加where条件,只能整张表删除 delete是DML语句,truncate是DDL语句。
DML语句可以闪回(flashback),DDL语句不可以闪回。
(闪回:做错了一个操作并且commit了,对应的撤销行为。了解)- 由于delete是逐条操作数据,所以delete会产生碎片,truncate不会产生碎片。
(同样是由于Oracle对delete进行了优化,让delete不产生碎片)。
两个数据之间的数据被删除,删除的数据——碎片,整理碎片,数据连续,行移动 - delete不会释放空间,truncate 会释放空间
用delete删除一张10M的表,空间不会释放。而truncate会。所以当确定表不再使用,应truncate - delete可以回滚rollback, truncate不可以回滚rollback。
sql查询相关
基本select语句
下面所有说法均以此图为案例
1 | Select语句的整体形式: |
p.s. oracle中sql关键字不区分大小写
语法格式为:SELECT *|{[DISTINCT] column|expression [alias],...}FROM table;
字符和日期要包含在单引号中 转义单引号本身使用两个单引号来完成转义
去重
DISTINCT表示去重
查看不同部门的不同工种
1 | select distinct detpno,job from emp; |
distinct的作用范围是作用于后面出现的所有的列名和表达式. (有别于升降序是针对单个最近的列名)
上面的例句中,不会出现重复的[detpno和job的组合].
表达式
select后可以接列名或表达式
1 | select empno,ename,sal,comm,sal*12 年薪,sal*12+nvl 年收入 from emp; |
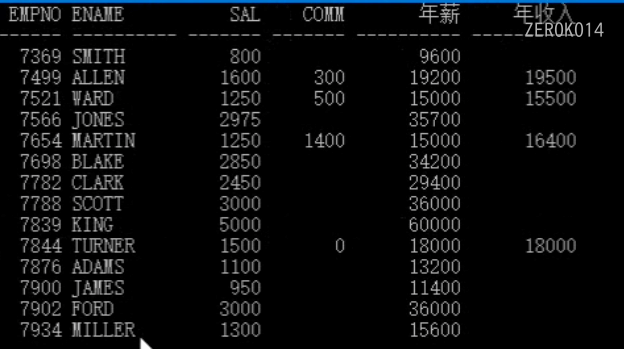
包含NULL值的表达式都返回为空,因此所有COMM为空的,年收入也为空
解决方案如下:
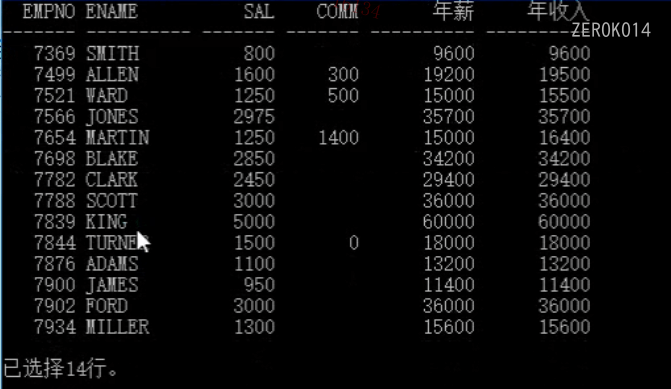
1 | select empno,ename,sal,comm,sal*12 年薪,sal*12+nvl(comm,0) 年收入 from emp; |
nvl(comm,0)表示nvl如果comm为空,则当成0处理 滤空函数参考
别名
select后接的列名或表达式或from后接的表名(多表查询)可以起别名 关键词: as
1 | select empno,ename,sal as 工资,comm 奖金,sal*12 "年 薪" from emp; |
注意:
- as可以省略
- 如果别名中间有空格,需要使用
""引起来(不加双引号,英语别名统一显示为大写)
别名不能在where中直接替代表达式和列名使用.
过滤
使用关键词 where 过滤出需要的数据行
比较运算符
1 | = 等于(不是==) > 大于 |
集合运算符
1 | in:在集合中 not in 不在集合中 |
模糊查找
1 | like:模糊查询 //%匹配任意多个字符, _匹配一个字符, 使用escape表示转义字符(下面案例有使用方式),转义单引号本身使用两个单引号来完成转义 |
逻辑运算
1 | AND 逻辑并 (优先级依次往下) |
SQL优化:SQL在解析where的时候,是从右至左解析的。
所以:
and时应该将易假的值放在右侧;or时应该将易真的值放在右侧.
案例
1 | select * from emp where ename = 'KING'; |
[重点] escape后接的字符表示他是转义字符
注意:表中的列的值是区分大小写的,但关键词不区分大小写
排序
关键词: order by
基本格式: select ... from ... where condition order by colname|alias|expr(表达式)|number(序号) (序号表示select后面出现的次序,从1开始)
ORDER BY子句在SELECT语句的最末尾, 是对select查询的最后的结果进行排序.
使用 ORDER BY 子句排序
• ASC(ascend): 升序。默认采用升序方式。
• DESC(descend): 降序
1 | //员工信息按入职日期先后排序 |
[注意] NULL在排序中表现为无穷大 可以使用nulls last使null的信息放到最后.
多元素排序 : 对多个元素进行排序时,优先排序第一个元素,仅在第一个元素相同时对第二个元素进行排序,以此类推.
分组
分组数据使用**group by**关键字. 可以配合分组函数使用
$$
select\ \ …,count()\ \ from\ \ emp \ \ where\ \ …\ \ group\ \ by\ \ …
$$
按照group by 后给定的表达式,将from后面的table进行分组。针对每一组,使用组函数, 即先分组, 再分组统计.(where过滤部分数据可写可不写)
[ [注意] ] select后面存在没有出现在分组函数中的列名,一定要出现在group by子句中 ,不然会报错.(常数可以不出现在group by子句中)
因为分组数据会限制行数,如果select出现了别的列名,那么这一组的别的列名的值会出现多个,但只能显示一行,显然就冲突了.
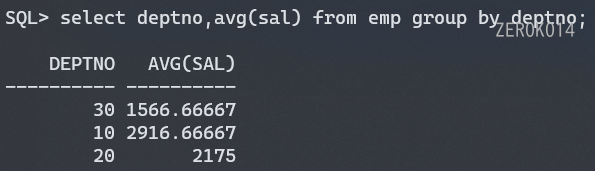
案例: 统计各个部门的平均工资
1 | select deptno,avg(sal) from emp group by deptno; |
统计各个部分不同工种的平均工资
1 | select deptno, job, avg(sal) from emp group by deptno, job; |
按照deptno, job的组合来分组.

分组函数过滤
只有使用关键词 **having**才能对分组函数进行过滤.(不能用where)
[注意]
- having必须配合group by使用 不能单独存在
- having后面不能使用别名(where可以),可以使用函数
- 不能在where中使用组函数,可以在having中使用组函数
p.s.分组的情况下,having和where均可以对非分组函数进行过滤,下面两句效果一致:
1 | select deptno,avg(sal) from emp where deptno!=10 group by deptno; |
分组函数过滤案例
查询平均薪水大于2000的部门 :
1 | select deptno, avg(sal) from emp group by deptno having avg(sal)>2000; |
优化
在子句中没有使用组函数的情况下,where、having都可以,应该怎么选择?
SQL优化: 尽量采用where。
如果有分组的话,where是先过滤再分组,而having是先分组再过滤。当数据量庞大如1亿条,where优势明显。
单行函数
单行函数:只对一行进行变换,产生一个结果。函数可以没有参数,但必须要有返回值。
- 操作数据对象
- 接受参数返回一个结果
- 只对一行进行变换
- 每行返回一个结果
- 可以转换数据类型
- 可以嵌套
- 参数可以是一列或一个值
字符函数
lower小写,upper大写,initcap单词的首字母大写concat(连接符||)concat函数只能连接两个字符串, 若想连接三个的话只能嵌套调用;
||可以连接多个字符串, 建议使用||来连接字符串.substr(str,pos,len)截取字符串str,从pos位置开始截取len个注意:pos是从1开始的, 若len为0表示从pos开始, 截取到最后, 若pos为负数, 表示从末尾倒数开始截取
instr(str, substr):判断substr是否在str中存在, 若存在返回第一次出现的位置, 若不存在则返回0lpad和rpad–
l(r)pad(str, len, ch):返回len长度的字符串, 如果str不够len的话, 在左(右)填充ch这个字符trim(str):去掉字符串str首部和尾部的空格,中间的空格不去掉也可以
trim(c from str):去掉str中的c字符replace(str, old, new):将str字符串中的old字符串替换成new字符串length和lengthb
select length('hello world') 字符数, lengthb('hello world') 字节数 from dual;
注意:对于length函数一个汉字是一个字符, 对于lengthb函数,一个汉字占两个,这两个函数对于普通字符串没有什么区别.
数值函数
round(n,m): 四舍五入,对n这个数值四舍五入保留小数点后m位trunc(n,m): 截取,对n这个数值截取小数点后m位前的内容mod(n,m):n对m取余ceil(n):对n向上取整;floor(n):对n向下取整
转换函数
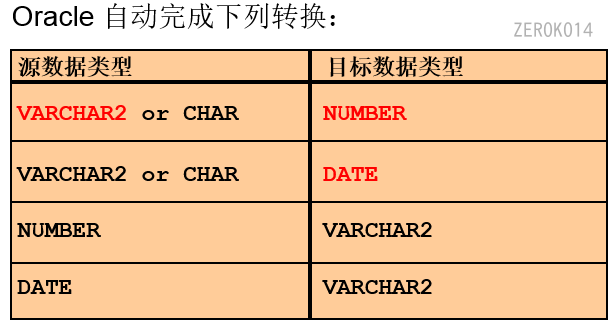
显示转换:借助to_char(数据,格式)、to_number、to_date函数来完成转换。
[注意] 如果隐式、显示都可以使用,应该首选显示,这样可以省去oracle的解析过程。
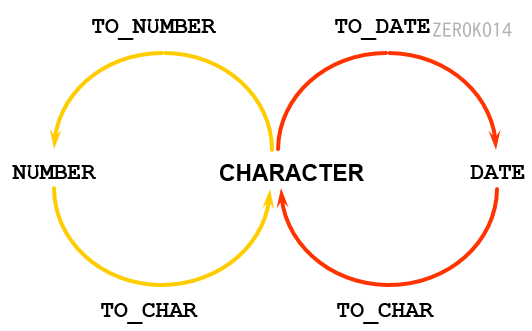
to_char函数
功能:将date或number类型转换成字符串类型

案例:
查询员工的薪水: 使用2位小数, 本地货币代码, 千位符
1 | select to_char(sal, 'L9,999.99') from emp; |
特别注意:’L9,999.99’之间没有空格

在屏幕上显示如下字符串:
2015-05-11 16:17:06 今天是 星期一
1 | select to_char(sysdate, 'yyyy-mm-dd hh24:mi:ss "今天是" day') from dual; |
说明: 在固定的格式里加入自定义的格式是可以的,必须要加””。

to_number函数
功能:将字符串转换成number类型
案例:
将¥2,975.00转化成数字2975:
1 | select to_number('¥2,975.00', 'L9,999.99') 转成数字 from dual; |
to_date函数
功能:将字符串转换成date类型
已知字符串’2015-05-11 15:17:06 今天是 星期一’转化成日期.
1 | select to_date('2015-05-11 15:17:06 今天是 星期一', 'yyyy-mm-dd hh24:mi:ss "今天是" day') from dual; |

