C++基础
C++基础
ZEROKO14C++概述
“c++”中的++来自于c语言中的递增运算符++,该运算符将变量加1。c++起初也叫”c with class”.通过名称表明,c++是对C的扩展,因此c++是c语言的超集,这意味着任何有效的c程序都是有效的c++程序。c++程序可以使用已有的c程序库。
库是编程模块的集合,可以在程序中调用它们。库对很多常见的编程问题提供了可靠的解决方法,因此可以节省程序员大量的时间和工作量。
$$
c++=c+泛型编程+面向对象
$$
c++融合了3种不同的编程方式:
- c语言代表的过程性语言.
- c++在c语言基础上添加的类代表的面向对象语言.
- c++模板支持的泛型编程。
可移植性和标准
程序是否可移植性有两个问题需要解决。第一是硬件,针对特定硬件编程的程序是不可移植的。第二,语言的实现
为了兼容需要制定标准
新特性标准排序:(时间排序)
- c++98 已有的c++特性+异常+运行阶段类型识别(RTTI)+模板+标准模板库([[STL]])
- c++11
- c++14
- c++17
对于传统的结构化语言,我们向来没有太多的疑惑,函数调用那么自然而明显,只是从程序的某一个地点调到另一个地点去执行。但是对于面向对象(OO)语言,我们疑惑就会很多。其原因就是c++编译器为我们程序员做了太多隐藏的工作:构造函数,析构函数、虚函数、继承、多态....有时候它为我们合成出一些额外的函数,有时候它又偷偷在我们写的函数里,放进更多的操作。有时候也会给我们的对象里放进一些奇妙的东西,使得我们sizeof的时候结果可我们预期不一样。
简单的c++程序
1 |
|
注意:
c++头文件为什么没有.h?
在c语言中头文件使用扩展名.h,将其作为一种通过名称标识文件类型的简单方式。但是c++得用法改变了,c++头文件没有扩展名。但是有些c语言的头文件被转换为c++的头文件,这些文件被重新命名,丢掉了扩展名.h(使之成为c++风格头文件),并在文件名称前面加上前缀c(表明来自c语言)。例如c++版本的math.h为cmath.
由于C使用不同的扩展名来表示不同文件类型,因此用一些特殊的扩展名(如hpp或hxx)表示c++的头文件也是可以的,ANSI/IOS标准委员会也认为是可以的,但是关键问题是用哪个比较好,最后一致同意不适用任何扩展名。
| 头文件类型 | 约定 | 示例 | 说明 |
|---|---|---|---|
| c++旧式风格 | 以.h结尾 | iostream.h | c++程序可用 |
| c旧式风格 | 以.h结尾 | math.h | c/c++程序可用 |
| c++新式风格 | 无扩展名 | iostream | c++程序可用,使用namespace std |
| 转换后的c | 加上前缀c,无扩展名 | cmath | c++程序可用,可使用非c特性,如namespace std |
using namespace std 是什么?
namespace是指标识符的各种可见范围。命名空间用关键字namespace 来定义。命名空间是C++的一种机制,用来把单个标识符下的大量有逻辑联系的程序实体组合到一起。此标识符作为此组群的名字。
面向过程思想
面向过程是一种以过程为中心的编程思想。
通过分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了。
面向过程编程思想的核心:功能分解,自顶向下,逐层细化(程序=[[数据结构]]+[[算法]])。
面向过程编程语言存在的主要缺点是不符合人的思维习惯,而是要用计算机的思维方式去处理问题,而且面向过程编程语言重用性低,维护困难。
面向对象思想
面向对象编程(Object-Oriented Programming)简称 OOP 技术,是开发计算机应用程序的一种新方法、新思想。过去的面向过程编程常常会导致所有的代码都包含在几个模块中,使程序难以阅读和维护。在做一些修改时常常牵一动百,使以后的开发和维护难以为继。而使用 OOP 技术,常常要使用许多代码模块,每个模块都只提供特定的功能,它们是彼此独立的,这样就增大了代码重用的几率,更加有利于软件的开发、维护和升级。
在面向对象中,[[算法]]与[[数据结构]]被看做是一个整体,称作对象,现实世界中任何类的对象都具有一定的属性和操作,也总能用[[数据结构]]与[[算法]]两者合一地来描述,所以可以用下面的等式来定义对象和程序:
$$
对象 = 算法 + 数据结构
$$
$$
程序 = 对象 + 对象 + ……
$$
面向对象编程思想的核心:应对变化,提高复用。
面向对象三大特性
封装特性
把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。
类将成员变量和成员函数封装在类的内部,根据需要设置访问权限,通过成员函数管理内部状态。
继承特性
继承所表达的是类之间相关的关系,这种关系使得对象可以继承另外一类对象的特征和能力。
继承的作用:避免公用代码的重复开发,减少代码和数据冗余。
多态特性
多态性可以简单地概括为“一个接口,多种方法”,字面意思为多种形态。程序在运行时才决定调用的函数,它是面向对象编程领域的核心概念。
C++对C的扩展
::作用域运算符
1 | //全局变量 |
通常情况下,如果有两个同名变量,一个是全局变量,另一个是局部变量,那么局部变量在其作用域内具有较高的优先权,它将屏蔽全局变量。
1 | //全局变量 |
这个例子可以看出,作用域运算符可以用来解决局部变量与全局变量的重名问题,即在局部变量的作用域内,可用::对被屏蔽的同名的全局变量进行访问。
无限定名字查找
如果::限定作用符左侧留空,只会在全局命名空间查找;::a
名字控制
创建名字是程序设计过程中一项最基本的活动,当一个项目很大时,它会不可避免地包含大量名字。c++允许我们对名字的产生和名字的可见性进行控制。
我们之前在学习c语言可以通过static关键字来使得名字只得在本编译单元内可见,在c++中我们将通过一种通过命名空间来控制对名字的访问。
C++命名空间(namespace)
作用:解决命名冲突
在c++中,名称(name)可以是符号常量、变量、函数、结构、枚举、类和对象等等。工程越大,名称互相冲突性的可能性越大。另外使用多个厂商的类库时,也可能导致名称冲突。为了避免,在大规模程序的设计中,以及在程序员使用各种各样的C++库时,这些标识符的命名发生冲突,标准C++引入关键字namespace(命名空间/名字空间/名称空间),可以更好地控制标识符的作用域。
命名空间使用语法
- 命名空间用途:解决名称冲突
- 命名空间下可以存放:变量,函数,结构体,类…
- 命名空间必须要声明在全局作用域
- 命名空间可以嵌套命名空间
- 命名空间是开放的,可以随时将新成员添加到命名空间下
- 命名空间是可以匿名的
创建一个命名空间:
1 | namespace A{ |
命名空间只能全局范围内定义(以下错误写法)
1 | void test(){ |
命名空间可嵌套命名空间
1 | namespace A{ |
命名空间是开放的,即可以随时把新的成员加入已有的命名空间中
1 | namespace A{ |
声明和实现可分离
1 |
|
1 | void MySpace::func1(){ |
无名命名空间,意味着命名空间中的标识符只能在本文件内访问,相当于给这个标识符加上了static,使得其可以作为内部连接
1 | namespace{ |
命名空间别名
1 | namespace veryLongName{ |
using声明
using声明可使得指定的标识符可用。
1 | namespace A{ |
using声明碰到函数重载
1 | namespace A{ |
如果命名空间包含一组用相同名字重载的函数,using声明就声明了这个重载函数的所有集合。
using编译指令
using编译指令使整个命名空间标识符可用.
1 | namespace A{ |
理解注意点:
- using声明和普通声明在一个作用域同时存在,会报错。但using编译指令和普通声明在一个作用域同时存在时,优先普通声明,若不存在普通声明,此时才使用使用的命名空间中的声明。
- 没有普通声明下,两个using编译指令会报错
注意:使用using声明或using编译指令会增加命名冲突的可能性。也就是说,如果有名称空间,并在代码中使用作用域解析运算符,则不会出现二义性。
我们刚讲的一些东西一开始会觉得难一些,这些东西以后还是挺常用,只要理解了它们的工作机理,使用它们非常简单。
需要记住的关键问题是当引入一个全局的using编译指令时,就为该文件打开了该命名空间,它不会影响任何其他的文件,所以可以在每一个实现文件中调整对命名空间的控制。比如,如果发现某一个实现文件中有太多的using指令而产生的命名冲突,就要对该文件做个简单的改变,通过明确的限定或者using声明来消除名字冲突,这样不需要修改其他的实现文件。
C++对C语言的增强以及扩展
全局变量检测增强
1 | int a = 10; //赋值,当做定义 |
此代码在c++下编译失败,在c下编译通过.
函数检测增强
1 | //i没有写类型,可以是任意类型 |
以上c代码c编译器编译可通过,c++编译器无法编译通过。
- 在C语言中,int fun() 表示返回值为int,接受任意参数的函数,int fun(void) 表示返回值为int的无参函数。(汇编本质并没有区别,编译器也不会报错,都是接受任意参数)
- 在C++ 中,int fun() 和int fun(void) 具有相同的意义,都表示返回值为int的无参函数。
类型转换检测增强
在C++,不同类型的变量一般是不能直接赋值的,需要相应的强转。
1 | typedef enum COLOR{ GREEN, RED, YELLOW } color; |
以上c代码c编译器编译可通过,c++编译器无法编译通过。
struct增强
- c中定义结构体变量需要加上struct关键字,c++不需要。
- c中的结构体只能定义成员变量,不能定义成员函数。c++即可以定义成员变量,也可以定义成员函数。
1 | //1. 结构体中即可以定义成员变量,也可以定义成员函数 |
bool数据类型扩展
标准c++的bool类型有两种内建的常量true(转换为整数1)和false(转换为整数0)表示状态。这三个名字都是关键字。
- bool类型只有两个值,true(1值),false(0值)
- bool类型占1个字节大小
- 给bool类型赋值时,非0值会自动转换为true(1),0值会自动转换false(0)
1 | void test() |
三目运算符增强
- c语言三目运算表达式返回值为数据值,为右值,不能赋值。
1 | int a = 10; |
- c++语言三目运算表达式返回值为变量本身(引用),为左值,可以赋值。
1 | int a = 10; |
C语言中(a > b ? &a :& b)等价于 C++中(a > b ? a : b)*
[左值和右值概念]
在c++中可以放在赋值操作符左边的是左值,可以放到赋值操作符右面的是右值。
有些变量即可以当左值,也可以当右值。
左值为Lvalue,L代表Location,表示内存可以寻址,可以赋值。
右值为Rvalue,R代表Read,就是可以知道它的值。
比如:int temp = 10; temp在内存中有地址,10没有,但是可以Read到它的值。
理解:
左值引用。编译器对他做的操作是“自动提领”,就是自动加个*操作。所以左值引用更像一个常量指针,int const,它和常量指针唯一的区别就在于他不用每次都让我们自己写了,除此以外真的没什么区别。
1 | int a=1; |
在这里a+b就是一个右值,它是活在寄存器里的一个值,他在内存里根本没有存在的位置,你无法对它取地址,这就是个右值。
C/C++中const的区别
C中的const
常量的引进是在c++早期版本中,当时标准C规范正在制定。那时,尽管C委员会决定在C中引入const,但是,他们c中的const理解为”一个不能改变的普通变量”,也就是认为const应该是一个只读变量,既然是变量那么就会给const分配内存,const修饰全局变量时默认是外部链接属性。
1 | const int arrSize = 10; |
看似是一件合理的编码,但是这将得出一个错误。 因为arrSize占用某块内存,所以C编译器不知道它在编译时的值是多少?
C++中的const
在c++中,一个const不一定创建内存空间,而在c中,一个const总是需要一块内存空间。
在c++中,是否为const常量分配内存空间依赖于如何使用。一般说来,如果一个const仅仅用来把一个名字用一个值代替(就像使用#define一样),那么该存储局空间就不必创建。
如果存储空间没有分配内存的话,在进行完数据类型检查后,为了代码更加有效,值也许会折叠到代码中。
不过,取一个const地址, 或者把它定义为extern,则会为该const创建内存空间。
在c++中,出现在所有函数之外的const作用于整个文件(也就是说它在该文件外不可见),默认为内部连接,c++中其他的标识符一般默认为外部连接。
C/C++中const异同总结
链接属性区别
- C语言默认外部链接(编译前自动加extern)
- C++默认内部链接(想要外部链接需要手动加extern)
当c语言两个文件中都有const int a的时候,编译器会报重定义的错误。而在c++中,则不会,因为c++中的const默认是内部连接的。如果想让c++中的const具有外部连接,必须显示声明为: extern const int a = 10;
修改区别
- C语言中const全局部变量直接修改编译失败,间接修改编译通过,但由于存储在只读数据段,运行失败
- C语言中const局部变量直接修改编译失败。但可以通过指针间接修改。
- C++中const全局变量与c一样
- C++中const局部变量直接修改编译失败,若分配了变量内存的话,可以通过指针间接修改,若未分配内存,则指针修改仅仅修改了一个临时内存空间中的值, 对原值不影响。
C++中const分配内存的情况
对于基础数据类型,也就是const int b = 10这种,编译器会把它放到符号表中,不分配内存,当对其取地址时,会分配临时内存。(无法间接修改原值)
1
2
3
4const int b=10;
int *p=(int*)&b;
*p=20;
cout<<"b="<<b<<endl;//显示为10,修改后无变化使用普通变量初始化const变量(可以间接修改原值)
1
2
3
4
5int a=10;
const int b=a;
int *p=(int*)&b;
*p=20;
cout<<"b="<<b<<endl;//修改成功自定义数据类型(可以间接修改原值)
1
2
3const Person p;
Person* pp=(Person*)&p;
pp->name="test";//修改成功
当上面未分配const变量内存的情况下,此时该const变量可以作为数组定义括号中的数值
1 | const int a=10; |
在支持c99标准的编译器中,可以使用变量定义数组。(2019VS都不支持完整的C99)
尽量以const替换#define
在旧版本C中,如果想建立一个常量,必须使用预处理器
1 |
我们定义的宏MAX从未被编译器看到过,因为在预处理阶段,所有的MAX已经被替换为了1024,于是MAX并没有将其加入到符号表中。但我们使用这个常量获得一个编译错误信息时,可能会带来一些困惑,因为这个信息可能会提到1024,但是并没有提到MAX.如果MAX被定义在一个不是你写的头文件中,你可能并不知道1024代表什么,也许解决这个问题要花费很长时间。
解决办法就是用一个常量替换上面的宏。
const int max= 1024;
const和#define区别总结:
- const有类型,可进行编译器类型安全检查。#define无类型,不可进行类型检查.
- const有作用域,而#define不重视作用域(虽然#undef A 可卸载宏常量A),默认定义处到文件结尾.如果定义在指定作用域下有效的常量,那么#define就不能用。
宏常量不可以有命名空间
1 | namespace MySpace { |
引用(reference)
引用基本用法
***引用是c++对c的重要扩充。***在c/c++中指针的作用基本都是一样的,但是c++增加了另外一种给函数传递地址的途径,这就是按引用传递(pass-by-reference),它也存在于其他一些编程语言中,并不是c++的发明。
- 变量名实质上是一段连续内存空间的别名,是一个标号(门牌号)
- 程序中通过变量来申请并命名内存空间
- 通过变量的名字可以使用存储空间
对一段连续的内存空间只能取一个别名吗?
c++中新增了引用的概念,引用可以作为一个已定义变量的别名。
基本语法:
$$
Type&\ ref = val;
$$
注意事项:
- &在此不是求地址运算,而是起标识作用。
- 类型标识符是指目标变量的类型
- 必须在声明引用变量时进行初始化。
- 引用初始化之后不能改变。
- 不能有NULL引用。必须确保引用是和一块合法的存储单元关联。
- 可以建立对数组的引用。
1 | //1. 建立数组引用方法一 |
函数中的引用
最常见看见引用的地方是在函数参数和返回值中。当引用被用作函数参数的时,在函数内对任何引用的修改,将对还函数外的参数产生改变。当然,可以通过传递一个指针来做相同的事情,但引用具有更清晰的语法。
如果从函数中返回一个引用,必须像从函数中返回一个指针一样对待。当函数返回值时,引用关联的内存一定要存在。
引用做参数
1 | //值传递 |
通过引用参数产生的效果同按地址传递是一样的。引用的语法更清楚简单:
- 函数调用时传递的实参不必加“&”符
- 在被调函数中不必在参数前加“*”符
引用作为其它变量的别名而存在,因此在一些场合可以代替指针。C++主张用引用传递取代地址传递的方式,因为引用语法容易且不易出错。
引用做返回值
- 不能返回局部变量的引用。
- 函数当左值,必须返回引用。
1 | //返回局部变量引用 |
引用的本质
引用的本质在c++内部实现是一个指针常量.
1 | Type& ref = val; // Type* const ref = &val; |
c++编译器在编译过程中使用常指针作为引用的内部实现,因此引用所占用的空间大小与指针相同,只是这个过程是编译器内部实现,用户不可见。
原理:
1 | //发现是引用,转换为 int* const ref = &a; |
指针引用
在c语言中如果想改变一个指针的指向而不是它所指向的内容,函数声明可能这样:
1 | void fun(int**); |
给指针变量取一个别名。
1 | Type* pointer = NULL; |
对于c++中的引用,语法清晰多了。函数参数变成指针的引用,用不着取得指针的地址。
常量引用
2
3
4
5
6
7
int main() {
print(42); // 💥 轰!编译器炸了
double pi = 3.14;
print(pi); // 💥 又炸了!
}上面的编译器连这么简单的代码都无法编译,意味着引用只能引用左值
常量引用应运而生,常量应用可以引用右值
它解决了两个关键问题:
- 可以接受右值(如字面量42)
- 可以接受不同类型(如double转int)
为什么呢?因为:
- const引用允许绑定到临时对象
- 编译器会自动创建临时变量进行类型转换
- 临时对象的生命周期会延长到引用作用域结束
常量引用的定义格式:
1 | const Type& ref = val; |
常量引用注意:
- 字面量不能赋给引用,但是可以赋给const引用(编译器自动给创建临时空间)
- const修饰的引用,不能修改。
1 | void test01(){ |
[const引用使用场景]
常量引用主要用在函数的形参,尤其是类的拷贝/复制构造函数。
将函数的形参定义为常量引用的好处:
- 引用不产生新的变量,减少形参与实参传递时的开销。
- 由于引用可能导致实参随形参改变而改变,将其定义为常量引用可以消除这种副作用。
1 | //const int& param防止函数中意外修改数据 |
如果希望实参随着形参的改变而改变,那么使用一般的引用,如果不希望实参随着形参改变,那么使用常引用。
对于非常量引用,必须将其绑定到一个具有持久性的左值,而不是一个临时值。这是因为非常量引用是为了能够修改引用的对象,而临时值是没有持久性的,无法被修改。
原因如下:
- 生命周期问题:临时值是暂时创建的,它们没有持久性,只在表达式求值时存在。一旦表达式结束,临时值就会被销毁。因此,在使用非常量引用时,我们需要确保引用的对象在引用的整个生命周期内是有效的,而不是在临时值消失后引用一个已销毁的对象。
- 修改限制:非常量引用的目的是允许对引用的对象进行修改。然而,临时值是常量对象,它们的值是不可修改的。因此,将非常量引用绑定到临时值上是没有意义的,因为我们无法通过引用修改临时值。
简单理解:
2
3
4
5
6
7
8
9
10
11
int maxProfit(const vector<int>& prices);
int res=s.maxProfit(vector<int>({7,1,5,3,6,4}));
//↑是允许的
//但是对于这样的函数(非常引用参数)
int maxProfit(vector<int>& prices);
int res=s.maxProfit(vector<int>({7,1,5,3,6,4}));//不允许
//只能这样:
vector<int> prices = {7,1,5,3,6,4};
s.maxProfit(prices);
引用和指针使用场景
- 如果这段关系”可能不存在” → 选指针(
T*) - 如果是”一定要在一起” → 选引用(
T&)
虽然可以强行给引用安排一个无效对象(Customer* p = nullptr; Customer& r = *p;),但这样做会把关系搞得一团糟(未定义行为)。要尊重引用的专一本性!