求1980年12月17日入职的员工信息
1 | select * from emp where hiredate = to_date('17-12月-80','DD-MON-RR'); |
date的格式
(格式不区分大小写)
| 格式 | 说明 | 举例 |
|---|---|---|
| YYYY | Full year in numbers | 2011 |
| RR | 年份的后两个数字 | 11 |
| YEAR | Year spelled out(年的英文全称) | twenty eleven |
| MM | Two-digit value of month 月份(两位数字) | 04 |
| MONTH/mon | Full name of the month(月的全称) | 4月 |
| DY | Three-letter abbreviation of the day of the week(星期几) | 星期一 |
| DAY | Full name of the day of the week | 星期一 |
| DD | Numeric day of the month | 02 |
| HH24 | 2位数字的24小时制的小时数 | 11 |
| MI | 2位数字的分钟数 | 52 |
| ss | 2位数字的秒数 | 44 |
时间和日期函数
sysdate 当前的系统时间 如: select sysdate from dual;
oracle日期型+1 = 加一天
日期和日期可以相减表示相隔多少天, 但是不允许相加, 两个日期相加没有意义(报错: ORA-00975: 不允许日期 + 日期), 日期只能和数字相加
上面方式如果计算月差,年差,周差,等可以分别除以30,365,7.但这样计算显然是不精确的
如下日期函数才来精确计算
months_between(date1,date2)计算date1-date2的月差add_months(date,n)date日期增加n个月last_day(date)date日期的这个月的最后一天next_day(date,'星期一')date日期的下一个星期一round(date,'month')date日期按月份四舍五入(过了一半就加1,没过一半就不加)trunc(date,'year')date日期按年份截断(月份和日数归最小),按月截断的话表示日数归最小
通用函数
这些函数适用于任何数据类型,同时也适用于空值:
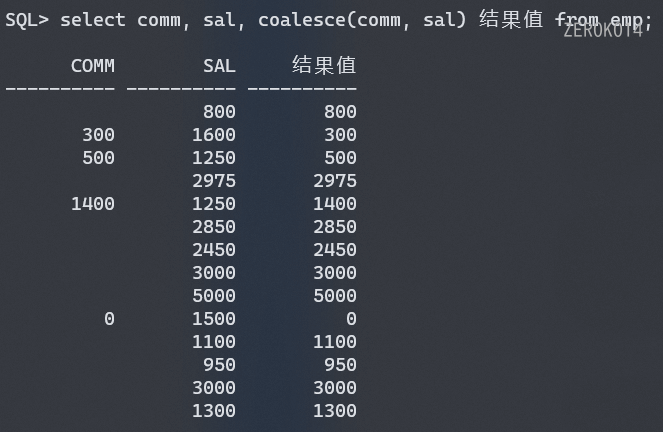
NVL (expr1, expr2)滤空函数: 如果expr1为NULL,返回expr2NVL2 (expr1, expr2, expr3)滤空函数: 如果expr1为NULL,返回expr3,否则返回expr2NULLIF (expr1, expr2)当 expr1 = expr2 时返回null, 不相等的时候返回expr1值。COALESCE (expr1, expr2, ..., exprn)找非空值函数 从左向右找参数中第一个不为空的值。
分组函数
分组函数:也称之为组函数或者聚合函数,oracle提供的常用的有5个函数: avg、count、max、min、sum操作的是一组数据,返回一个结果。 可以配合分组数据使用(select后同时存在分组函数和非分组函数的情况下,必须配合分组数据使用)
count(列名或1)计算行数(滤空) 1表示只要有值,都算+1;列名表示按照该列名算行数select count(distinct job) from emp显示工作总数(去重才能计算到工作总数)avg(列名)求平均列值(滤空) 注意:avg(comm)等同于sum(comm)/count(comm)(滤空) 而非sum(comm)/count(empno)(不滤空),前者是有奖金的人的奖金平均值,后者是全部人平均奖金的值max(列名)求列值最大值(滤空)min(列名)求列值最小值(滤空)sum(总和)求列值总和(滤空)

总结 : 分组函数自带滤空功能
可以通过 nvl函数 去掉分组函数的滤空功能,如下
1 | select avg(nvl(comm,0)) from emp; |
count注意点
count(*)和count(e.empno)的区别:
count(*)只要一行中有一个字段不为空就被统计上count(e.empno)只有e.empno不为空才会被统计上- [注意] 不能使用
count(e.*), 会报错.应该写成某个表的具体的列.
条件表达式与条件函数
在SQL中无法实现if else 逻辑。当有这种需求的时候,可以使用case 或者 decode
case条件表达式
case:是一个表达式,其语法为:
1 | CASE expr WHEN comparison_expr1 THEN return_expr1 |
上面代码解释,根据expr列名或表达式来判断,when后面的为判断值,如果expr = 该值,则返回return_expr1表达式.else后接when没提到的情况的返回值else_expr.
案例
老板打算给员工涨工资, 要求:
总裁(PRESIDENT)涨1000, 经理(MANAGER)涨800, 其他人涨400. 请将涨前, 涨后的薪水列出。
1 | select ename, job, sal 涨前薪水, |

decode函数
decode:是一个函数,其语法为:
1 | DECODE(col|expression, search1, result1 |
除第一个和最后一个参数之外,中间的参数都是成对呈现的 (参1, 条件, 值, 条件, 值, …, 条件, 值, 尾参)
案例
题目与效果图等同于case条件变量案例
1 | select ename, job, sal 涨前薪水, decode(job, 'PRESIDENT', sal + 1000, |
多表查询
只要select后出现多表重复存在的列名,则需要标识列名属于谁,如:
1 | select e.deptno from emp e,dept d; |
否则报错: ORA-00918: 未明确定义列
笛卡尔积
两个表的笛卡尔积 = 两个表的项之间组合的所有可能的集合
笛卡尔积的行数 = table1的行数 x table2的行数
笛卡尔积的列数 = table1的列数 + table2的列数
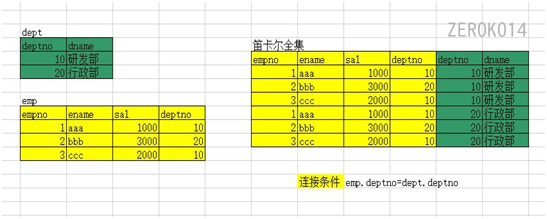
笛卡尔积中包含不正确的无用数据.上图中很显然左表(黄)和右表(绿)的deptno匹配会出现不相等的情况,即无效数据.(添加图中连接条件可以去除无效行)
多表查询就是按照给定条件(连接条件),从笛卡尔全集中选出正确的结果。
连接条件
Equijoin:等值连接Non-equijoin:不等值连接Outerjoin:外连接Selfjoin:自连接
等值连接
只返回满足连接条件的数据(两边都有的才显示)。
where子句后面的条件,是“=”为等值连接。
1 | select e.*,d.* from emp e, dept d where e.deptno = d.deptno; |
不等值连接
where子句后面的条件,不是“=”为不等值连接。
1 | select e.empno,e.ename,e.sal,s.grade from emp e,salgrade s where e.sal<=s.hisal and e.sal>= s.losal; |
外连接
按部门统计员工人数,显示: 部门号 部门名称 人数
1 | select d.deptno,dname,count(e.empno) from dept d,emp e where d.deptno = e.deptno group by dname,d.deptno; |

虽然显示了如上结果,但因为where d.deptno = e.deptno,缺失了40号部门
右外连接
右边deptno显示全
写法:与叫法相反:where e.deptno(+)=d.deptno
1 | select d.deptno,dname,count(e.empno) from dept d,emp e where e.deptno(+)=d.deptno group by dname,d.deptno; |
左外连接
左边deptno显示全
写法:与叫法相反:where d.deptno=e.deptno(+)
左外连接和右外连接效果完全一样,只是顺序不同.
[重点] (+)符号加在哪就看两边的行数想要显示全,就在另一边加上该符号
自连接
核心,通过表的别名,将同一张表视为多张表。
查询员工信息:xxx的老板是 yyy
1 | select e.ename || ' 的老板是 ' || b.ename from emp e, emp b where e.mgr=b.empno; |

由于KING没有老板,所以可以使用外连接的方式把king也显示出来:
1 | select e.ename || ' 的老板是 ' || nvl(b.ename,'没有') from emp e, emp b where e.mgr=b.empno(+); |