内联函数(inline function)
内联函数的引出
c++从c中继承的一个重要特征就是效率。假如c++的效率明显低于c的效率,那么就会有很大的一批程序员不去使用c++了。
在c中我们经常把一些短并且执行频繁的计算写成宏,而不是函数,这样做的理由是为了执行效率,宏可以避免函数调用的开销,这些都由预处理来完成。
但是在c++出现之后,使用预处理宏会出现两个问题:
- 第一个在c中也会出现,宏看起来像一个函数调用,但是会有隐藏一些难以发现的错误。
- 第二个问题是c++特有的,预处理器不允许访问类的成员,也就是说预处理器宏不能用作类类的成员函数。
1 |
|
为了保持预处理宏的效率又增加安全性,而且还能像一般成员函数那样可以在类里访问自如,c++引入了内联函数(inline function).
内联函数为了继承宏函数的效率,没有函数调用时开销,然后又可以像普通函数那样,可以进行参数,返回值类型的安全检查,又可以作为成员函数。
注意: 编译器将会检查函数参数列表使用是否正确,并返回值(进行必要的转换)。这些事预处理器无法完成的。
内联函数基本概念
在c++中,预定义宏的概念是用内联函数来实现的,而内联函数本身也是一个真正的函数。内联函数具有普通函数的所有行为。唯一不同之处在于内联函数会在适当的地方像预定义宏一样展开,所以不需要函数调用的开销。因此应该不使用宏,使用内联函数。
在开启了优化选项后,编译器可能不会为一个内联甚至非内联的函数生成[[C语言入门#栈区(stack)|栈框架(汇编层面的调用栈)]],编译器可能使用很多优化技术消除这个构造
在普通函数(非成员函数)函数前面加上inline关键字使之成为内联函数。但是必须注意必须函数体和声明结合在一起,否则编译器将它作为普通函数来对待。(即在函数声明和实现同时加入关键字inline才被称为内联)
1 | //下面不是内联 |
内联函数的确占用空间,但是内联函数相对于普通函数的优势只是省去了函数调用时候的压栈,跳转,返回的开销。我们可以理解为内联函数是以空间换时间。
任何在类内部定义的函数自动成为内联函数。
内联函数和编译器
内联函数并不是何时何地都有效,为了理解内联函数何时有效,应该要知道编译器碰到内联函数会怎么处理?
对于任何类型的函数,编译器会将函数类型(包括函数名字,参数类型,返回值类型)放入到符号表中。同样,当编译器看到内联函数,并且对内联函数体进行分析没有发现错误时,也会将内联函数放入符号表。
当调用一个内联函数的时候,编译器首先确保传入参数类型是正确匹配的,或者如果类型不正完全匹配,但是可以将其转换为正确类型,并且返回值在目标表达式里匹配正确类型,或者可以转换为目标类型,内联函数就会直接替换函数调用,这就消除了函数调用的开销。假如内联函数是成员函数,对象this指针也会被放入合适位置。
类型检查和类型转换、包括在合适位置放入对象this指针这些都是预处理器不能完成的。
但是c++内联编译会有一些限制,以下情况编译器可能考虑不会将函数进行内联编译:
- 不能存在任何形式的循环语句
- 不能存在过多的条件判断语句
- 函数体不能过于庞大
- 不能对函数进行取址操作
内联仅仅只是给编译器一个建议,编译器不一定会接受这种建议,如果你没有将函数声明为内联函数,那么编译器也可能将此函数做内联编译。一个好的编译器将会内联小的、简单的函数。
函数的默认参数
c++在声明函数原型的时可为一个或者多个参数指定默认(缺省)的参数值,当函数调用的时候如果没有指定这个值,编译器会自动用默认值代替。
1 | void TestFunc01(int a = 10, int b = 20){ |
注意点:
- 函数的默认参数从左向右,如果一个参数设置了默认参数,那么这个参数之后的参数都必须设置默认参数。
- 如果函数声明和函数定义分开写,函数声明和函数定义不能同时设置默认参数(和上面内联知识点正好相反,内联要求声明和定义都要加inline)。
函数的占位参数
1 | void TestFunc01(int a,int b,int){ |
c++在声明函数时,可以设置占位参数。占位参数只有参数类型声明,而没有参数名声明。一般情况下,在函数体内部无法使用占位参数。
**占位符功能作用:**暂时基本没用,什么时候用,在后面我们要讲的操作符重载的后置++要用到这个.
函数重载(overload)
$$
能使名字方便使用,是任何程序设计语言的一个重要特征!
$$
同一个函数名在不同场景下可以具有不同的含义。
在传统c语言中,函数名必须是唯一的,程序中不允许出现同名的函数。在c++中是允许出现同名的函数,这种现象称为函数重载。
函数重载的目的就是为了方便的使用函数名。
函数重载并不复杂,等大家学完就会明白什么时候需要用到他们,以及是如何编译,链接的。
函数重载基本语法
实现函数重载的条件:
- 同一个作用域
- 参数个数不同
- 参数类型不同
- 参数顺序不同
1 | //1. 函数重载条件 |
1 | void myFunc(int a) |
注意: 函数重载和默认参数一起使用,需要额外注意二义性问题的产生。
1 | void MyFunc(string b){ |
为什么函数返回值不作为重载条件呢?
当编译器能从上下文中确定唯一的函数的时,如int ret = func(),这个当然是没有问题的。然而,我们在编写程序过程中可以忽略他的返回值。那么这个时候,一个函数为
void func(int x);另一个为int func(int x); 当我们直接调用func(10),这个时候编译器就不确定调用那个函数。所以在c++中禁止使用返回值作为重载的条件。
函数重载实现原理
编译器为了实现函数重载,也是默认为我们做了一些幕后的工作,编译器用不同的参数类型来修饰不同的函数名,比如void func(); 编译器可能会将函数名修饰成_func,当编译器碰到void func(int x),编译器可能将函数名修饰为_func_int,当编译器碰到void func(int x,char c),编译器可能会将函数名修饰为_func_int_char我这里使用”可能”这个字眼是因为编译器如何修饰重载的函数名称并没有一个统一的标准,所以不同的编译器可能会产生不同的内部名。
以下三个函数在linux下生成的编译之后的函数名为:
1 | void func(){} |
extern “C”浅析
在linux下测试
1 | c函数: void MyFunc(){} ,被编译成函数: MyFunc |
通过这个测试,由于c++中需要支持函数重载,所以c和c++中对同一个函数经过编译后生成的函数名是不相同的,这就导致了一个问题,如果在c++中调用一个使用c语言编写模块中的某个函数,那么c++是根据c++的名称修饰方式来查找并链接这个函数,那么就会发生链接错误,以上例,c++中调用MyFunc函数,在链接阶段会去找Z6Myfuncv,结果是没有找到的,因为这个MyFunc函数是c语言编写的,生成的符号是MyFunc。
那么如果我想在c++调用c的函数怎么办?
extern “C”的主要作用就是为了实现c++代码能够调用其他c语言代码。加上extern “C”后,这部分代码编译器按c语言的方式进行编译和链接,而不是按c++的方式。
例如如下情况,C++需要调用c语言函数:
1 | //test.h--头文件 |
终极解决方案:
作用:能区分C和C++的调用针对性加或不加extern “C”,并且省去每个函数都要加extern “C”的麻烦
MyModule.h
1 |
|
MyModule.c
1 |
|
类和对象
C和C++中struct区别
- c语言struct只有变量,而c++语言struct 既有变量,也有函数
- c语言中struct中的成员变量不能赋初值,C++中的struct中的成员变量可以
类的封装
把事物的属性和行为表示出来,那么就可以抽象出来这个事物。
封装:
- 把变量(属性)和函数(操作)合成一个整体,封装在一个类中
- 对变量和函数进行访问控制
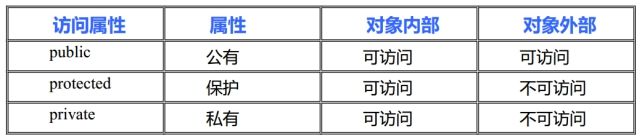
访问权限
- 在类的内部(作用域范围内),没有访问权限之分,所有成员可以相互访问
- 在类的外部(作用域范围外),访问权限才有意义:public,private,protected
- 在类的外部,只有public修饰的成员才能被访问,在没有涉及继承与派生时, private和protected是同等级的,外部不允许访问
[C++中struct和class的区别?]
class默认访问权限为private,struct默认访问权限为public.
尽量将成员变量设置为private
- 可赋予客户端访问数据的一致性。
如果成员变量不是public,客户端唯一能够访问对象的方法就是通过成员函数。如果类中所有public权限的成员都是函数,客户在访问类成员时只会默认访问函数,不需要考虑访问的成员需不需要添加(),这就省下了许多搔首弄耳的时间。
- 可细微划分访问控制
使用成员函数可使得我们对变量的控制处理更加精细。如果我们让所有的成员变量为public,每个人都可以读写它。如果我们设置为private,我们可以实现“不准访问”、“只读访问”、“读写访问”,甚至你可以写出“只写访问”。
对象的构造和析构
构造函数和析构函数,这两个函数将会被编译器自动调用,完成对象初始化和对象清理工作。
无论你是否喜欢,对象的初始化和清理工作是编译器强制我们要做的事情,即使你不提供初始化操作和清理操作,编译器也会给你增加默认的操作,只是这个默认初始化操作不会做任何事,所以编写类就应该顺便提供初始化函数。
构造函数和析构函数
构造函数主要作用在于创建对象时为对象的成员属性赋值,构造函数由编译器自动调用,无须手动调用。
析构函数主要用于对象销毁前系统自动调用,执行一些清理工作(例如成员变量有存堆区指针,那么堆区空间由析构函数中释放最合适了)。
构造函数语法:
- 构造函数函数名和类名相同,没有返回值,不能有void,但可以有参数,可以重载。
- ClassName(){}
析构函数语法:
- 析构函数函数名是在类名前面加”~”组成,没有返回值,不能有void,不能有参数,不能重载。
~ClassName(){}
构造函数的分类及调用
- 按参数类型:
- 无参构造函数
- 有参构造函数
- 按类型分类:
- 普通构造函数
- 拷贝构造函数(复制构造函数)
1 | class Person{ |
无参构造调用方式注意点:(重点)
- 正确方式:
Person person1; - 错误方式:
Person person1();//会被误认为是函数声明
引申出来的情况如下:(当使用父类指针指向子类对象的时候)
1 | //举个例子:ITestOutput是纯虚类(接口),也是TestOutput的父类 |
有参构造调用方法
Person person01(100);Person person02(person01);Person person03 = Person(300);Person person04 = 100;(不推荐)Person person05 = person04;
1 | //1. 无参构造调用方式 |
[注意事项1]
除了匿名构造外,其他情况析构都是在作用域尾执行。
1 | //匿名构造情况 |
[注意事项2]
b为A的实例化对象,A a = A(b) 和 A(b)的区别?