子查询
子查询语法很简单,就是select 语句的嵌套使用,即sql嵌套sql。
语法格式: 主查询的where、select、having、from后都可以放置子查询,如下:
1 | SELECT select_list |
查询工资比SCOTT高的员工信息.
查出SCOTT的工资
select ename, sal from emp where ename='SCOTT'; 结果为3000查询比3000高的员工
select * from emp where sal>3000;
通过两步可以将问题结果得到。子查询,可以将两步合成一步。
1 | select * |
- 写一个较复杂的子查询的时候,要合理的添加换行,缩进
- 主查询的where、select、having、from后都可以放置子查询
- 强调:在from后面放置的子查询(…), from后面放置是一个集合(表、查询结果)
- 一般不在子查询中使用order by, 但在Top-N分析问题中,必须使用
order by - 子查询可以放在select后,但,要求该子查询必须是单行子查询:(该子查询本身只返回一条记录,2+叫多行子查询)
- 单行子查询只能使用单行操作符;多行子查询只能使用多行操作符
where后子查询案例
参考第一个例子.
select后子查询案例
查询10号部分员工号,员工姓名,部门编号,部门名称
1 | select e.empno,e.ename,e.deptno,(select dname from dept where deptno=10) from emp e where deptno = 10; |
此处的子查询(select后)必须是单行子查询.
having后子查询案例
查询部门平均工资高于20号部门平均工资的部门和平均工资
1 | select deptno,avg(sal) |
from后子查询案例
查询员工的姓名、薪水和年薪:要求格式为:select * from ___________________
1 | select * from (select ename 姓名,sal 薪水,sal*12+nvl(comm,0) 年薪 from emp); |
多行子查询
子查询返回2条记录以上就叫多行。
多行操作符有:
IN等于列表中的任意一个ANY和子查询返回的任意一个值比较ALL和子查询返回的所有值比较
案例
查询薪水比30号部门任意一个员工高的员工信息
1 | 单行子查询方式min实现: |
查询薪水比30号部门所有员工高的员工信息。
1 | 单行子查询方式max实现: |
单行子查询
单行子查询就是该条子查询执行结束时, 只返回一条记录(一行数据)。
使用单行操作符:
=、>、>=、<、<=、<>或者!=
子查询中null
判断一个值等于、不等于空,不能使用=和!=号,而应该使用is 和 not。
[ [特别注意] ] 如果集合中有NULL值,不能使用not in。如: not in (10, 20, NULL),但是可以使用in。
1 | //用等于号与不等于号和null做比较都返回假 |
因为, not in操作符等价于 !=All,最后一个表达式为假,整体假;
而a in (10, 20, NULL)等价于(a = 10) or (a = 20) or (a = null)只要有一个为真即为真。
in 操作符等价于 = Any
子查询优化
一般情况下,子查询使用order by或是不使用order by对主查询来说没有什么意义。子查询的结果给主查询当成集合来使用,所以没有必要将子查询order by。
但,在Top-N分析问题中,必须使用order by
SQL优化: 理论上,既可以使用子查询,也可以使用多表查询,尽量使用“多表查询”。子查询有2次from, 与数据库服务的交互多.
top-N问题
Top-N指排名前N相关的问题
解决top-N问题使用了一个关键词 rownum (行号)
rownum的生成是在集合第一次产生的时候就生成了. 可以将查询的结果看成一个表来用
通过子查询排序的方式得到一个临时表,在外部查询中按照rownum来区分排名. 参考如下案例:
查询emp表中工资在5-8的员工信息
1 | select rn 排名,d.* from (select rownum rn,e.* from (select * from emp order by sal) e) d where rn<=8 and rn>=5; |
[讲解] 二级子查询中,子集合中的rownum不是列名的话,不能在上级查询中被作为筛选条件,解决方式是给rownum提供一个别名,再多加一层子查询,使最外部查询中rownum的别名成为一个列名,以此参与筛选.
结果:
集合运算
集合运算的操作符。A ∩ B、A ∪ B、A - B
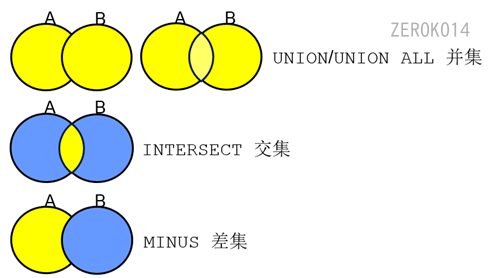
union和union all的区别: union会去掉重复的, 而union all会全部显示
集合运算注意点
- 参与运算的各个集合必须列数相同,且对应每个列的类型一致。(不然会报错类型不一致:
ORA-01790或 列数不同:ORA-01789) - 采用第一个集合的表头作为最终使用的表头.
- 可以使用括号()先执行后面的语句。
案例
按照部门统计各部门不同工种的工资情况,要求按如下格式输出:
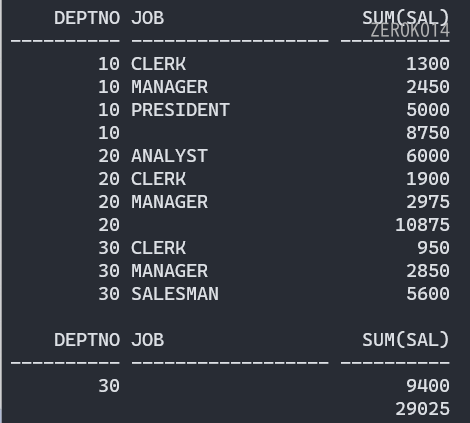
照集合的要求,必须列数相同,类型一致,所以写法如下,使用null强行占位!
1 | select deptno,job,sum(sal) from emp group by deptno,job |
sql优化 : 集合运算的性能一般较差
一些tips
尽量使用列名,用列名代替* (oracle 9i之前不同, 之后一样)
sysdate可以作为列名在select后使用,表示当前日期,如果from后面不来源于任何表,可以使用伪表dual
综合案例
查询部门工资大于本部门平均工资的员工信息
先查询10号部门:
使用子查询:
1 | select e.deptno, |
推广到所有部门 (其实就是10换成e.deptno)
1 | select e.deptno, |
上述是一种解决方案,也可以:使用多表查询:
1 | select e.deptno, e.empno, e.ename, e.sal, d.avgsal |
从emp表中查询, 结果显示如下的格式:
1 | Total 1980 1981 1982 1987 |
sql如下:
1 | select count(empno) "Total", |
事务
数据库事务,是由有限的数据库操作序列组成的逻辑执行单元,这一系列操作要么全部执行,要么全部放弃执行。
数据库事务由以下的部分组成:
- 一个或多个DML 语句
- 一个 DDL(Data Definition Language – 数据定义语言) 语句
- 一个 DCL(Data Control Language – 数据控制语言) 语句
事务的特点:要么都成功,要么都失败。
事务的特性
ACID: 原子性,一致性,隔离性,持久性
- 原子性(Atomicity):事务中的全部操作在数据库中是不可分割的,要么全部完成,要么均不执行。
- 一致性 (Consistency):几个并行执行的事务, 其执行结果必须与按某一顺序串行执行的结果相一致。
- 隔离性(Isolation):事务的执行不受其他事务的干扰,当数据库被多个客户端并发访问时,隔离它们的操作,防止出现:脏读、幻读、不可重复读。
- 持久性 (Durability):对于任意已提交事务,系统必须保证该事务对数据库的改变不被丢失,即使数据库出现故障。
事务的流程
事务的起始标志:oracle中自动开启事务,以DML语句为开启标志。
执行增删改查语句, 只要没有提交commit和回滚rollback, 操作都在一个事务中.
事务的结束标志: 提交、回滚都是事务的结束标志。
提交与回滚
提交
1.显示提交:
commit
2.隐式提交- 任何DDL语句,如:
create table除了创建表之外还会隐式提交Create之前所有没有提交的DML语句。 - 正常退出(exit / quit)
- 任何DDL语句,如:
回滚
1.显示回滚:
rollback
2.隐式回滚: 掉电、宕机、非正常退出。
控制事务
**保存点(savepoint)**可以防止错误操作影响整个事务,方便进行事务控制。
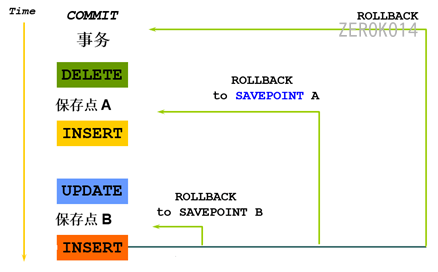
- 设置保存点aaa
savepoint aaa; - 回滚到保存点aaa
rollback to savepoint aaa;
savepoint主要用于在事务上下文中声明一个中间标记, 将一个长事务分隔为多个较小的部分,和我们编写文档时, 习惯性保存一下一样, 都是为了防止出错和丢失。如果保存点设置名称重复,则会删除之前的那个保存点。一旦commit之后,所有的savepoint将失效。
回滚的操作,会将回滚过程中的”设置保存点行为”也回滚掉.
隔离级别
对于同时运行的多个事务, 当这些事务访问数据库中相同的数据时, 如果没有采取必要的隔离机制, 就会导致各种并发问题:
- 脏读: 对于两个事物T1, T2; T1读取了已经被T2更新但还没有被提交的字段. 之后, 若 T2 回滚, T1读取的内容就是临时且无效的
- 不可重复读: 对于两个事物 T1, T2; T1 读取了一个字段, 然后 T2 更新了该字段. 之后, T1再次读取同一个字段, 值就不同了.
- 幻读: 对于两个事物 T1, T2, T1 从一个表中读取了一个字段, 然后 T2 在该表中插入了一些新的行. 之后, 如果 T1 再次读取同一个表, 就会多出几行.
数据库事务的隔离性: 数据库系统必须具有隔离并发运行各个事务的能力, 使它们不会相互影响, 避免各种并发问题.
一个事务与其他事务隔离的程度称为隔离级别. 数据库规定了多种事务隔离级别, 不同隔离级别对应不同的干扰程度, 隔离级别越高, 数据一致性就越好, 但并发性越弱.
SQL99定义4中隔离级别
Read Uncommitted读未提交数据。Read Commited读已提交数据。 (Oracle默认)Repeatable Read可重复读。 (MySQL默认)Serializable序列化、串行化。(查询也要等前一个事务结束)
Oracle支持的隔离级别: Read Commited(默认)和 Serializable,以及Oracle自定义的Read Only三种。
Read Only:由于大多数情况下,在事务操作的过程中,不希望别人也来操作,但是如果将别人的隔离级别设置为Serializable(串行),但是单线程会导致数据库的性能太差。是应该允许别人来进行read操作的。
oracle开发
oracle开发需要使用occi库
- Windows下开发需要先下载开发包,具体操作参考此链接
- Linux下下载oracle安装包有自带,通过
locate libocci.so查找
OCCI
Oracle C++调用接口 –
OCCI即Oracle C++ Call Interface
OCCI 是Oracle 的C++ API, 允许你使用面向对象的特性、本地类、C++语言的方法来访问Oracle数据库
OCCI介绍
优势
基于标准C++和面向对象的设计
效率较高
适合开发C/S模式的程序,软件中间层
特性
- 完整支持SQL/PLSQL
- 为不断增长的用户和请求提供弹性选项
- 为使用用户自定义类型,如C中的类,提供了无缝接口
- 支持所有的Oracle数据类型以及LOB types(大对象)
- 可以访问数据库元数据
OCCI项目配置
头文件
1 |
库文件
Windows
oraocci11.lib或oraocci11d.liboraocci11.dll或oraocci11d.dll(前者为release模式时使用,名字末尾带d的后者为debug模式时使用。)
库文件路径:
oci/lib/msvc/vc14头文件路径:
oci/include
Linux
libnnz11.solibocci.solibclntsh.so
linux下的环境配置
—–root用户下进行配置——
将oracle_client_11gR2.tar.gz文件上传到linux操作系统的
/opt目录下执行
tar -zxvf oracle_client_11gR2.tar.gz解压至当前目录下进入到刚刚解压的目录, 打开
<<Hi-看我,看我.sh>>将文件中的export导出的环境变量拷贝到root用户的
.bashrc文件中注意: 若解压的目录不是
/opt, 环境变量中的路径需要修改执行
..bashrc或者source .bashrc或者退出再次登录使配置的环境变量生效可以执行
echo $OCCI_HOME进行查看, 若看到内容则设置成功可以设置远程oracle服务器
切换到
/opt/instantclient_11_2/network/admin目录下打开
tnsnames.ora文件, 修改其中的HOST部分, 将IP修改成实际的oracle服务的IP地址occi.cpp测试代码上传到root用户下
然后执行:
g++ -o a.out occi.cpp -locci -lclntsh, 编译通过表明设置的没有问题.若执行报错, 查看一下代码中的oracle的用户名和密码是否正确.
常见的几个环境变量
1 | PATH:命令或者可执行程序搜索的路径 |
1 | oracle用户安装了oracle服务系统, 本身就有oracle编程需要的库文件和头文件: |
occi使用
开发流程
初始化 - Environment类
- OCCI通过创建一个Environment的对象完成初始化工作。
- 可以通过Environment创建数据库连接,从而进行其它的操作
- 要创建Environment,应该调用Environment类的静态方法
createEnvironment()
1 | // 初始化环境 (返回NULL表示失败) |
连接数据库 - Connection 类
1 | Connection *Environment::createConnection(const string &userName,const string &password,const string &connectString); |
- 连接数据库通过Connection类的对象实例实现
- 调用Environment类的
createConnection()方法可以创建一个Connection对象; - 使用Environment::terminateConnection()断开连接
1 | // 函数调用 |
执行SQL
**Statement类**用于执行SQL语句,并获取返回结果。
**ResultSet类**用于处理SELECT 查询的结果。
对于所有类型的数据的绑定或者获取,OCCI都提供了统一的方法
- setXXX 方法用于Statement
- getXXX 方法用于Statement & ResultSet
OCCI会自动处理类型之间的转换。
使用方法:
使用Connection::createStatement()创建Statement对象, 指定 SQL 命令(DDL/DML/query)作为参数
常用API
1 | // 操作函数 |
使用 setXXX 方法传递要绑定用于输入的值
使用合适的execute方法执行SQL
对于SELECT 查询, 使用ResultSet 对象处理返回结果
执行插入的案例:
1 | // 插入操作 |
使用绑定参数的DML(数据操作语句)示例:
1 | Statement *stmt = conn->createStatement(“ insert into Emp(EmpNo,Ename) values(:1, :2) ”); |
oracle简易案例
1 |
|
编译命令为:
1 | g++ -o a.out occi.cpp -I$ORACLE_HOME/rdbms/public -L$ORACLE_HOME/lib -locci -lclntsh |
执行返回结果为:
1 | userName:scott |
ORA-24550
在使用occi多线程访问oracle服务器的时候,会出现ORA-24550错误,错误信息如下:
1 | ORA-24550 : signal received : [si_signo=11] [si_errno=0] [si_code=50] [si_adr = |
该错误会导致进程终止, 修改方案如下:
使用fifind命令所有oracle服务器端的
sqlnet.ora文件, 在文件中添加下配置项:1
2
3DIAG_ADR_ENABLED=OFF
DIAG_SIGHANDLER_ENABLED=FALSE
DIAG_DDE_ENABLED=FALSE如果该问题还未解决, 在调用 OCCI 接口的客户端对应oracle目录中, 例如, 我的客户端对用的oralce目录为
/opt/instantclient_11_2, 在该目录下的network/admin中添加文件sqlnet.ora, 内容如下:1
2
3
4
5SQLNET.AUTHENTICATION_SERVICES= (NTS)
NAMES.DIRECTORY_PATH= (TNSNAMES,HOSTNAME)
DIAG_ADR_ENABLED=OFF
DIAG_SIGHANDLER_ENABLED=FALSE
DIAG_DDE_ENABLED=FALSE
Mysql
瑞典MySQL AB公司开发,由SUN收购,而后SUN被甲骨文并购,目前属于Oracle公司。
MySQL是一种关联数据库管理系统 由于其体积小、速度快、总体拥有成本低、MySQL软件采用了双授权政策,分为社区版和企业版。
oracle部分linux系统用不了,但mysql没有这个问题
MySQL版本及下载
MySQL数据库版本相对比较繁杂。常见的有:Community社区版、Enterprise企业版。
Community版是开源免费的,这也是我们通常用的MySQL的版本。可以满足绝大多数用户需求。Enterprise版,官方指出提供30天免费试用期。可进一步划分为MySQL标准版、MySQL企业版、MySQL集群版。官方提供付费服务。
其中Community Server 可以直接从mysql 的官网下载。但Enterprice Edition只能从Oracle edelivery上下载,而Edelivery有时会屏蔽中国IP。
下载mysql时注意区分版本细节及所应用的系统平台:linux(32/64) 、win(32/64)
GA 是指软件的通用版本,一般指正式发布的版本 (Generally Available (GA) Release)
mysql-essential-5.1.60-win32.msi精简版,如果只需要mysql服务,就选择此版本。mysql-5.1.60-win32.msi完整版,包含安装程序和配置向导,有MySQL文档。mysql-noinstall-5.1.60-win32.zip是非安装的zip压缩包,没有自动安装程序和配置向导,无安装向导mysql-5.1.60.zip是用于windows的Mysql源码压缩包
默认情况下,linux都会有mysql
red hat
卸载
red hat linux演示如何卸载mysql
在终端提示符输入:rpm -aq | grep -i mysql命令。查询mysql是否安装
卸载旧的版本操作
rpm -e 软件包名 --nodeps --allmatches(不理会依赖关系,删除所有上一步查出来的相同的mysql)rpm -e mysql-connector-odbc-3.51.26r1127-1.el5 --nodeps --allmatchesrpm -e libdbi-dbd-mysql-0.8.1a-1.2.2 --nodeps --allmatchesrpm -e mysql-server-5.0.77-3.el5 --nodeps --allmatches将老版本的几个残留文件手动删除
1
2
3
4rm -f /etc/my.cnf
rm -rf /var/lib/mysql
rm -rf /var/share/mysql
rm -rf /usr/bin/mysql*
安装
red hat linux演示如何安装mysql
解压.zip安装包unzip V46610-01-MySQL Database 5.6.20 RPM for Oracle Linux RHEL 6 x86 (64bit).zip
得到如下软件包
1 | //下面三个必装 |
安装服务器 rpm -ivh MySQL-server-advanced-5.6.****-1.el6.x86_64.rpm
第一次安装,会自动生成一个文件/root/.mysql_secret,文件内含mysql的root用户的密码.因此必须在第一次连接的时候修改此处的密码
mysql_secure_installation 配置安全选项
默认配置设置文件在 /usr/my.cnf ,可以编辑这个 文件改变mysql服务器设置
安装客户端
rpm -ivh MySQL-client-advanced-5.6.****-1.el6.x86_64.rpm
说明:不安装mysql-client是不能使用mysql工具登陆到mysql数据库
修改密码 mysql> set password=password('123456'); 将密码设置为:123456`
ubuntu
安装
ubuntu下安装: apt-get install mysql-server (root无初始密码)
设置MySQL的root初始密码: ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'your_password';
mysql_secure_installation这个命令设置mysql安全配置向导
是否建立密码验证插件(用以验证密码强度):n
首次运行则会要求输入并确认root密码,设置过第2步的root初始密码则会提示是否修改密码。
如果遇到以下报错,请先执行上面第2步的设置root初始密码:
1
Failed! Error: SET PASSWORD has no significance for user ‘root’@’localhost’ as the authentication method used doesn’t store authentication data in the MySQL server. Please consider using ALTER USER instead if you want to change authentication parameters.
是否删除匿名用户:y
是否禁止root远程登陆:n
是否删除test数据库:y
刷新权限:y
给root账号开放所有权限: GRANT ALL PRIVILEGES ON *.* TO root@'localhost';
检查mysql服务状态 sudo systemctl status mysql
mysql服务的启动/停止/重启
1 | 启动MySQL服务 |
如果要安装客户端和开发组件要分别执行下面语句
1 | sudo apt install libmysqlclient-dev |
卸载
apt autoremove mysql-server
win7 64位
下面以mysql-5.7.24-winx64为例
安装流程及配置初始root用户,及授权远程连接流程如下:
在C:\Program Files目录下新建目录MySQL
将下载到的mysql-5.7.24-winx64.zip解压到目录
C:\Program Files\MySQL进入目录
C:\Program Files\MySQL\mysql-5.7.24-winx64里,并新建一个文件my.ini文件内容如下:(注意:不能有bom头)高危坑点!!!!(win7的记事本只要打开utf8编码格式的文件就会自动添加bom头,而bom头mysql不识别!!!)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20[client]
port=3306
default-character-set=utf8
[mysqld]
# 设置为自己MYSQL的安装目录
#basedir=C:\Program Files\MySQL\mysql-5.7.24-winx64
# 设置为MYSQL的数据目录
#datadir=C:\Program Files\MySQL\mysql-5.7.24-winx64\data
#port=3306
max_connections=1024
character_set_server=utf8
max_allowed_packet=32M
read_buffer_size=4M
#sql_mode=NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER
# 开启查询缓存
#某些系统版本需要开启这项(win7确定需要)
explicit_defaults_for_timestamp=true
# 第一次启动MYSQL打开这行(一定放在末尾),可以免密登陆,方便登录设置root密码
skip-grant-tables管理员身份运行命令 在C:\Windows\System32路径下以管理员执行cmd
进入目录C:\Program Files\MySQL\mysql-5.7.24-winx64\bin
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20执行安装命令
mysqld.exe install
执行初始化命令
mysqld.exe --initialize
启动 mysql 服务
net start mysql
这里如果报错:无法启动此程序,因为计算机中丢失MSVCR120.dll.尝试重新安装该程序以解决问题
解决方案:装2013 Redistributable
运行mysql,由于之前我们设置登入无密码,当系统提示需要输入密码时,直接按回车键
mysql -u root -p
此时会显示password: 直接回车!
此时会进入mysql>
输入下面的三条命令来设置root密码
flush privileges;
设置'root'@'localhost'用户的密码为'xxxxxx'
set password for 'root'@'localhost'=password('xxxxxx');#'@'localhost'表示只有在本地连接时才使用此密码。如果是远程连接,则需要另外设置密码
修改'root'@'localhost'用户的密码过期时间为永不过期。
alter user 'root'@'localhost' password expire never;
刷新权限,使设置生效。
flush privileges;将目录C:\Program Files\MySQL\mysql-5.7.24-winx64\下的文件my.ini里面的最后一行通过使用#注释掉
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18quit;#退出>mysql
重启mysql服务
net stop mysql
net start mysql
客户端用户可能无法访问服务器mysql,因此需要开启远程连接权限
mysql -u root -p
这里显示password:输入上面设置的密码xxxxxx
use mysql;
将用户表中用户名为'root',主机为'localhost'的用户的主机(host)改为'%',表示允许该用户从任何主机连接。
update user set host = '%' where user = 'root' and host='localhost';
查看效果(这句可以不输)
select host, user from user;
然后重启mysql服务
net stop mysql
net start mysql
进入mysql刷新权限设置
mysql -u root -p
flush privileges;
各种问题盘点
- 记事本不能使用,可以使用vscode修改,打开后右下角是utf8不是utf8 with BOM就没问题;或者使用Notepad++,保存文件时选择“UTF-8 without BOM”选项
- 如果因为任何的原因导致mysql启动失败报错,但是当你想net stop mysql或net start mysql的时候会一直提示:服务正在启动或停止中,请稍候片刻后再试一次.解决方案为:任务管理器强杀mysqld进程,然后就可以正常net start mysql或net stop mysql了
- net start mysql如果报错:无法启动此程序,因为计算机中丢失MSVCR120.dll.尝试重新安装该程序以解决问题.解决方案:装c++ 2013 Redistributable
win10 64位
MySQL Community Downloads 找MySQL Installer for Windows选项
mysql的基本操作
mysql -u用户名 -p密码进入本地mysql命令行 e.g.mysql -uroot -p12345
若想进入远程数据库,需要使用参数-h192.168.0.3指定远程主机ip地址
退出登录 quit/exit
在MySQL中,您可以使用CREATE USER语句创建新用户。创建新用户的基本语法如下:CREATE USER 'username'@'host' IDENTIFIED BY 'password';,其中username是您要创建的用户的名称,host是用户可以连接的主机(可以是特定的IP地址或通配符,例如%表示任何主机),而password是新用户的密码 。
创建用户后,您需要为他们授予适当的权限,以便他们能够访问和操作MySQL服务器上的数据库和表。这可以使用GRANT语句完成 。例如,要将所有权限授予test数据库中的johndoe用户,您可以使用以下命令:GRANT ALL PRIVILEGES ON test.* TO 'johndoe'@'%';。需要注意的是,创建用户后,您必须刷新权限以反映所做的更改,方法是运行 FLUSH PRIVILEGES; 。
数据库CURD
对数据库进行增(create)、删(delete)、改(update)、查(Retrieve)操作
[注意] mysql中数据库名和表名都区分大小写
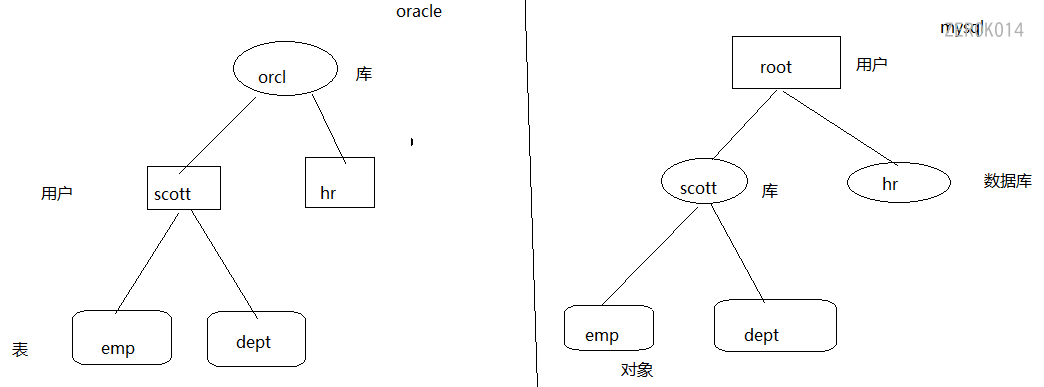
组织结构
- oracle是先有库,库下是用户,用户下再有表
- mysql是先有用户,用户下是库,库下是表
操作盘点
显示已有的所有数据库
show databases显示建数据库的语句
show create database 数据库名新建数据库
create database 数据库名创建字符集为utf-8的数据库:
create database 数据库名 character set utf8;创建字符集为utf-8并会对存入的数据进行检查是否utf8格式的数据库
create database 数据库名 character set utf8 collate utf8_general_ci;如果不存在才新建数据库
create database if not exists 数据库名删除数据库
drop database 数据库名修改数据库字符集(不能修改数据库名)
alter database 数据库名 character set utf8;进入数据库
use 数据库名查看当前使用的是哪个库
status;或select database() from dual;source sql脚本文件路径用该命令执行上面的sql脚本文件.点击参考显示索引是
show index from 表名
p.s. 默认情况下,反引号 `` ` 括起来的字符串,区分大小写.
表CURD
mysql的表curd操作和oracle是几乎一样的,只有数据类型不一致.
mysql的数据类型
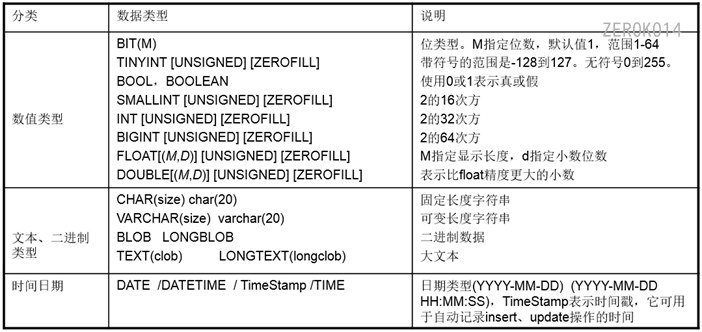
p.s. (附加说明)
bit1位 可以指定位数,如:bit(3)int2字节 可以指定最大位数,如:int<4> 最大为4位的整数float2个字节 可以指定最大的位数和最大的小数位数,如:float<5,2> 最大为一个5位的数,小数位最多2位double4个字节 可以指定最大的位数和最大的小数位数,如:float<6,4> 最大为一个6位的数,小数位最多4位char必须指定字符数,如char(5) 为不可变字符 即使存储的内容为’ab’,也是用5个字符的空间存储这个数据varchar必须指定字符数,如varchar(5) 为可变字符 如果存储的内容为’ab’,占用2个字符的空间;如果为’abc’,则占用3个字符的空间text: 大文本(大字符串)blob:二进制大数据 如图片,音频文件,视频文件date: 日期 如:’1921-01-02’datetime: 日期+时间 如:’1921-01-02 12:23:43’timeStamp: 时间戳,自动赋值为当前日期时间
在Mysql中显示多行数据应该在查询语句结尾处添加 \G或\g来替换结束标记;