当A(b) 有变量来接的时候,那么编译器认为他是一个匿名对象,当没有变量来接的时候,编译器认为你A(b) 等价于 A b.
拷贝构造函数初始化匿名对象汇编层面上实际并没有调用拷贝构造函数,而是调用的无参构造函数。(避免这种用法)
1 | Person p;//正常调用无参构造函数的方法 |
[注意事项3]
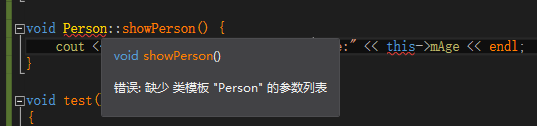
不存在参数类实例本身的构造函数,即不存在如下构造函数:
1 | Person(Person person) |
报错显示:”Person” 的复制构造函数不能带有 “Person” 类型的参数
从理解上来看,上面代码段中的参数传参为值传递,而在C++中,类对象的值传递本质上调用的就是拷贝构造函数,则会产生一个无限递归,因此必须要报错。(下面调用时机处是对这个理解的更深理解)
析构函数的调用时机
- 对象在栈上,生命周期结束的时候系统会自动调用析构函数。
- 对象在堆上,系统不会自动调用析构函数,必须见到delete。
- 对象生命周期结束,被销毁时;
- 主动调用delete ;
- 对象i是对象o的成员,o的析构函数被调用时,对象i的析构函数也被调用。
如果是new的对象,即使离开了作用域也会一直存在,必须主动delete,否则只有在结束程序时才会执行析构。(虽然离开了作用域,但用new动态开辟空间的对象是不会析构的,你可以观察任务管理器,看到内存一直在上升。但你在其他地方确无法使用a所开辟的空间,因为a这个指针是保存在栈上的,当离开作用域后就自动析构(或者说自动消失了),但它所在分配空间是分配在堆上的,只有主动析构或程序结束,才会释放空间,也就是丢失了这块空间的地址,无法操作这块空间了 。)
对不是new的对象的析构函数和return打断点,可以发现是先返回值后调用析构函数。
显示调用析构函数不但不会带来任何好处,还会造成很多奇怪、难以分析的问题
- 手动析构 == 调用函数
- 自动析构 == 调用函数同时销毁本身,后一个行为由系统完成,用户不能参与
我们构造对象,往往都是在一段语句体中,比如函数,判断,循环,还有就直接被一对“{}”包含的语句体。这个对象在语句体中被创建,在语句体结束的时候被销毁。问题就在于,这样的对象在生命周期中是存在于栈上的。也就是说,如何管理,是系统完成而程序员不能控制的。所以,即使我们调用了析构,在对象生命周期结束后,系统仍然会再调用一次析构函数,将其在栈上销毁,实现真正的析构。所以,如果我们在析构函数中有清除堆数据的语句,调用两次意味着第二次会试图清理已经被清理过了的,根本不再存在的数据!这是件会导致运行时错误的问题,并且在编译的时候不会告诉你!
显示调用析构带来的后果
- 显式调用的时候,析构函数相当于的一个普通的成员函数;
- 编译器隐式调用析构函数,如分配了堆内存,显式调用析构的话引起重复释放堆内存的异常;
- 把一个对象看作占用了部分栈内存,占用了部分堆内存(如果申请了的话),这样便于理解这个问题,系统隐式调用析构函数的时候,会加入释放栈内存的动作(而堆内存则由用户手工的释放);用户显式调用析构函数的时候,只是单纯执行析构函数内的语句,不会释放栈内存,也不会摧毁对象。
析构函数与异常
异常抛出且被捕获时,编译器会触发「栈展开(stack unwinding)」过程:从异常抛出点开始,逐层销毁当前调用栈上已构造的栈对象(自动对象),也就是依次调用这些对象的析构函数,直到找到匹配的catch块为止。这是 C++ 保证资源不泄漏的关键机制
析构函数仅对「已完成构造」的对象生效
但在一些场景下,析构函数不被调用
构造函数中抛出异常
析构函数仅对已完全构造的对象调用。如果对象的构造函数抛出异常,说明对象未完成构造,其析构函数不会执行(但构造过程中已初始化的成员对象仍会析构)
未捕获的异常(程序终止)
如果异常抛出后没有任何
catch块捕获,程序会调用std::terminate()直接终止,此时栈展开可能无法完成,析构函数不会被调用手动调用
abort()/exit()终止程序如果在异常处理过程中调用
std::abort()、exit()等函数,程序会直接终止,栈展开停止,析构函数不执行
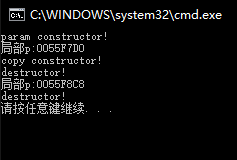
拷贝构造函数的调用时机
- 对象以值传递的方式传给函数参数
- 函数局部对象以值传递的方式从函数返回(vs debug模式下调用一次拷贝构造,[[qt]]不调用任何构造)
- 用一个对象初始化另一个对象
1 | class Person{ |
1 | //2. 传递的参数是普通对象,函数参数也是普通对象,传递将会调用拷贝构造 |
输出结果:

1 | //3. 函数返回局部对象 |
debug下生成:
release下生成:
[上面结果说明:]
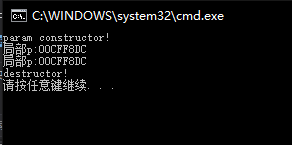
编译器存在一种对返回值的优化技术,RVO(Return Value Optimization).在vs debug模式下并没有进行这种优化,所以函数MyBusiness中创建p对象,调用了一次构造函数,当编译器发现你要返回这个局部的对象时,编译器通过调用拷贝构造生成一个临时Person对象返回,然后调用p的析构函数。
我们从常理来分析的话,这个匿名对象和这个局部的p对象是相同的两个对象,那么如果能直接返回p对象,就会省去一个拷贝构造和一个析构函数的开销,在程序中一个对象的拷贝也是非常耗时的,如果减少这种拷贝和析构的次数,那么从另一个角度来说,也是编译器对程序执行效率上进行了优化。
所以在这里,编译器偷偷帮我们做了一层优化:
当我们这样去调用: Person p = MyBusiness();
编译器偷偷将我们的代码更改为:
1 | void MyBussiness(Person& _result){ |
理解上就是编译器编译发布版本的时候直接改成了类对象的引用传递
【重点理解】
1 |
|
输出结果为:
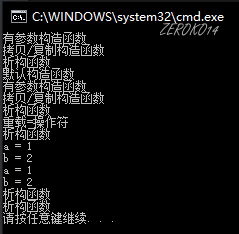
构造函数自动生成规则
- 默认情况下,c++编译器至少为我们写的类增加4个函数
- 默认构造函数(无参,函数体为空)
- 默认析构函数(无参,函数体为空)
- 默认拷贝构造函数,对类中非静态成员属性简单值拷贝
- 赋值运算符重载,operator=()函数。(定义时的=运算符调用的是拷贝构造之外,之后的=运算符调用的都是operator=()函数)
- 如果用户定义拷贝构造函数,c++不会再提供任何默认构造函数
- 如果用户定义了普通构造(非拷贝),c++不在提供默认无参构造,但是会提供默认拷贝构造
深拷贝和浅拷贝
浅拷贝
同一类型的对象之间可以赋值,使得两个对象的成员变量的值相同,两个对象仍然是独立的两个对象,这种情况被称为浅拷贝.
一般情况下,浅拷贝没有任何副作用,但是当类中有指针,并且指针指向动态分配的内存空间,析构函数做了动态内存释放的处理,会导致内存问题。
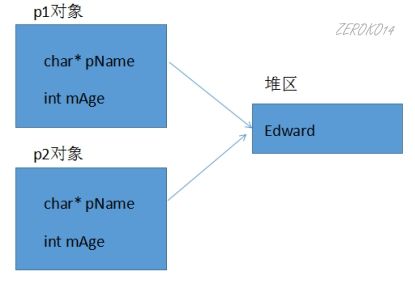
深拷贝
当类中有指针,并且此指针有动态分配空间,析构函数做了释放处理,往往需要自定义拷贝构造函数,自行给指针动态分配空间,深拷贝。
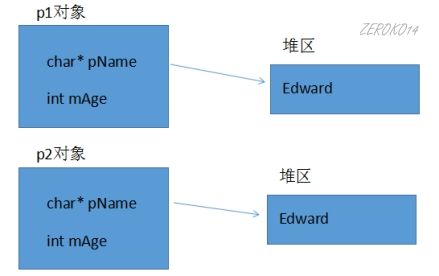
1 | class Person{ |
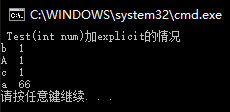
explicit关键字
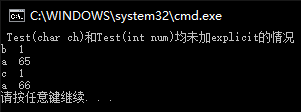
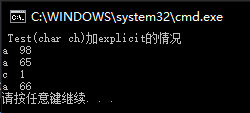
c++提供了关键字explicit(字面意思:更清晰的),禁止通过构造函数的隐式转换方式来构造对象。
- explicit常用于修饰构造函数,防止隐式转化调用构造函数产生的误解。
- 常针对单参数的构造函数(或者除了第一个参数外其余参数都有默认值的多参构造)而言。
1 | class Test |
上面例子可看出:explicit就是禁止用隐式方式来构造对象
1 | class Test |
各种情况的输出效果:
初始化列表
构造函数和其他函数不同,除了有名字,参数列表,函数体之外还有初始化列表。
1 | class Person{ |
***注意:***初始化成员列表(参数列表)只能在构造函数使用。
类对象作为成员
在类中定义的数据成员一般都是基本的数据类型。但是类中的成员也可以是对象,叫做对象成员。
C++中对对象的初始化是非常重要的操作,当创建一个对象的时候,c++编译器必须确保调用了所有子对象的构造函数。如果所有的子对象有默认构造函数,编译器可以自动调用他们。但是如果子对象没有默认的构造函数,或者想指定调用某个构造函数怎么办?
那么是否可以在类的构造函数直接调用子类的属性完成初始化呢?但是如果子类的成员属性是私有的,我们是没有办法访问并完成初始化的。
解决办法非常简单:对于子类调用构造函数,c++为此提供了专门的语法,即构造函数初始化列表。
当调用构造函数时,首先按各对象成员在类**定义中的顺序(和参数列表的顺序无关)**依次调用它们的构造函数,对这些对象初始化,最后再调用本身的函数体。也就是说,先调用对象成员的构造函数,再调用本身的构造函数。
析构函数和构造函数调用顺序相反,先构造,后析构。
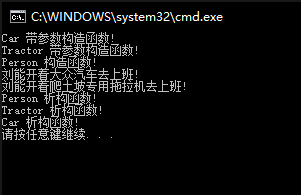
1 | //汽车类 |
输出结果:
动态对象创建
当创建一个c++对象时会发生两件事:
- 为对象分配内存
- 调用构造函数来初始化那块内存
第一步我们能保证实现,需要我们确保第二步一定能发生。c++强迫我们这么做是因为使用未初始化的对象是程序出错的一个重要原因。
C动态分配内存方法
为了在运行时动态分配内存,c在他的标准库中提供了一些函数,malloc以及它的变种calloc和realloc,释放内存的free,这些函数是有效的、但是原始的,需要程序员理解和小心使用。为了使用c的动态内存分配函数在堆上创建一个类的实例,我们必须这样做:
1 | class Person{ |
问题在于:
- 程序员必须确定对象的长度。
- malloc返回一个void指针,c++不允许将void赋值给其他任何指针,必须强转。
- malloc可能申请内存失败,所以必须判断返回值来确保内存分配成功。
- 用户在使用对象之前必须记住对他初始化,构造函数不能显示调用初始化(构造函数是由编译器调用),用户有可能忘记调用初始化函数。
c的动态内存分配函数太复杂,容易令人混淆,是不可接受的,c++中我们推荐使用运算符new 和 delete.
new operator
C++中解决动态内存分配的方案是把创建一个对象所需要的操作都结合在一个称为new的运算符里。当用new创建一个对象时,它就在堆里为对象分配内存并调用构造函数完成初始化。
1 | Person* person = new Person; |
New操作符能确定在调用构造函数初始化之前内存分配是成功的,所有不用显式确定调用是否成功。
现在我们发现在堆里创建对象的过程变得简单了,只需要一个简单的表达式,它带有内置的长度计算、类型转换和安全检查。这样在堆创建一个对象和在栈里创建对象一样简单。
malloc和new的区别
- malloc和free属于库函数,new和delete属于运算符
- malloc不会调用构造函数,new会调用构造函数
- malloc返回void* C++下要强转,new返回创建的对象的指针
placement new机制
一般来说,使用new申请空间时,是从系统的“堆”(heap)中分配空间。申请所得的空间的位置是根据当时的内存的实际使用情况决定的。但是,在某些特殊情况下,可能需要在已分配的特定内存创建对象,这就是所谓的“定位放置new”(placement new)操作。
定位放置new操作的语法形式不同于普通的new操作。例如,一般都用如下语句
A* p=new A;申请空间,而定位放置new操作则使用如下语句A* p=new (ptr)A;申请空间,其中ptr就是程序员指定的内存首地址。
- 用定位放置new操作,既可以在栈(stack)上生成对象,也可以在堆(heap)上生成对象。取决于ptr地址是指向哪里
- 使用语句A* p=new (mem) A;定位生成对象时,指针p和数组名mem指向同一片存储区。所以,与其说定位放置new操作是申请空间,还不如说是利用已经请好的空间,真正的申请空间的工作是在此之前完成的。
- 使用语句A *p=new (mem) A;定位生成对象时,会自动调用类A的构造函数,但是由于对象的空间不会自动释放(对象实际上是借用别人的空间),所以必须显示的调用类的析构函数,如本例中的
p->~A()。
如果有这样一个场景,我们需要大量的申请一块类似的内存空间,然后又释放掉,比如在在一个server中对于客户端的请求,每个客户端的每一次上行数据我们都需要为此申请一块内存,当我们处理完请求给客户端下行回复时释放掉该内存,表面上看者符合c++的内存管理要求,没有什么错误,但是仔细想想很不合理,为什么我们每个请求都要重新申请一块内存呢,要知道每一次内从的申请,系统都要在内存中找到一块合适大小的连续的内存空间,这个过程是很慢的(相对而言),极端情况下,如果当前系统中有大量的内存碎片,并且我们申请的空间很大,甚至有可能失败。为什么我们不能共用一块我们事先准备好的内存呢?可以的,我们可以使用placement new来构造对象,那么就会在我们指定的内存空间中构造对象。
这种方式存在的根本原因是因为内存申请是个耗时操作
1 |
|
delete operator
new表达式的反面是delete表达式。**delete表达式先调用析构函数,然后释放内存。**正如new表达式返回一个指向对象的指针一样,delete需要一个对象的地址。
delete只适用于由new创建的对象。
**如果使用一个由malloc或者calloc或者realloc创建的对象使用delete,这个行为是未定义的。**因为大多数new和delete的实现机制都使用了malloc和free,所以很可能没有调用析构函数就释放了内存。
如果正在删除的对象的指针是NULL,将不发生任何事,因此建议在删除指针后,立即把指针赋值为NULL,以免对它删除两次,对一些对象删除两次可能会产生某些问题。
1 | class Person{ |
用于数组的new和delete
使用new和delete在堆上创建数组非常容易。
1 | //创建字符数组 |
当创建一个对象数组的时候,必须对数组中的每一个对象调用构造函数,一般来说除了在栈上可以聚合初始化,必须提供一个默认的构造函数。
1 | class Person{ |
以下代码可以不强制在堆中生成数组对象时候类必须有默认构造函数(即不能是自己实现了有参数构造函数却没实现无参构造函数的情况)。
1 | Person* workers = new Person[2]{Person("john", 20), Person("Smith", 22)}; |
但是以上代码在部分编译器不支持(VS2015支持)。所以为了兼容性,最好提供一个默认构造函数,并且不使用上面语法。
[注意]
delete void*可能会出错
如果对一个void*指针执行delete操作,这将可能成为一个程序错误,除非指针指向的内容是非常简单的,因为它将不执行析构函数.以下代码未调用析构函数,导致可用内存减少。
1 | class Person{ |
因此,不要用void*去接受new出来的对象,利用void*无法调用析构函数。
使用new和delete采用相同形式
1 | Person* person = new Person[10]; |
以上代码有什么问题吗?(vs下直接中断、qt下析构函数调用一次)
使用了new也搭配使用了delete,问题在于Person有10个对象,那么其他9个对象可能没有调用析构函数,也就是说其他9个对象可能删除不完全,因为它们的析构函数没有被调用。
我们现在清楚使用new的时候发生了两件事: 一、分配内存;二、调用构造函数,那么调用delete的时候也有两件事:一、析构函数;二、释放内存。
那么刚才我们那段代码最大的问题在于:person指针指向的内存中到底有多少个对象,因为这个决定应该有多少个析构函数应该被调用。换句话说,person指针指向的是一个单一的对象还是一个数组对象,由于单一对象和数组对象的内存布局是不同的。更明确的说,数组所用的内存通常还包括“数组大小记录”,使得delete的时候知道应该调用几次析构函数。单一对象的话就没有这个记录。单一对象和数组对象的内存布局可理解为下图:
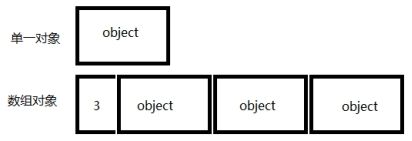
本图只是为了说明,编译器不一定如此实现,但是很多编译器是这样做的。
当我们使用一个delete的时候,我们必须让delete知道指针指向的内存空间中是否存在一个“数组大小记录”的办法就是我们告诉它。当我们使用delete[],那么delete就知道是一个对象数组,从而清楚应该调用几次析构函数。
结论:
如果在new表达式中使用[],必须在相应的delete表达式中也使用[].如果在new表达式中不使用[], 一定不要在相应的delete表达式中使用[].