- 创建表
create table t1 (id int, name varchar(20)) - 查看当前选择的数据库中的表
show tables; - 查看表结构
desc tablename; - 查看创建表的语法
show create table t1; - 更改表名
rename table employee to worker; - 增加一个字段
alter table employee add column height double;(column关键字在Oracle中,添加则语法错误) - 修改一个字段
alter table employee modify column height float; - 删除一个字段
alter table employee drop column height; - 修改表的字符集
alter table employee character set gbk; - 删除employee表
drop table employee;
注意:mysql删除表不能使用purge
数据的CURD操作
和oracle是一样的.
查询
select id, name as "名字", salary "月薪", salary*12 年薪 from employee where id >=2;修改
update employee set salary=10000, resume='也是一个中牛' where name='王五';删除
delete from employee where name='王五';truncate employee;插入
insert into employee values(1,'张三',1,'1983-04-27',15000,'2012-06-24','一个大牛');
mysql的分组查询注意点
在oracle数据库中,having后面不可以使用别名,mysql可以使用别名(别名若是中文不要加"")
1 | #正确的 |
尽量使用英文别名
mysql的top-N问题
oracle中的top-N问题比较复杂,而mysql中很简单
关键词 limit
在查询中,经常要返回前几条或者中间某几行数据时,用到limit
$$
limit\ \ offset,rows
$$
参数说明:offset:指定第一个返回记录行的偏移量(即从哪一行开始返回),注意:初始行的偏移量为0。rows:返回具体行数。
如果limit后面是一个参数,就是检索前多少行。如果limit后面是2个参数,就是从offset+1行开始,检索rows行记录。
案例
将math成绩从小到大排序,求math成绩在5-8名的学生的信息
select * from student order by math limit 4,4;
mysql中的函数
日期时间函数
MySQL里面时间分为三类:时间、日期、时间戳(含有时分秒的sysdate)。 (在mysql中使用sysdate必须加小括号)
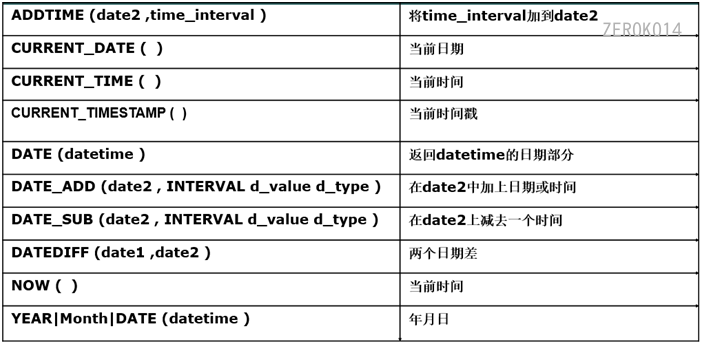
DATA_ADD等同于ADDDATE,DATA_SUB同理CURDATE等同于CURRENT_DATE,current_time同理