嵌套类和局部类
嵌套类(在一个类中定义另一个类):
在C++语言中,嵌套类(nested class)其实与外围类没有什么太强的依赖关系 ,往往是因为外围类需要使用嵌套类对象作为底层实现,并且该嵌套类只用于外围类的实现,且同时可以对用户隐藏该底层实现时才使用嵌套类。(即作用总结:访问控制,限定嵌套类只能由这个类访问。)
局部类:在一个函数中定义另一个类
静态成员(static)
对static静态的理解
术语“static”有一段不同寻常的历史。起初,C引入关键字static是为了表示退出一个块后依然存在的局部变量。在这种情况下,术语”static”是有意义的:变量一直存在,当再次进入该块时仍然存在。随后,static在C中有了第二种含义,表示不能被其他文件访问的全局变量和函数。为了避免引入一个新的关键字,关键字static被重用了。最后,C++第三次重用了这个关键字,与前面赋予的含义完全不一样,这里将其解释为:属于类且不属于类对象的变量和函数。这个含义和Java相同。
静态成员变量
在一个类中,若将一个成员变量声明为static,这种成员称为静态成员变量。与一般的数据成员不同,无论建立了多少个对象,都只有一个静态数据的拷贝。静态成员变量,属于某个类,所有对象共享。
静态变量,是在编译阶段就分配空间,对象还没有创建时,就已经分配空间。
- 静态非常量成员变量必须在类中声明,在类外定义。(静态常量成员可以在类内一次性完成声明和定义)
- 静态数据成员不属于某个对象,编译阶段就分配内存,在为对象分配空间中不包括静态成员所占空间。
- 静态数据成员可以通过类名或者对象名来引用(两种访问方式)。
- 也有访问权限
1 | class Person{ |
**【注意】**由于静态空间的申请和初始化都在main之前,因此可以利用静态成员的类外定义来在main之前执行一些代码:
1 | int testfunc() |
静态成员函数
在类定义中,前面有static说明的成员函数称为静态成员函数。静态成员函数使用方式和静态变量一样,同样在对象没有创建前,即可通过类名调用。静态成员函数主要为了访问静态变量,但是,不能访问普通成员变量。
静态成员函数的意义:不在于信息共享,数据沟通,而在于管理静态数据成员,完成对静态数据成员的封装。
- 静态成员函数只能访问静态变量,不能访问普通成员变量
- 静态成员函数的使用和静态成员变量一样可以通过类或者对象访问
- 静态成员函数也有访问权限
- 普通成员函数可访问静态成员变量、也可以访问非静态成员变量
1 | class Person{ |
【注意】
静态成员函数不属于任何一个类对象,没有this指针,而非静态成员必须随类对象的产生而产生,所以静态成员函数”看不见”非静态成员,自然也就不能访问了
但是如果静态成员函数通过引用一个对象,是可以直接访问私有成员的,也体现了它成员函数的特权。
1 |
|
const静态成员属性
如果一个类的成员,既要实现共享,又要实现不可改变,那就用 static const 修饰。定义静态const数据成员时,最好在类内部初始化。
1 | class Person{ |
静态成员实现单例模式
单例模式是一种常用的软件设计模式。在它的核心结构中只包含一个被称为单例的特殊类。通过单例模式可以保证系统中一个类只有一个实例而且该实例易于外界访问,从而方便对实例个数的控制并节约系统资源。如果希望在系统中某个类的对象只能存在一个,单例模式是最好的解决方案。

Singleton(单例):在单例类的内部实现只生成一个实例,同时它提供一个静态的getInstance()工厂方法,让客户可以访问它的唯一实例;为了防止在外部对其实例化,将其默认构造函数和拷贝构造函数设计为私有;在单例类内部定义了一个Singleton类型的静态对象,作为外部共享的唯一实例。
关键点:
- 私有化默认构造函数,拷贝构造函数,唯一实例指针
- 对外提供getInstance接口,将指针返回
用单例模式,模拟公司员工使用打印机场景,打印机可以打印员工要输出的内容,并且可以累积打印机使用次数,案例如下:
1 | class Printer{ |
C++面向对象模型初探
成员变量和函数的存储
- c++中的非静态数据成员直接内含在类对象中,就像c struct一样。
- 成员函数(member function)虽然内含在class声明之内,却不出现在对象空间中。
- 每一个非内联成员函数(non-inline member function)只会诞生一份函数实例.
- 空类的sizeof结果为1
- 只有类中的非静态成员才真正占用对象空间,他们也要内存对齐(和结构体一样)
this指针
this指针工作原理
通过上例我们知道,c++的数据和操作也是分开存储,并且每一个非内联成员函数(non-inline member function)只会诞生一份函数实例,也就是说多个同类型的对象会共用一块代码
那么问题是:这一块代码是如何区分那个对象调用自己的呢?
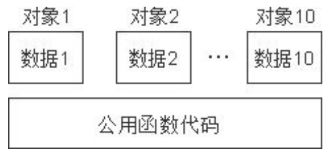
c++规定,this指针是隐含在对象成员函数内的一种指针。当一个对象被创建后,它的每一个成员函数都含有一个系统自动生成的隐含参数指针this,用以传入这个对象的地址,也就是说虽然我们没有写上this指针,编译器在编译的时候也是会加上的。因此this也称为“指向本对象的指针”,this指针并不是对象的一部分,不会影响sizeof(对象)的结果。
this指针是C++实现封装的一种机制,它将对象和该对象调用的成员函数连接在一起,在外部看来,每一个对象都拥有自己的函数成员。一般情况下,并不写this,而是让系统进行默认设置。
$$
this指针永远指向当前对象。
$$
成员函数通过this指针即可知道操作的是那个对象的数据。**This指针是一种隐含指针,它隐含于每个类的非静态成员函数中。**This指针无需定义,直接使用即可。
c++编译器对普通成员函数的内部处理的理解图

this指针的使用
- 当形参和成员变量同名时,可用this指针来区分(实际开发一般类中命名规范为m_xxx表示member_xxx避开命名冲突)
- 在类的非静态成员函数中返回对象本身,可使用return *this.
p.s. *this为对象本身
**【重点理解】**this案例:(内含链式编程思想)
1 |
|
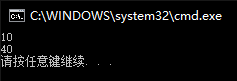
若将plusNum的返回值改成值传递:
1 | Test plusNum(int num)//返回对象 |
则
1 | void main() { |
结果为:
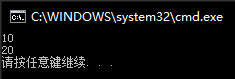
理解:对象的值赋值就是调用拷贝构造函数,从返回引用改成返回值后,实际上调用的是拷贝构造函数来生成了一个匿名对象,该匿名对象又调用plusNum函数返回值又因为调用拷贝构造函数生成另一个匿名对象…最终实际上,t1只进行了一次plusNum(10),后面的每次plusNum都是针对每次拷贝构造函数生成的匿名对象而非t1。
这里额外提一下,函数千万不要返回局部对象的引用或指针,因为该指针指向的空间已经被释放了,该指针为悬垂指针(指向曾经存在的对象,但该对象已经不再存在了,此类指针称为垂悬指针)
空指针访问成员函数
如果成员函数中没有用到this指针(直接用成员变量内部也会用到this指针),可以用空指针调用成员函数
可以给成员函数的this加判断,防止别人用空指针访问成员函数,如下:
1 | class Test |
常量关键词(const)
以下所有强调的直接修改对应的间接修改指的是通过指针来间接修改(可否间接修改参考之前const部分的内容)
const修饰成员函数
- 用const修饰的成员函数时,const修饰this指针指向的内存区域,常量成员函数体内不可以直接修改本类中的任何普通成员变量。
- 当成员变量类型符前用mutable(意思:可变的)修饰时例外。
定义方式:
1 | void 函数名() const; |
功能:常成员函数可以访问常对象中的数据成员,但仍然不允许修改没有mutable修饰的常对象中数据成员的值。
**[注意]**汇编本质就是函数传参的第一个参数改成了const,因此重写函数时候需要写上这个函数后的const
const修饰对象(常对象)
作用:使常对象中所有没有mutable修饰的成员变量不可直接修改
两种定义方式:
1 | 类名 const 对象名(实参列表); |
注意:
- 常对象不能调用该对象的非const型的成员函数(除了构造函数和析构函数)。
- 常对象可访问 const 或非 const 数据成员,不能直接修改,除非成员用mutable修饰
【个人理解】
常函数的本质是把本来由编译器暗中传入普通函数的类型名 const this在常函数中传入为**const 类型名 const this**。加多的const使this指向的内存不可直接修改了。
常对象的本质就是编译器限制对象调用普通成员函数,只能调用常函数。
【个人问题】mutable关键词实现原理?
友元
类的主要特点之一是数据隐藏,即类的私有成员无法在类的外部(作用域之外)访问。但是,有时候需要在类的外部访问类的私有成员,怎么办?
解决方法是使用友元函数,友元函数是一种特权函数,c++允许这个特权函数访问私有成员。
开发中,线程回调函数需要访问类中静态成员,往往使用友元函数或者静态成员函数(该函数要更麻烦些).
友元语法
- friend关键字只出现在声明处
- 其他类、类成员函数、全局函数都可声明为友元
- 友元函数不是类的成员,不带this指针
- 友元函数可访问对象任意成员属性,包括私有属性
- 若A类是B类的友元类,则A类的所有成员函数都是B类的友元函数
1 | class Building; |
[友元类注意]
- 友元关系不能被继承。
- 友元关系是单向的,类A是类B的朋友,但类B不一定是类A的朋友。
- 友元关系不具有传递性。类B是类A的朋友,类C是类B的朋友,但类C不一定是类A的朋友。
- static和friend不能同时存在,简单的说friend static声明全局函数时, friend会默认函数为extern的, 和后面的static冲突. static friend违法标准规定friend声明前不能加存储类型关键字的规定.
c++是纯面向对象的吗?
如果一个类被声明为friend,意味着它不是这个类的成员函数,却可以修改这个类的私有成员,而且必须列在类的定义中,因此他是一个特权函数。c++不是完全的面向对象语言,而只是一个混合产品。增加friend关键字只是用来解决一些实际问题,这也说明这种语言是不纯的。毕竟c++设计的目的是为了实用性,而不是追求理想的抽象。
尽量使用成员函数,除非不得已的情况下才使用友元函数。
什么时候使用友元函数:
- 运算符重载的某些场合需要使用友元。
- 两个类要共享数据的时候
综合训练(动态数组类)
省略...