now() 等同于 sysdate() 等同于 current_timestamp()
addtime函数用法参考
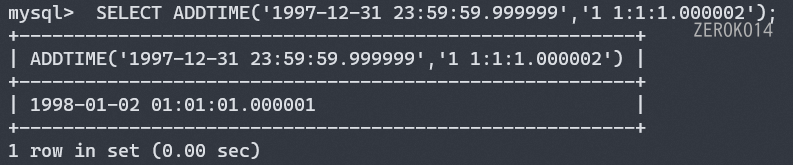
DATE_ADD函数用法参考 (interval是关键词,不能缺少)
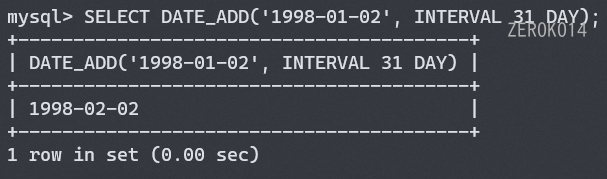
上述语句中的函数名, INTERVAL不区分大小写, day, month, year也可以用大写.
DATEDIFF函数用法参考
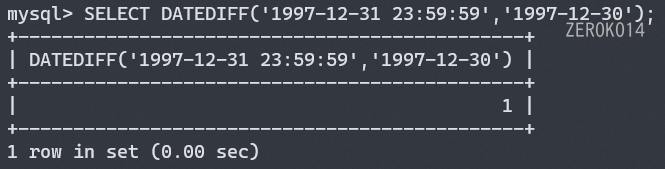
日期格式函数
日期转字符串
$$
DATE_FORMAT(date,format)
$$
根据format 字符串安排date 值的格式。
以下说明符可用在 format 字符串中:

案例: select date_format(now(),'%Y-%m-%d %H:%i:%s');

数学相关函数

conv(12,10,2)将12从10进制转换成2进制为1100format(12.015,2)将12.015保留小数点后两位为12.02mod(3700,300)求余为100rand函数一般用rand(now())
还有三角函数,指数等等的一大堆数学函数
字符串相关函数
**|| 连接字符串 在 MySQL不可以使用。**但mysql的concat函数可以连接多个字符串

replace会替换所有符合的字串strcmp相等返回0,小于返回-1,大于返回1substring的position可以为负数表示倒数第几个位置开始
转换函数
- 日期转字符串 :
date_format(date,format)函数 - 字符串转日期:
str_to_date(string,format)函数
滤空函数
mysql不支持nvl函数,取而代之是**ifnull**函数,用法与nvl函数一致.
注意:
Oracle中有一个通用函数,与MYSQL中的ifnull函数名字相近:nullif:如nullif(a, b)当 a = b 时返回null, 不相等的时候返回a值。nullif('L9,999.99', 'L9,999.99')
mysql中nullif()函数也存在。
mysql的多表查询
准备数据
新建scott.sql文件
1 | create database if not exists scott character set utf8; |
source /root/scott.sql 用该命令执行上面的sql脚本文件.
得到原始数据
交叉连接
相当于oracle的笛卡尔积
关键词 cross join
select e.*, d.* from emp e cross join dept d;
内连接
对应oracle中的等值连接
只返回满足连接条件的数据(两边都有的才显示)。
SQL99写法
关键词 [inner] join ... on ... (inner可以省略)
select e.ename,e.job,d.deptno,d.dname from emp e inner join dept d on e.deptno = d.deptno;
oracle写法
select e.ename,e.job,d.deptno,d.dname from emp e, dept d where e.deptno = d.deptno;
区别盘点: [,] —> [inner join] [where] —> [on]
mysql外连接
mysql左外连接
左边有值才显示。 与oracle的左外连接仅仅是写法不同,含义一致
关键词 left [outer] join ... on ... (outer可省略)
1 | select e.*, d.* |
mysql右外连接
右边有值才显示。 与oracle的右外连接仅仅是写法不同,含义一致
关键词 right [outer] join ... on ... (outer可省略)
1 | select e.*, d.* |
即可知: SQL99中,外链接取值与关系表达式=号左右位置无关。取值跟from后表的书写顺序有关。
[案例] 统计各个部门员工总人数-要求显示部门名称
1 | select count(e.empno),d.dname from emp e right join dept d on e.deptno = d.deptno group by dname; |
[自连接案例] 查询员工、老板信息,显示: xxx的老板是xxx
1 | select concat(e.ename,'的老板是',ifnull(b.ename,'自己')) from emp e left join emp b on e.mgr = b.empno; |

mysql满外连接
任一边有值就会显示。 在oracle中没有对应
关键词 full [outer] join ... on ... (outer可省略)
1 | select e.*, d.* |
mysql表的约束
- 定义主键约束
primary key不允许为空,不允许重复 - 定义主键自动增长
auto_increment(从1开始,即使插入不填或者手动填null,也会从1开始自动增长给数) - 定义唯一约束
unique - 定义非空约束
not null - 定义外键约束
constraint ordersid_FK foreign key(ordersid) references orders(id)
[注意] check约束在MySQL中语法保留,但没有效果
案例
1 | create table myclass ( |
mysql中文乱码问题
查看所有应用的字符集 show variables like 'character%';
关于
utf8mb3和utf8mb4,其主要区别在于:most bytes 3和most bytes 4,即最多使用3 / 4个字节来表示1个字符!所以,当使用utf8mb4时,可以表示更多字符,例如生僻汉字、冷门符号、emoji表情符号等。
指定字符集登录数据库(默认是utf8mb4) mysql -uroot -p123456 --default_character_set=gbk
上面语句如果不是和插入时登录数据库使用的同一个字符集,就会中文乱码
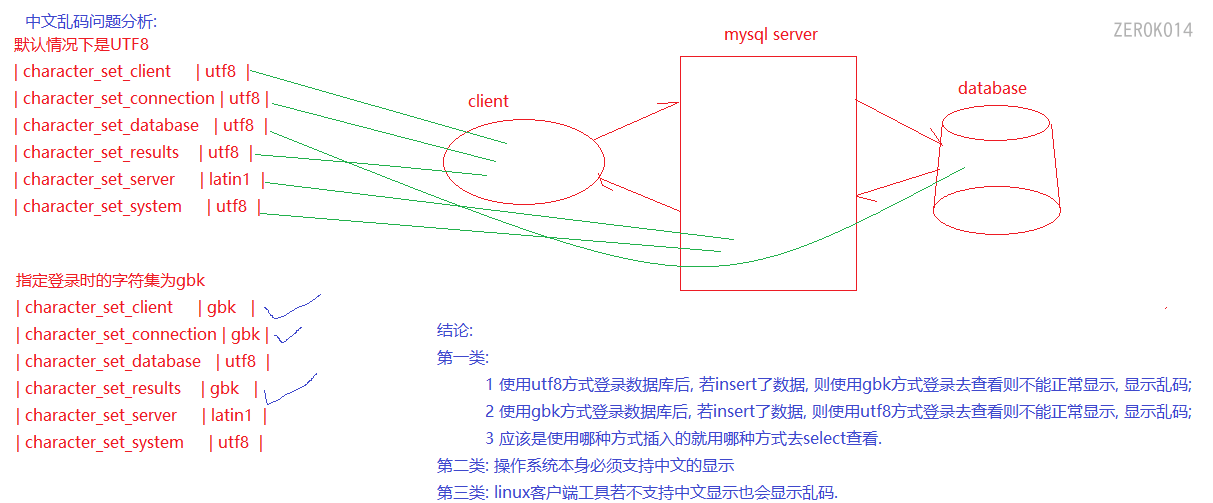
如果使用secureCRT,secureCRT菜单中的Options-Session Options-Category-Terminal-Appearance中可以设置Character encoding设置工具的字符集(如果未设置为utf-8也会显示乱码)
操作系统的语言集
Ubuntu下查看字符集 cat /etc/default/locale
red hat下查看字符集 cat /etc/sysconfig/i18n
返回显示LANG="en_US.UTF-8" 表示环境变量LANG = 操作系统的菜单按照zh_CN显示,文件存储按照utf8
操作系统本身不是utf-8也会乱码
总结:
- 使用哪种字符集插入的数据,就要用哪种字符集去select查看
- 操作系统本身必须支持中文的显示
- linux客户端工具若不支持中文显示也会显示乱码
MYSQL API
访问MySQL服务器,这需要使用mysqlclient库,MySQL的大多数客户端API(除Java和.NET)都是通过这个库来和MySQL服务器通讯的,而这个库正是使用C语言编写的。
可使用mysql -V 命令查看当前系统内所使用的mysql数据库版本信息。MySQL客户端使用 libmysqlclient 库内部的函数访问MySQL服务器。因此我们在编程过程中,如若使用到库内的函数,必须链接函数库,对应的要找到头文件所在目录位置、函数库路径。以便我们在使用gcc编译工具时可以填充参数-I、-L、-l。
从手册中可获知,函数库名为mysqlclient。
因此我们使用命令find / -name libmysqlclient* 或locate *libmysql*(ubuntu下需要下载支持)查找该库的路径。得到/usr/lib/x86_64-linux-gnu/libmysqlclient.a。nm /usr/lib/x86_64-linux-gnu/libmysqlclient.a命令可查看库内包含的函数。
链接使用该库。
用到头文件<mysql.h>可使用locate mysql.h查看其目录位置/usr/include/mysql/mysql.h。
编译引用库的应用程序
1 | gcc hello.c -o hello -I/usr/include/mysql/ -L/usr/lib/x86_64-linux-gnu/ -lmysqlclient |
如果链接出错,原因是某些64位Linux环境下,动态库配置不完整。需手动指定编译所用的动态库。根据错误提示分析需要加入如下函数库:
__gxx_personality_v0–> -lstdc++ 使用g++相关的环境dlclose/dlopen/dlsym–> -ldl 完成用一个程序加载其他动态库的作用。pthread_*–>-lpthread 线程库- ``my_getsystime’/clock_gettime’` –>-lrt librt.so是glibc中对real-time的支持库
使用ldd命令可以查看该可执行文件运行所依赖的库文件。
常用函数
c/c++程序员需要访问mysql数据库时,可以有2个选择,一个是纯的mysql的c API, 另外一个是
mysqlplus这个库。前者是mysql的开发小组所维护的,其实现代码是mysql源代码的一部分。后者现在已经转为社区维护了。
总体印象
使用MySQL库API函数的一般步骤:
初始化.
MYSQL *mysql_init(MYSQL *mysql)错误处理
unsigned int mysql_errno(MYSQL *mysql)char *mysql_error(MYSQL *mysql);建立连接.
MYSQL *mysql_real_connect(MYSQL *mysql, const char *host, const char *user, const char *passwd,const char *db, unsigned int port, const char *unix_socket, unsigned long client_flag);执行SQL语句
int mysql_query(MYSQL *mysql, const char *stmt_str)获取结果
MYSQL_RES *mysql_store_result(MYSQL *mysql)MYSQL_ROW mysql_fetch_row(MYSQL_RES *result)释放内存
void mysql_free_result(MYSQL_RES *result)关闭连接
void mysql_close(MYSQL *mysql)
mysql_init函数
分配或初始化与mysql_real_connect()相适应的MYSQL对象。如果mysql是NULL指针,该函数将分配、初始化、并返回新对象。否则,将初始化对象,并返回对象的地址。如果mysql_init()分配了新的对象,当调用mysql_close()来关闭连接时。将释放该对象。
1 | MYSQL *mysql_init(MYSQL *mysql) |
返回值: 初始化的MYSQL*句柄。如果无足够内存以分配新的对象,返回NULL。
mysql_real_connect函数
mysql_real_connect()尝试与运行在主机上的MySQL数据库引擎建立连接。在你能够执行需要有效MySQL连接句柄结构的任何其他API函数之前,mysql_real_connect()必须成功完成。
1 | MYSQL *mysql_real_connect( |
| 标志名称 | 标志描述 |
|---|---|
| CLIENT_COMPRESS | 使用压缩协议。 |
| CLIENT_FOUND_ROWS | 返回发现的行数(匹配的),而不是受影响的行数。 |
| CLIENT_IGNORE_SPACE | 允许在函数名后使用空格。使所有的函数名成为保留字。 |
| CLIENT_INTERACTIVE | 关闭连接之前,允许interactive_timeout(取代了wait_timeout)秒的不活动时间。客户端的会话wait_timeout变量被设为会话interactive_timeout变量的值。 |
| CLIENT_LOCAL_FILES | 允许LOAD DATA LOCAL处理功能。 |
| CLIENT_MULTI_STATEMENTS | 通知服务器,客户端可能在单个字符串内发送多条语句(由‘;’隔开)。如果未设置该标志,将禁止多语句执行。 |
| CLIENT_MULTI_RESULTS | 通知服务器,客户端能够处理来自多语句执行或存储程序的多个结果集。如果设置了CLIENT_MULTI_STATEMENTS,将自动设置它。 |
| CLIENT_NO_SCHEMA | 禁止db_name.tbl_name.col_name语法。它用于ODBC。如果使用了该语法,它会使分析程序生成错误,在捕获某些ODBC程序中的缺陷时,它很有用。 |
| CLIENT_ODBC | 客户端是ODBC客户端。它将mysqld变得更为ODBC友好。 |
| CLIENT_SSL | 使用SSL(加密协议)。该选项不应由应用程序设置,它是在客户端库内部设置的。 |
调用mysql_real_connect之前不要尝试加密密码,密码加密将由客户端API自动处理
使用
1 | MYSQL *conn = mysql_real_connect(mysql,"localhost","root","password","myTest",0,NULL,0); |
mysql_query函数
**[功能]**执行由“Null终结的字符串”查询指向的SQL查询。正常情况下,字符串必须包含1条SQL语句,而且不应为语句添加终结分号;或\g。如果允许多语句执行,字符串可包含多条由分号隔开的语句。
mysql_query函数不单单能完成查询sql的功能,还能完成非select语句在c程序中的执行。是一个十分万能的c程序中执行SQL语句的函数。并且该函数本身直接支持静态SQL。如果语句中包含二进制数据,则需要调用mysql_real_query来执行查询语句。
1 | int mysql_query(MYSQL *mysql, const char *query); |
- 若执行的是**
UPDATE, DELETE或INSERT语句**,则可通过mysql_affected_rows()获知受影响的记录数。 - 若执行的是**
SELECT语句**,查询结束后,查询结果被保存在mysql句柄中。需要使用获取结果集的API函数将结果集获取出来。有两种方式可以获取结果集。
注意: mysql_query执行的SQL语句不应为语句添加终结分号(‘;’)或“\g”。
mysql_close函数
关闭前面打开的连接。如果句柄是由mysql_init()或mysql_connect()自动分配的,mysql_close()还将解除分配由mysql指向的连接句柄。
1 | void mysql_close(MYSQL *mysql); |
编码相关
mysql_character_set_name函数
为当前连接返回默认的字符集。
1 | const char *mysql_character_set_name(MYSQL *mysql) |
mysql_set_character_set函数
该函数用于为当前连接设置默认的字符集
1 | int mysql_set_character_set(MYSQL *mysql, char *csname) |
返回值: 0表示成功,非0值表示出现错误。
1 | //设置utf8编码集例子 |
结果集相关
一种方式是通过mysql_store_result()将整个结果集全部取回来。另一种方式则是调用mysql_use_result()初始化获取操作,但暂时不取回任何记录。视结果集的条目数选择获取结果集的函数。两种方法均通过mysql_fetch_row()来访问每一条记录。
mysql_store_result函数获取结果集mysql_fetch_row函数解析结果集mysql_free_result函数释放结果集- 获取列数函数
- 获取表头函数
mysql_affected_rows函数返回影响行数
mysql_store_result函数
获取结果集
1 | MYSQL_RES *mysql_store_result(MYSQL *mysql) |
MYSQL_RES是一个结构体类型,可以从mysql.h头文件中找到该结构体的定义
1 | typedef struct MYSQL_RES { |
使用案例
1 | MYSQL_RES *result = mysql_store_result(mysql); |
该函数调用成功,则SQL查询的结果被保存在result中
mysql_fetch_row函数
解析结果集
1 | MYSQL_ROW mysql_fetch_row(MYSQL_RES *result) |
使用案例
1 | MYSQL_ROW row = NULL; //typedef char **MYSQL_ROW; |
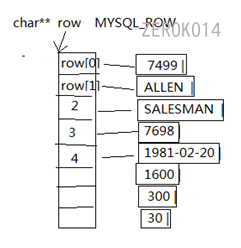
MYSQL_ROW的本质是tupedef char** MYSQL_ROW;,数据信息存储的形式如下图
mysql_free_result函数
释放结果集
1 | void mysql_free_result(MYSQL_RES *result); |
查询数据整体案例
1 | char sSql[255] = "select * from testTable"; |
获取列数函数
unsigned int mysql_field_count(MYSQL *mysql)从mysql句柄中获取连接的表有多少列。(表为连接数据库的时候指定了的某张表)unsigned int mysql_num_fields(MYSQL_RES *result)从返回的结果集中获取有多少列。
获取表头函数
MYSQL_FIELD *mysql_fetch_fields(MYSQL_RES *result)全部获取MYSQL_FIELD *mysql_fetch_field(MYSQL_RES *result)获取单个
返回值为**MYSQL_FIELD**结构体指针
1 | typedef struct MYSQL_FIELD { |
mysql_affected_rows函数
返回上次UPDATE更改的行数,上次DELETE删除的行数,或上次INSERT语句插入的行数。对于UPDATE、DELETE或INSERT语句,可在mysql_query()后立刻调用。对于SELECT语句,mysql_affected_rows()的工作方式与mysql_num_rows()类似。
1 | my_ulonglong mysql_affected_rows(MYSQL *mysql); |
[返回值] 大于0的整数表明受影响或检索的行数。“0”表示UPDATE语句未更新记录,在查询中没有与WHERE匹配的行,或未执行查询。“-1”表示查询返回错误,或者,对于SELECT查询,在调用mysql_store_result()之前调用了mysql_affected_rows()。由于mysql_affected_rows()返回无符号值,通过比较返回值和“(my_ulonglong)-1”或等效的“(my_ulonglong)~0”,检查是否为“-1”。
如果在连接至mysqld时指定了标志CLIENT_FOUND_ROWS,对于UPDATE语句,mysql_affected_rows()将返回WHERE语句匹配的行数。
mysql客户端编写案例
- mysql初始化 – mysql_init()
- 连接mysql数据库 – mysql_real_connect()
- 循环
- 打印提示符
- 读取用户输入的sql语句,判断是否为退出
- 不是退出的话执行sql语句取出结果集或影响行数打印出来 – mysql_store_result(),mysql_fetch_row(),mysql_affected_rows()
- 如果要释放结果集 – mysql_free_result()
- 关闭连接 – mysql_close()
代码
1 |
|
MYSQL的事务
事务相关知识点参考事务章节
- MySQL的事务的默认自动提交的,每执行一个sql语句都自动commit
- Oracle的事务是自动打开的(以你执行的一条DML语句为标志),但每次执行需要手动commit
在程序中设置**autocommit**修改MySQL事务的属性。(每次连接会重新恢复默认,要重新设置)
set autocommit = 0禁止自动提交set autocommit = 1开启自动提交MySQL中InnoDB引擎才支持事务默认自动提交机制。MYISAM引擎不支持。
相关sql语句
- 开启事务
start transaction - 设置手动提交
set autocommit = 0 - 设置自动提交
set autocommit = 1 - 提交
commit - 回滚
rollback
代码案例
1 |
|
预处理类API
MySQL客户端/服务器协议提供了预处理语句。该功能采用了由mysql_stmt_init()初始化函数返回的MYSQL_STMT语句处理程序数据结构。对于多次执行的语句,预处理执行是一种有效的方式。首先对语句进行解析,为执行作好准备。接下来,在以后使用初始化函数返回的语句句柄执行一次或多次。
对于多次执行的语句,预处理执行比直接执行快,主要原因在于,仅对查询执行一次解析操作。在直接执行的情况下,每次执行语句时,均将进行查询。此外,由于每次执行预处理语句时仅需发送参数的数据,从而减少了网络通信量。
预处理语句的另一个优点是,它采用了二进制协议,从而使得客户端和服务器之间的数据传输更有效率。
性能、调优是数据库编程永恒不变的主题!如果能把SQL语句框架预先处理好,当真正要执行SQL语句时只需要发送对应的参数到对应的SQL框架中,就能提高客户端访问服务器的速度,且数据量小,可以减少网络通信量,提高数据传输效率高。
预处理语句的优势在于归纳为:一次编译、多次运行,省去了解析优化等过程;此外预处理语句能防止 SQL 注入。
预处理相关函数
mysql_stmt_init()初始化预处理环境句柄。 返回一个结构体指针MYSQL_STMT *stmtmysql_stmt_prepare()向上面句柄中添加SQL语句,带有(?,?,?)占位符mysql_stmt_param_count()求绑定变量的个数(辅助函数), 有多少个’?’就返回多少mysql_stmt_bind_param()将?对应的实参,设置到预处理环境句柄中mysql_stmt_execute()执行预处理的SQL语句mysql_stmt_error()获取错误消息。mysql_stmt_close()关闭预处理语句
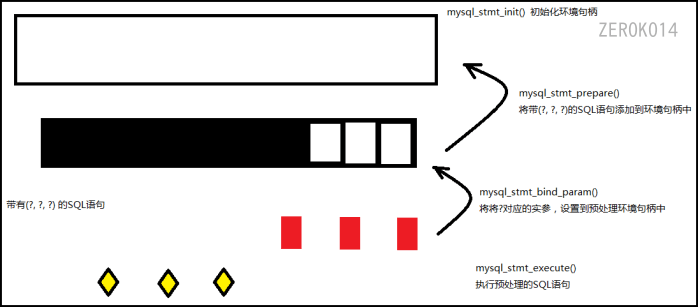
mysql_stmt_init函数
创建MYSQL_STMT句柄。对于该句柄,应使用mysql_stmt_close(MYSQL_STMT *)释放。
1 | MYSQL_STMT *mysql_stmt_init(MYSQL *mysql); |
mysql_stmt_prepare函数
准备sql语句框架,字符串必须包含1条SQL语句(通过将问号字符“?”嵌入到SQL字符串的恰当位置)。不应为语句添加终结用分号(‘;’)或\g。
1 | int mysql_stmt_prepare(MYSQL_STMT *stmt, const char *query, unsigned long length); |
可通过调用mysql_stmt_error() 获取错误消息。
mysql_stmt_param_count函数
返回预处理语句中参数标记符的数目。
1 | unsigned long mysql_stmt_param_count(MYSQL_STMT *stmt); |
mysql_stmt_bind_param函数
mysql_stmt_bind_param()用于为SQL语句中的参数标记符绑定数据,以传递给mysql_stmt_prepare()。它使用MYSQL_BIND结构来提供数据
1 | my_bool mysql_stmt_bind_param(MYSQL_STMT *stmt, MYSQL_BIND *bind); |
MYSQL_BIND结构体
详解参考官方文档
1 | typedef struct MYSQL_BIND { |
值得注意的是上面结构体中的length成员和buffer_length成员你的区别:
对于入参数据绑定,设置 length 表示 buffer 中存储的参数值的实际长度。这是由 mysql_stmt_execute() 使用的。
当length为NULL时,buffer_length可以作为长度来用
- 但改变buffer_length之后必须重新调用
mysql_stmt_bind()才会对查询起作用。- 而length只要改变其所指向的unsigned long,就会在下一次查询起作用,不用重新调用
mysql_stmt_bind()。对于输出值绑定,MySQL 在您调用 mysql_stmt_fetch() 时设置 length 。 mysql_stmt_fetch() 返回值决定了如何解释长度:
- 如果返回值为0,则 *length 表示参数值的实际长度。
- 如果返回值为
MYSQL_DATA_TRUNCATED,则 *length 表示参数值的非截断长度。在这种情况下, *length 和 buffer_length 中的最小值表示值的实际长度。
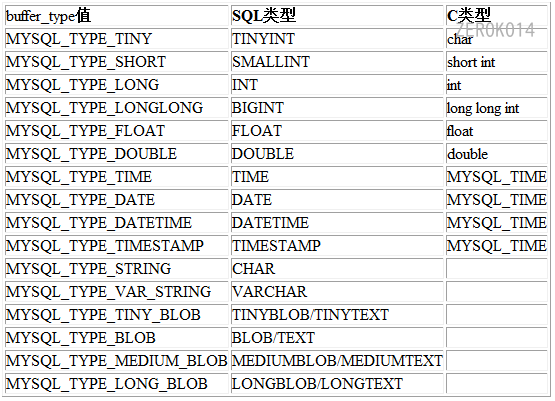
buffer_type成员指定的允许值:
mysql_stmt_execute函数
mysql_stmt_execute()执行与语句句柄相关的预处理查询。在该调用期间,将当前绑定的参数标记符的值发送到服务器,服务器用新提供的数据替换标记符。
1 | int mysql_stmt_execute(MYSQL_STMT *stmt); |
mysql_stmt_bind_result函数
1 | bool mysql_stmt_bind_result(MYSQL_STMT *stmt, MYSQL_BIND *bind) |
一种函数,用于将结果集中的列与数据缓冲和长度缓冲关联(绑定)起来。当调用mysql_stmt_fetch()以获取数据时,MySQL客户端/服务器协议会将绑定列的数据置于指定的缓冲区内。
mysql_stmt_fetch函数
mysql_stmt_fetch是函数名,mysql_stmt_fetch()返回结果集中的下一行。
1 | int mysql_stmt_fetch(MYSQL_STMT *stmt) |
| 返回值 | 描述 |
|---|---|
| 0 | 成功,数据被提取到应用程序数据缓冲区。 |
| 1 | 出现错误。调用mysql_stmt_error(),可获取错误消息。 |
| MYSQL_NO_DATA | 不存在行/数据。 |
| MYSQL_DATA_TRUNCATED | 出现数据截短。 |
mysql_stmt_error函数
对于由stmt指定的语句,mysql_stmt_error()返回由Null终结的字符串,该字符串包含最近调用的语句API函数的错误消息,该函数或成功或失败。如果未出现错误,返回空字符串("")
1 | const char *mysql_stmt_error(MYSQL_STMT *stmt) |
mysql_stmt_close函数
关闭预处理句柄
1 | my_bool mysql_stmt_close(MYSQL_STMT *); |
预处理案例
1 | char id[5]={0}; |
oracle和mysql的区别
oracle要求select和from一定要组合使用,mysql可以没有from
sqlite
SQLite 是一种轻量级的关系数据库管理系统,广泛用于嵌入式系统和移动应用程序中。它的特点是:
- 轻量级:SQLite 的库文件非常小,通常只有几百 KB,适合资源有限的环境。
- 自包含:SQLite 不需要安装和配置,所有的数据库文件都是普通的文件,可以直接使用。
- 零配置:它不需要服务器进程,数据库文件可以直接在应用程序中打开和操作。
- 跨平台:SQLite 可以在多种操作系统上运行,包括 Windows、Linux 和 macOS。
在各大操作系统中基本都有预装
可以使用sqlite3 --version查看安装的版本
时序数据库
- InfluxDB:一个开源的时序数据库,专为高性能数据写入和查询而设计,适合监控和分析工业数据。
- TimescaleDB:基于PostgreSQL的扩展,支持时序数据的存储和查询,具备强大的SQL功能。
- Prometheus:虽然主要用于监控,但也可以作为时序数据库,适合收集和查询时间序列数据。
- OpenTSDB:一个分布式、可扩展的时序数据库,通常与Hadoop和HBase结合使用。
- Graphite:用于存储和绘制时序数据,特别适合监控和性能指标。
- Kdb+:高性能的时序数据库,广泛应用于金融和其他需要快速数据处理的工业领域。
非关系数据库
数据库有两种
关系型数据库
mysql,oracle,sqlite,sql server
- 操作数据必须要使用sql语句
- 数据存储在磁盘
- 存储的数据量大
非关系型数据库
nosql,redis
- 操作不使用sql语句,命令方式
- 数据默认存储在内存,速度快,效率高,存储数据量小
- 不需要数据库表,以键值对的方式存储的