运算符重载
运算符重载,就是对已有的运算符重新进行定义,赋予其另一种功能,以适应不同的数据类型。
$$
本质上,运算符重载(operator overloading)只是一种”语法上的方便”,也就是它只是另一种函数调用的方式。
$$
在c++中,可以定义一个处理类的新运算符。这种定义很像一个普通的函数定义,只是函数的名字由关键字operator及其紧跟的运算符组成。差别仅此而已。它像任何其他函数一样也是一个函数,当编译器遇到适当的模式时,就会调用这个函数。
基本语法:
定义重载的运算符就像定义函数,只是该函数的名字是operator@,这里的@代表了被重载的运算符。函数的参数中参数个数取决于两个因素。
- 运算符是一元(一个参数)的还是二元(两个参数);
- 运算符被定义为全局函数(对于一元是一个参数,对于二元是两个参数)还是成员函数(对于一元没有参数,对于二元是一个参数-此时该类的对象用作左耳参数)
有些人很容易滥用运算符重载。它确实是一个有趣的工具。但是应该注意,它仅仅是一种语法上的方便而已,是另外一种函数调用的方式。从这个角度来看,只有在能使涉及类的代码更易写,尤其是更易读时(请记住,读代码的机会比我们写代码多多了)才有理由重载运算符。如果不是这样,就改用其他更易用,更易读的方式。
对于运算符重载,另外一个常见的反应是恐慌:突然之间,C运算符的含义变得不同寻常了,一切都变了,所有C代码的功能都要改变!并非如此,对于内置的数据类型的表达式的的运算符是不可能改变的。(例如想重载int类型数据的+号)
可重载的运算符
几乎C中所有的运算符都可以重载,但运算符重载的使用时相当受限制的。特别是不能使用C中当前没有意义的运算符(例如用**求幂)不能改变运算符优先级,不能改变运算符的参数个数。这样的限制有意义,否则,所有这些行为产生的运算符只会混淆而不是澄清寓语意。

加号运算符重载
对于内置的数据类型,编译器知道如何进行运算,但是对于自定义的数据类型,编译器不知道如何运算。
实现加号运算符重载的两种方式:
成员函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class Test
{
public:
int a;
int b;
Test()
{
a = 0;
b = 0;
}
Test operator+(Test& test)//必须返回的是类本身,因为返回的是局部对象t,会调用拷贝构造函数(如果返回void的话就不能实现链式编程思路)
{
Test t;
t.a+=a+test.a;
t.b+=b+test.b;
return t;
}
};两种调用方式:
- t1.operator+(t2);
- t1+t2;
全局函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Test
{
public:
int a;
int b;
Test()
{
a = 0;
b = 0;
}
};
Test operator+(Test& test1,Test& tes2)//必须返回的是类本身,因为返回的是局部对象t,会调用拷贝构造函数
{
Test t;
t.a+=test1.a+tes2.a;
t.b+=test1.b+tes2.b;
return t;
}两种调用方式:
- operator+(t1,t2);
- t1+t2;
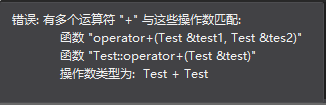
【注意】
全局方式和成员函数方式同时存在的时候不能用t1+t2的形式调用,因为具有二义性,编译器分不清
左移运算符<<重载
对于自定义数据类型,不能直接用”cout<<自定义对象”来输出,需要重载左移运算符<<
利用成员函数重载,无法实现让cout在左侧,因此我们不用成员函数重载
成员函数方式重载左移运算符:
1 | class Test |
两种调用方式:
- t1 << cout;(此处cout在右边,因此用成员函数来重载左移运算符的方式并不好)
- t1.operator<<(cout);
全局函数方式重载左移运算符
1 | class Test |
两种调用方式:
- operator<<(cout,t1);
- cout<<t1;
因此基本都是采用全局函数方式重载左移运算符。
因为是全局函数,所以访问类中私有数据要权限,解决方案:
- 将左移运算符全局重载函数设置为对应类的友元函数
- 给每个需要显示的私有变量设置公有的getXXX()函数
自增自减(++/–)运算符重载
重载的++和–运算符有点让人不知所措,因为我们总是希望能根据它们出现在所作用对象的前面还是后面来调用不同的函数。解决办法很简单,例如当编译器看到++a(前置++),它就调用operator++(a),当编译器看到a++(后置++),它就会去调用operator++(a,int).
1 | class Complex{ |
总结:

p.s. T表示任意类型
解读:
如果定义了++c,也要定义c++,递增操作符比较麻烦,因为他们都有前缀和后缀形式,而两种语义略有不同。重载operator++和operator–时应该模仿他们对应的内置操作符。
对于++和–而言,后置形式是先返回,然后对象++或者–,返回的是对象的原值。前置形式,对象先++或–,返回当前对象,返回的是新对象。其标准形式为上图
【注意】
调用代码时候,要优先使用前缀形式,除非确实需要后缀形式返回的原值,前缀和后缀形式语义上是等价的,输入工作量也相当,只是效率经常会略高一些,由于前缀形式少创建了一个临时对象。
【注意】
对于标准数据类型:前置可以嵌套多个前置,而后置只能一次。
重复嵌套后置递增或递减会报错,如下图:
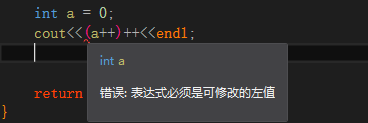
而对于我们上面自己实现的前后置重载,后置可以嵌套多层而没有语法错误,但是从第二次开始,运算的结果就已经存在临时对象中而不影响最初的对象。因此多次嵌套后置递增或递减也是没有意义的,要避免这样使用。
指针运算符(*、->)重载
这里为了描述指针运算符重载,引入智能指针的概念。
智能指针
- 用途:托管new出来的对象的释放,让其自动帮忙在声明周期结束时候释放堆区对象
- 设计smartPoint智能指针类别,内部维护Person*new出来的对象的指针,在析构的时候释放堆区new出来的person对象。
- 重载(、->),直接通过智能指针对象重载后的指针运算符(、->),操作原对象的成员函数。
案例如下:
1 | class Person{ |
为什么operator->()应该返回指针类型,是因为:
$$
p->m\qquad等价于\qquad(p.operator->())->m = 10
$$
指针运算符(*、->)重载必须是成员函数
【注意】两种一样的调用形式对比:
1 | pointer->PrintPerson();//pointer.operator->()->PrintPerson();(1号) |
对于->重载的理解,编译器会自动对pointer调用->重载函数再接->解析;
【注意】
上诉案例中的智能指针并不存在什么实际价值,因为每个类都要专门写对应的智能指针去处理,特别麻烦,在实际生产中还是自动手动调用delete释放。
赋值运算符=重载
必须是成员函数
1 | class Test |
即只有定义时候的=运算符调用的是拷贝构造函数。
默认提供的赋值运算符重载是浅拷贝。若类有用到堆区空间,应该实现成深拷贝。
1 | class Person{ |
两种调用方式:
- person1=person2;
- person1.operator=(person2);
理解链式调用赋值运算符=重载函数
person1=person2=person3;
类比如下代码:
1 | int a=3,b,c; |
因此person1=person2=person3;也是先调用person2=person3,然后person1=person3。
【重点】上面案例代码中对于赋值运算符重载的返回值类型的解读
下标运算符[]重载
实现访问数组时候利用[]访问元素
必须是成员函数
1 | //类内 |
关系运算符重载
对于自定义数据类型,编译器不知道如何进行比较
1 | //类内 |
函数调用运算符()重载
- 重载()
- 使用时候很像函数调用,因此称为仿函数
- 仿函数返回值和参数个数都不固定,很灵活
- 函数调用运算符必须是成员函数(只有当左操作数是一个基本类型对象时,才重载为全局函数)
- 使用情景:后面[[STL]]中大量用到!
1 | //类中 |
两种调用方式:
1 | 对象(); |
【注意】
1 | cout << MyAdd()(1,1) << endl;//MyAdd()是匿名函数对象,后面的括号表示匿名对象调用函数运算符重载函数 特点:当前行执行完立即释放 |
不要重载&&、||
不能重载operator&& 和 operator|| 的原因是:无法在这两种情况下实现内置操作符的完整语义。
内置版本版本特殊之处在于:内置版本的&&和||首先计算左边的表达式,如果这完全能够决定结果,就无需计算右边的表达式了–而且能够保证不需要。我们都已经习惯这种方便的特性了。