- 所有的数据默认存储在关系型数据库中
- 客户端访问服务器, 有一些数据, 服务器需要频繁的查询数据
- 服务器首先将数据从关系型数据库中读出 -> 第一次
- 将数据写入到redis中
- 客户端第二次包含以后访问服务器
- 服务器从redis中直接读数据
NoSQL数据库
如果你的应用场景允许,考虑使用 NoSQL 数据库(如 MongoDB)。
这些数据库通常使用 JSON 文档存储数据,操作方式更接近编程语言本身,避免了 SQL 的复杂性
下面是几个比较轻量的NoSQL数据库盘点如下:
- Redis: - Redis 是一个开源的键值存储数据库,通常用于缓存和快速数据存取。它在内存中运行,速度非常快,且可以通过简单的安装和配置来使用。虽然 Redis 的主要数据存储在内存中,但它也可以持久化到磁盘。
- LiteDB: - LiteDB 是一个轻量级的 NoSQL 文档数据库,专为 .NET 应用程序设计。它是一个单文件数据库,简单易用,适合嵌入式应用。
- PouchDB: - PouchDB 是一个 JavaScript 数据库,允许在浏览器中使用 NoSQL 数据库。它可以与 CouchDB 同步,适合需要在客户端存储数据的应用。
- LevelDB: - LevelDB 是一个开源的键值存储库,由 Google 开发。它是一个轻量级的数据库,适合需要快速存取和高效存储的场景。
Redis
安装与使用
安装命令: sudo apt install redis-server redis-tools
redis两个角色
服务器
1
2服务器启动(不填路径默认找根目录下的redis.conf)
redis-server [配置文件路径]客户端
1
2
3
4
5
6
7客户端
redis-cli [-p 端口号] [-h ip地址]
默认连接本地6379端口的服务器
通过客户端关闭服务器
shutdown
客户端的测试命令
ping ["测试消息"]
- 安装完成后,Redis服务将自动启动。您可以使用以下命令检查Redis服务的状态:
1 | sudo systemctl status redis-server |
如果服务正在运行,您将看到active (running)的状态。
2. 如果Redis服务未运行,您可以使用以下命令手动启动它:
1 | sudo systemctl start redis-server |
- 您还可以使用以下命令停止Redis服务:
1 | sudo systemctl stop redis-server |
- 如果您希望Redis服务在系统启动时自动启动,可以使用以下命令启用它:
1 | sudo systemctl enable redis-server |
redis配置文件
给redis服务器使用的
根目录下的redis.conf
配置文件常用配置项
1 | 允许谁访问redis服务器(如果注释掉它表示任何主机都可以访问到redis服务器) |
数据类型
redis中数据的组织形式:
key: 必须是字符串 - “hello world”(双引号括住的部分会将空格也视为字符串的一部分)
value: 可选的
String类型
字符串
List类型
存储多个String字符串的
Set类型
集合(元素不重复,数据是无序的)
SortedSet类型
排序集合(元素不重复,默认升序)
Hash类型
与[[stl]]数据组织方式一样 key:value
- map是红黑树实现的
- hash是数组实现的
常用命令
String类型命令
1 | key -> string |
List类型命令
1 | key -> string |
Set类型命令
1 | key -> string |
SortedSet 类型
1 | key -> string |
Hash类型命令
1 | key ->string |
Key 相关的命令
1 | 删除键值对 |
redis插件
[[数据结构#布隆过滤器|了解布隆过滤器]]
Redis数据持久化
持久化:数据从内存到磁盘的过程
持久化的两种方式
rdb方式- 这是一种默认的持久化方式,默认打开
- 磁盘的持久化文件
xxx.rdb - 将内存数据以二进制的方式直接写入磁盘文件
- 文件比较小,恢复时间短,效率高
- 以用户设定的频率同步数据
aof方式- 默认是关闭的
- 磁盘的持久化文件
xxx.aof - 直接将生成数据的命令写入磁盘文件
- 文件比较大,恢复时间长,效率低
- 每隔1s同步一次,不可设置(由于频率很快,数据完整性高)
二者关联
- aof和rdb同步方式可以同时打开
- aof和rdb同步方式可以同时关闭
- 两种模式同时开启的情况下,数据恢复时
- 效率上考虑用
rdb模式 - 数据完整性上考虑用
aof模式
- 效率上考虑用
数据持久化的配置项
1 | 设置rdb的同步频率(设置为save ""表示关闭rdb同步方式) |
Redis开发
redis开发库有很多,有官方的有第三方的,支持各种语言,在官网有罗列(点击跳转)
此处以C语言的库HIREDIS作为选择
HIREDIS库
hiredis API接口的使用
连接数据库
1 | // 连接数据库 |
redisContext结构体
1 | typedef struct redisContext { |
执行redis命令函数
1 | // 执行redis命令 |
返回值指向的结构
1 | // redisCommand 函数实际的返回值类型 |
type的类型盘点
| 状态 | 表示含义 |
|---|---|
| REDIS_REPLY_STRING==1 | 返回值是字符串,字符串储存在redis->str当中,字符串长度为redis->len |
| REDIS_REPLY_ARRAY== 2 | 返回值是数组,数组大小存在redis->elements里面,数组值存储在redis->element[i]里面。数组里面存储的是指向redisReply的指针,数组里面的返回值可以通过redis->element[i]->str来访问,数组的结果里全是type==REDIS_REPLY_STRING的redisReply对象指针。 |
| REDIS_REPLY_INTEGER== 3 | 返回整数long long,从integer字段获取值 |
| REDIS_REPLY_NIL==4 | 返回值为空表示执行结果为空 |
| REDIS_REPLY_STATUS==5 | 返回命令执行的状态,比如set foo bar返回的状态为OK,存储在str当中 reply->str == "OK" 。 |
| REDIS_REPLY_ERROR ==6 | 命令执行错误,错误信息存放在 reply->str当中。 |
释放资源
1 | //释放放回结果 |
测试案例
1 |
|
sql server相关
sql server配置
此处记录win11下配置sql server的操作流程
1 | 安装好镜像后 |
| 参数 | 说明 |
|---|---|
-e "ACCEPT_EULA=Y" |
将 ACCEPT_EULA 变量设置为任意值,以确认接受最终用户许可协议,是 SQL Server 映像的必需设置。 |
-e "MSSQL_SA_PASSWORD=<YourStrong@Passw0rd>" |
指定至少包含 8 个字符且符合密码策略的强密码,是 SQL Server 映像的必需设置。 |
-e "MSSQL_COLLATION=<SQL_Server_collation>" |
指定自定义 SQL Server 排序规则,可不使用默认值 SQL_Latin1_General_CP1_CI_AS。 |
-p 1433:1433 |
将主机环境中的 TCP 端口映射到容器中的 TCP 端口,在此例中,SQL Server 侦听容器中的 TCP 1433,此容器端口会对主机上的 TCP 端口 1433 公开。 |
--name sql1 |
为容器指定自定义名称,若运行多个容器,不能重复使用相同名称。 |
--hostname sql1 |
用于显式设置容器主机名,未指定则默认为随机生成的系统 GUID。 |
-d |
在后台运行容器(守护程序)。 |
mcr.microsoft.com/mssql/server:2022-latest |
SQL Server Linux 容器映像。 |
默认情况下,密码必须设置为至少八个字符且包含以下四种字符中的三种:大写字母、小写字母、十进制数字、符号
sudo /opt/mssql-tools/bin/sqlcmd -S localhost -U <userid> -P "<YourNewStrong@Passw0rd>" 登录进sql server
查看容器的ip地址使用这句命令:docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' 容器名/容器id
新建好的数据库默认只能使用身份验证模式启动
需要使用SSMS通过身份验证模式连接上数据库,在右键-属性-安全性中,有服务器身份验证,选择”SQL Server和Windows身份验证模式(S)”
启用sa账户: 在树形图中的安全性-登录名中找到sa账户,右键属性中可以启用
用户名的密码可以在树形图中的安全性-登录名中具体登录名右键属性中修改
连接上数据库后用此命令修改也可以
ALTER LOGIN sa WITH PASSWORD = 'new_password';启动远程连接需要打开sql server配置管理器,找到MSSQLSERVER 的协议,右键TCP/IP选择”启用”.事后要重启SQL server服务
Ubuntu:在 Linux 上安装 SQL Server - SQL Server | Microsoft Learn
【自学笔记】在SQL Server中创建用户角色及授权(使用SQL语句)更新2023.07.06_sqlserver创建用户并授权-CSDN博客
快速入门:使用 SSMS 备份和还原数据库 - SQL Server | Microsoft Learn
备份与还原
- 完全备份full backup
- 备份全部选中的数据库
- 完全拷贝
- 清除存档属性
- 差异备份 differential backup
- 自上一次完全备份之后有变化的数据作为备份的对象
- 时间段,节省磁盘空间
完全备份 + 最近一次的差异备份就可以将系统恢复
- 增量备份 incremental backup
- 备份自上一次备份(完全/差异/增量备份)之后有变化的数据
- 清除存档属性
- 没有重复的备份数据
- 数据量不大,备份时间短
组合使用方式
完全备份 + 差异备份: 周一全备,其他日子差异备份
若数据在周五被破坏,只需要还原周一完备和周四差异备份
完全备份 + 增量备份: 周一全备,其他日子差异备份
若数据在周五被破坏,需要还原周一完备和周二到周五所有增量备份
紧急情况下的数据恢复
若数据库已损坏或无法访问,且无任何备份,需借助第三方工具或专业服务:
适用工具推荐(支持无备份恢复):
- Recovery for SQL Server
- 直接扫描 MDF/LDF 文件提取数据,支持导出为 SQL 脚本
- 免费试用版可恢复小规模数据(≤24GB)
- Stellar Repair for SQL Server
- 修复损坏的数据库文件,提取未备份的数据
- 专业数据恢复服务
- 适用于物理磁盘损坏或严重数据损坏场景,需付费且成功率非100%
备份与还原bak文件
备份流程
- 打开SQL Server客户端,选中数据库,鼠标右键选择 任务 > 备份,操作备份
- 在备份页面指定bak文件路径存放路径,默认是数据库路径,可以自行指定。其他默认是完整备份,单击 确定
还原流程
打开SQL Server客户端,选中数据库,鼠标右键单击 任务 > 还原,操作还原
单击数据库,在此页面选择源设备,单击右侧【…】按钮,在指定备份单击 添加,选择保存的bak文件,单击 确定
勾选覆盖现有数据库,单击 确定


数据库映射技术ORM
ORM对象关系映射是指将应用程序中的对象模型(通常是面向对象的模型)与数据库中的关系模型进行映射的过程。简单来说,ORM是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系数据库中

常见的数据库映射技术包括对象关系映射(ORM)框架,如
- [[CSharp入门#CSharp Entity Framework|Entity Framework Core(在.NET平台上)]]
- NHibenate(在Java平台上),年代久远
- SqlSugger(当下比较流行)
- Dapper(半ORM)
- MyBatis.Net(需要写一大堆的XML,里面要写sql语句)
- MyBatisPlus(Java开发最流行)
这些ORM框架提供了便捷的方式来映射数据库表和对象之间的关系,简化了数据访问层的开发工作。
使用方式实例可以参考[[CSharp入门#CSharp Entity Framework|CSharp Entity Framework]]
ORM能解决下面的问题:
- SQL语法学习
- 开发效率低
- 字段重命名,需要挨个地方修改
- 数据库更换,如SQLServer更换为MySQL数据库,SQL语句不同,有兼容性问题
ORM的底层会通过反射帮我们生成数据库能够执行的SQL语句
缺点:
降低了系统的执行效率
遇到复杂的查询时显得有些吃力
基本ORM框架也支持直接执行sql语句
写时复制和事务处理
大部分数据库都支持的操作
写时复制
核心思想
- 当需要对数据进行修改时,不直接修改原始数据,而是先复制一份数据的副本,在副本上进行修改。
- 只有在真正需要修改时才进行数据的复制,这样可以延迟复制操作,提高性能。
步骤
- 读取阶段:多个事务可以并发地读取同一个数据页或记录,不需要进行复制操作。
- 写入阶段:当事务尝试修改数据时,先将需要修改的数据页或记录复制到一个新位置(副本)。
- 提交阶段:事务成功后,新副本替代原始数据,未被提交的修改则会被丢弃。
优点
- 多版本并发控制 (MVCC):允许读写事务并发执行,读操作不会阻塞写操作。
- 减少锁争用:读事务不需要加锁,因为读取的是快照数据。
- 提高可靠性:原始数据在未确认修改前保持不变,减少数据损坏的风险。
应用场景
- PostgreSQL 的 MVCC 实现:每次写操作会创建一个数据的版本,未提交的事务可以访问旧版本。
- 文件系统(如 ZFS 和 Btrfs):写时复制用于实现快照和可靠的数据存储。
事务处理原理
数据库中的事务(Transaction)是逻辑上的一组操作,它们要么全部成功(提交),要么全部失败(回滚)。事务处理的核心是保证ACID属性:
ACID 属性
- Atomicity(原子性):事务中的所有操作要么全部完成,要么全部不执行。
- Consistency(一致性):事务执行前后,数据库必须处于一致状态。
- Isolation(隔离性):事务的执行不被其他事务干扰,即使是并发事务也要表现为独立运行。
- Durability(持久性):事务提交后,其对数据库的修改永久生效,即使发生系统崩溃。
事务处理机制
事务日志 (WAL, Write-Ahead Logging):
WAL (Write-Ahead Logging):
在事务修改数据之前,先将修改记录写入日志。
如果事务失败,系统可以通过日志回滚未完成的操作。
Undo Log:
记录数据被修改前的旧值。
回滚时用旧值还原数据。
回滚机制
在事务失败或中止时,根据 Undo Log 将数据库状态恢复到事务开始前的状态。
锁机制:
共享锁(S 锁):
用于读操作,多个事务可以同时持有。
排他锁(X 锁):
用于写操作,确保只有一个事务能够修改数据。
多粒度锁:
锁的粒度可以是行、页、表或整个数据库,以平衡并发性能和隔离性。
两阶段锁协议(2PL):
- 在事务中分为加锁阶段和解锁阶段。
- 事务在执行时先加锁,直到事务提交或回滚后才释放所有锁。
MVCC(多版本并发控制):
通过保存不同版本的数据实现读写并发分离。
- 数据库为每个事务维护数据的多个版本。
- 读操作访问旧版本数据,写操作创建新版本,互不冲突。
检查点:
- 定期将日志的部分内容刷入磁盘,减少恢复时间。
事务的状态
- Active(活动状态):事务开始执行,但未完成。
- Partially Committed(部分提交):事务所有操作执行完成,但尚未写入磁盘。
- Failed(失败状态):事务因某种原因失败,需要回滚。
- Aborted(中止状态):事务已经回滚,数据恢复到事务开始时的状态。
- Committed(已提交):事务成功结束,所有修改永久生效。
事务隔离级别
数据库使用隔离级别来控制并发事务的相互影响,共有以下四种隔离级别(从低到高):
- Read Uncommitted(读未提交):事务可以读取未提交的数据,存在脏读问题。
- Read Committed(读已提交):只能读取已提交的数据,避免脏读。
- Repeatable Read(可重复读):同一事务中多次读取结果一致,避免不可重复读。
- Serializable(可串行化):最高隔离级别,事务按串行顺序执行,避免幻读。
数据库相关课程介绍

数据库开发技巧盘点
仓储模式
仓储模式是一种将数据访问逻辑与业务逻辑分离的设计模式。它提供了一个抽象层,使得应用程序可以通过仓储接口与数据源(如数据库)进行交互,而无需直接与数据库的具体实现打交道。
主要特点:
- 抽象化数据访问:通过定义接口来隐藏数据访问的细节,客户端只需了解接口即可。
- 集中管理数据访问逻辑:所有与数据相关的操作(如增、删、改、查)都集中在仓储类中,便于维护和测试。
- 提高可测试性:可以使用模拟(Mock)对象来测试业务逻辑,而不需要连接到真实的数据库。
1 | public interface IProductRepository |
工作单元模式
工作单元模式是一种用于管理事务的设计模式。它将多个操作组合成一个事务,以确保这些操作要么全部成功,要么全部失败,从而保持数据的一致性。
- 事务管理:可以将多个数据库操作封装在一个工作单元中,确保它们在一个事务中执行。
- 减少数据库交互:在工作单元完成之前,不会将更改提交到数据库,减少了与数据库的交互次数。
- 集中控制:工作单元负责管理多个仓储的生命周期,使得数据的一致性和完整性更容易维护。
- 缓存仓储实例
1 | public interface IUnitOfWork : IDisposable |
通常仓储模式和工作单元模式是结合使用的。仓储负责具体的数据操作,而工作单元负责管理这些操作的事务
优秀的分层如下:
1 | Presentation Layer (Controllers) |
分页机制
在大数据量、高并发或用户交互频繁的场景下,分页机制是必要且关键的
主要有两种:
1 | -- 传统分页(低效) |
分页机制的潜在问题
性能陷阱
- 传统分页的瓶颈:使用
OFFSET分页时,如LIMIT 1000 OFFSET 50000,数据库仍需先扫描前50,000条数据,再跳过它们返回结果,效率低下。可通过 游标分页(Cursor Pagination)优化,例如基于有序字段(如WHERE id > 1000 LIMIT 100)。
- 传统分页的瓶颈:使用
数据一致性
动态数据的分页漂移:若分页过程中数据新增或删除,可能导致重复或遗漏。解决方案包括:
- 使用 时间戳或版本号 固定分页基准。
- 对实时性要求高的场景采用 流式传输(如WebSocket推送更新)。
不需要分页的情况如下:
- 数据量极小:例如内部管理后台的百条级数据,分页可能增加复杂度且收益有限。
- 导出类操作:用户明确需要全量数据导出时,直接返回CSV或Excel文件更合适。
- 实时分析场景:如监控仪表盘需实时聚合全量数据,分页可能破坏分析逻辑。
游标分页
游标分页(Cursor Pagination)
游标分页通过 WHERE 条件直接定位到起始位置,避免扫描无关数据
| 场景 | 游标分页 | 传统分页(OFFSET) |
|---|---|---|
| 性能 | ⭐⭐⭐⭐(极快) | ⭐⭐(慢,随 OFFSET 增大线性下降) |
| 数据一致性 | ⭐⭐⭐⭐(稳定) | ⭐⭐(可能漂移) |
| 支持跳页 | ❌ | ⭐⭐⭐⭐(支持) |
| 适用大数据量 | ⭐⭐⭐⭐ | ❌(性能差) |
优势
性能极高,避免全表扫描
1 | -- 查询 id > 10000 的前 10 条记录 |
数据库只需按索引快速定位到 id=10000,再扫描接下来的 10 条记录,时间复杂度从 O(N) 降为 O(1)
数据一致性更强
- 传统分页的“漂移”问题:
当分页过程中数据新增或删除时,OFFSET分页可能导致重复或遗漏。例如,第 1 页查询后新增一条数据,再查第 2 页时,原第 2 页的第一条数据会被挤到第 1 页末尾 - 游标分页的稳定性:
游标分页基于有序且唯一的字段(如时间戳、自增ID),每次分页的起始位置固定,不受其他数据变动影响
1 | -- 使用时间戳作为游标(假设数据按时间排序) |
适用于无限滚动和实时数据流
在移动端或社交媒体的信息流中,用户不断下拉加载新内容,游标分页通过传递
上一页的最后一个游标值,可实现无缝衔接。例如:
- 第 1 页返回数据:
[{id: 100}, {id: 99}, ..., {id: 91}],最后一个游标为91。 - 第 2 页请求:
WHERE id < 91 LIMIT 10,直接获取后续数据。
规避大数据量下的性能陷阱
当数据量达到百万级时,OFFSET 分页的查询时间可能从几毫秒飙升到数秒甚至超时,而游标分页的响应时间始终稳定
游标分页的适用场景
- 高并发读操作:如新闻、社交媒体、电商商品列表。
- 实时数据流:如聊天记录、日志监控、交易流水。
- 大数据量分页:避免
OFFSET的深度分页性能问题。
实现方法
选择游标字段
要求: 有序、唯一、不可变(如自增主键
id、时间戳created_at)1
2
3
4
5
6
7
8-- 使用自增主键作为游标
SELECT * FROM orders WHERE id > {last_id} ORDER BY id LIMIT 10;
-- 使用时间戳(需确保唯一性,可结合主键)
SELECT * FROM events
WHERE (created_at, id) > ('2023-10-01 12:00:00', 100)
ORDER BY created_at, id
LIMIT 10;前后端交互
- 请求参数:传递上一页的最后一个游标值(如
?cursor=100&limit=10)。 - 响应格式:返回数据列表及下一页的游标值:
1
2
3
4{
"data": [...],
"next_cursor": "100"
}- 请求参数:传递上一页的最后一个游标值(如
局限性
- 不支持随机跳页:用户只能按顺序翻页(上一页/下一页),无法直接跳转到第 N 页。
- 依赖有序字段:若无合适的游标字段(如非索引列),可能需改造表结构。
- 动态过滤条件:若分页需结合复杂查询条件(如搜索关键词),需确保游标字段与过滤条件兼容。