内置版本和重载后结果不一致的案例:
1 | class Complex{ |
根据内置&&的执行顺序,我们发现这个案例中执行顺序并不是从左向右,而是先右后左,这就是不满足我们习惯的特性了。由于complex1 += complex2先执行,导致complex1 本身发生了变化,初始值是0,现在经过+=运算变成1,1 && 1输出了真。(内置版本应该输出的是假)
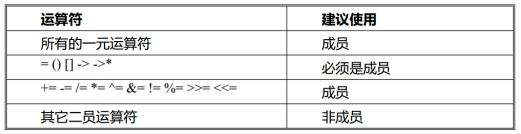
运算符重载总结
- =, [], () 和 -> 操作符只能通过成员函数进行重载
- << 和 >>只能通过全局函数配合友元函数进行重载
- 不要重载 && 和 || 操作符,因为无法实现短路规则
常规建议:
附录:运算符和结合性
| 优先级 | 运算符 | 名称或含义 | 使用形式 | 结合方向 | 说明 |
|---|---|---|---|---|---|
| 1 | [] | 数组下标 | 数组名[常量表达式] | 左到右 | – |
| () | 圆括号 | (表达式)/函数名(形参表) | – | ||
| . | 成员选择(对象) | 对象.成员名 | – | ||
| -> | 成员选择(指针) | 对象指针->成员名 | – | ||
| 2 | - | 负号运算符 | -表达式 | 右到左 | 单目运算符 |
| ~ | 按位取反运算符 | ~表达式 | |||
| ++ | 自增运算符 | ++变量名/变量名++ | |||
| – | 自减运算符 | –变量名/变量名– | |||
| ******* | 取值运算符 | *指针变量 | |||
| & | 取地址运算符 | &变量名 | |||
| ! | 逻辑非运算符 | !表达式 | |||
| (类型) | 强制类型转换 | (数据类型)表达式 | – | ||
| sizeof | 长度运算符 | sizeof(表达式) | – | ||
| 3 | / | 除 | 表达式/表达式 | 左到右 | 双目运算符 |
| ******* | 乘 | 表达式*表达式 | |||
| % | 余数(取模) | 整型表达式%整型表达式 | |||
| 4 | + | 加 | 表达式+表达式 | 左到右 | 双目运算符 |
| - | 减 | 表达式-表达式 | |||
| 5 | << | 左移 | 变量<<表达式 | 左到右 | 双目运算符 |
| >> | 右移 | 变量>>表达式 | |||
| 6 | > | 大于 | 表达式>表达式 | 左到右 | 双目运算符 |
| >= | 大于等于 | 表达式>=表达式 | |||
| < | 小于 | 表达式<表达式 | |||
| <= | 小于等于 | 表达式<=表达式 | |||
| 7 | == | 等于 | 表达式==表达式 | 左到右 | 双目运算符 |
| != | 不等于 | 表达式!= 表达式 | |||
| 8 | & | 按位与 | 表达式&表达式 | 左到右 | 双目运算符 |
| 9 | ^ | 按位异或 | 表达式^表达式 | 左到右 | 双目运算符 |
| 10 | | | 按位或 | 表达式|表达式 | 左到右 | 双目运算符 |
| 11 | && | 逻辑与 | 表达式&&表达式 | 左到右 | 双目运算符 |
| 12 | || | 逻辑或 | 表达式||表达式 | 左到右 | 双目运算符 |
| 13 | ?: | 条件运算符 | 表达式1?表达式2: 表达式3 | 右到左 | 三目运算符 |
| 14 | = | 赋值运算符 | 变量=表达式 | 右到左 | – |
| /= | 除后赋值 | 变量/=表达式 | – | ||
| = | 乘后赋值 | 变量*=表达式 | – | ||
| %= | 取模后赋值 | 变量%=表达式 | – | ||
| += | 加后赋值 | 变量+=表达式 | – | ||
| -= | 减后赋值 | 变量-=表达式 | – | ||
| <<= | 左移后赋值 | 变量<<=表达式 | – | ||
| >>= | 右移后赋值 | 变量>>=表达式 | – | ||
| &= | 按位与后赋值 | 变量&=表达式 | – | ||
| ^= | 按位异或后赋值 | 变量^=表达式 | – | ||
| |= | 按位或后赋值 | 变量|=表达式 | – | ||
| 15 | , | 逗号运算符 | 表达式,表达式,… | 左到右 | – |
继承
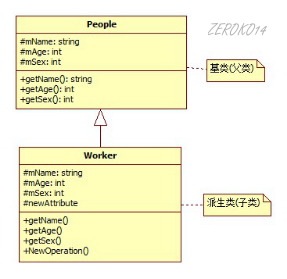
继承基本概念

c++最重要的特征是代码重用,通过继承机制可以利用已有的数据类型来定义新的数据类型,新的类不仅拥有旧类的成员,还拥有新定义的成员。
一个B类继承于A类,或称从类A派生类B。这样的话,类A成为基类(父类), 类B成为派生类(子类)。
派生类中的成员,包含两大部分:
- 一类是从基类继承过来的,一类是自己增加的成员。
- 从基类继承过过来的表现其共性,而新增的成员体现了其个性。
定义格式:
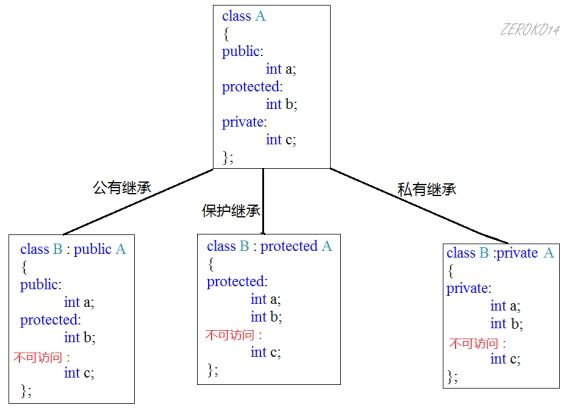
1 | Class 派生类名 : 继承方式 基类名{ |
三种继承方式:
- public:公有继承
- private:私有继承
- protected:保护继承
从继承源上分:
- 单继承:指每个派生类只直接继承了一个基类的特征
- 多继承:指多个基类派生出一个派生类的继承关系,多继承的派生类直接继承了不止一个基类的特征
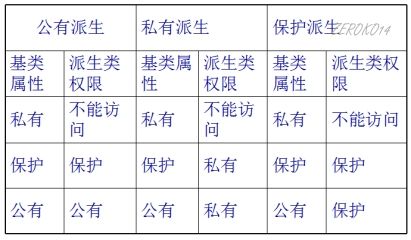
派生类访问控制
派生类继承基类,派生类拥有基类中全部成员变量和成员方法(除了构造和析构之外的成员方法),但是在派生类中,继承的成员并不一定能直接访问,不同的继承方式会导致不同的访问权限。
派生类的访问权限规则如下:
继承中的对象模型
父类中私有属性,子类是继承下去了,只不过由编译器给隐藏了,访问不到
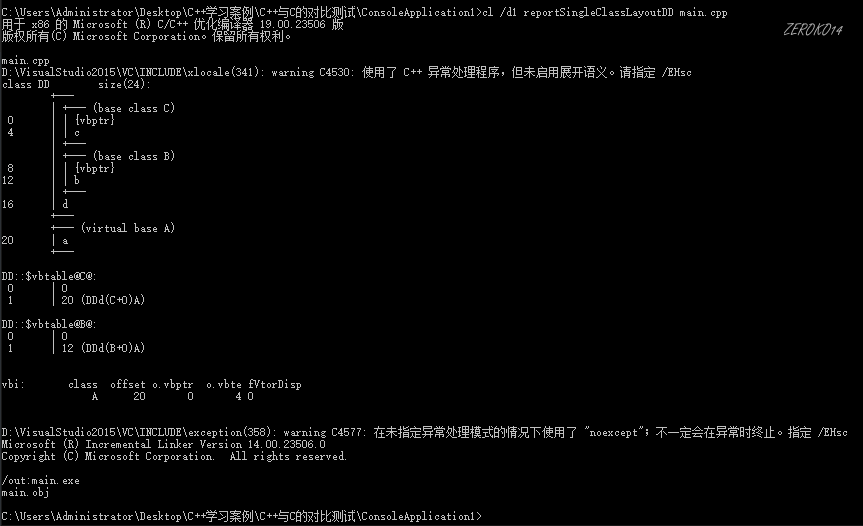
可以利用开发人员工具查看对象模型
vs2015的位置:C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio 2015\Visual Studio Tools\VS2015 开发人员命令提示.exe
跳转到项目路径下
查看对象模型:cl /d1 reportSingleClassLayout类名 文件名(注意:reportSingleClassLayout和类名之间没有空格)
class Father { int m_A; char m_B; }; class Son:public Father { int m_C; };1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
5. 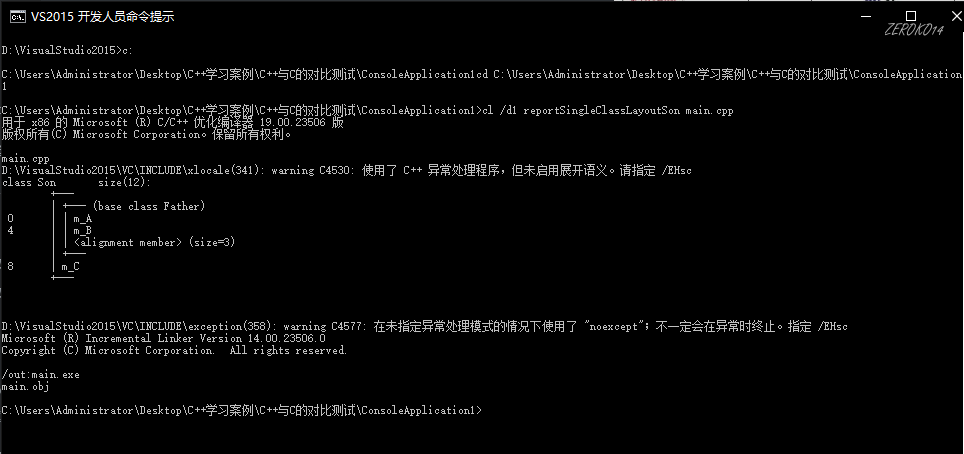
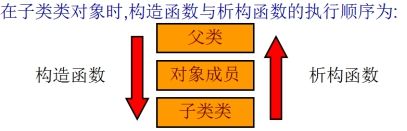
#### 继承中的构造和析构
- **先调用父类构造,再调用自身类中其他对象成员构造,再调用自身构造**,析构的顺序与构造相反
- 利用**初始化列表语法,显示调用父类中的其他构造函数**(不用初始化列表显示调用的情况下,系统默认调用无参构造函数)
- 父类中的**构造,析构,拷贝构造,operator=** 不会被子类继承下去的(在继承的过程中,如果没有创建这些函数,编译器会自动生成它们。)
***继承与对象嵌套混搭的构造和析构***
#### 继承中同名成员的处理方法
- 当子类成员和父类成员同名时,子类依然从父类继承同名成员
- 如果子类有成员和父类同名,子类访问其成员默认访问子类的成员(本作用域,**就近原则**)
- 在子类**通过作用域::进行同名成员区分**(在派生类中使用基类的同名成员,显示使用类名限定符)
继承中的同名成员函数要**【注意】**:
**任何时候重新定义基类中的一个重载函数,在子类的父类中所有重载版本都将被自动隐藏**,可以利用作用域显示指定调用
#### 继承中的静态成员特性
处理方式和非静态成员一致
只不过调用方式有两种
1. 通过对象
2. 通过类名(如:Son::Base::m_A,访问子类Son中父类作用域下的m_A静态成员变量)
#### 多继承
我们可以从一个类继承,我们也可以能同时从多个类继承,这就是多继承。但是由于多继承是非常受争议的,从多个类继承可能会导致函数、变量等同名导致较多的歧义。
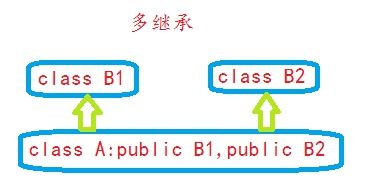
多继承会带来一些二义性的问题, 如果两个基类中有同名的函数或者变量,那么通过派生类对象去访问这个函数或变量时就不能明确到底调用从基类1继承的版本还是从基类2继承的版本?
解决方法就是显示指定调用那个基类的版本。
#### 菱形继承和虚继承
两个派生类继承同一个基类而又有某个类同时继承者两个派生类,这种继承被称为菱形继承,或者钻石型继承。
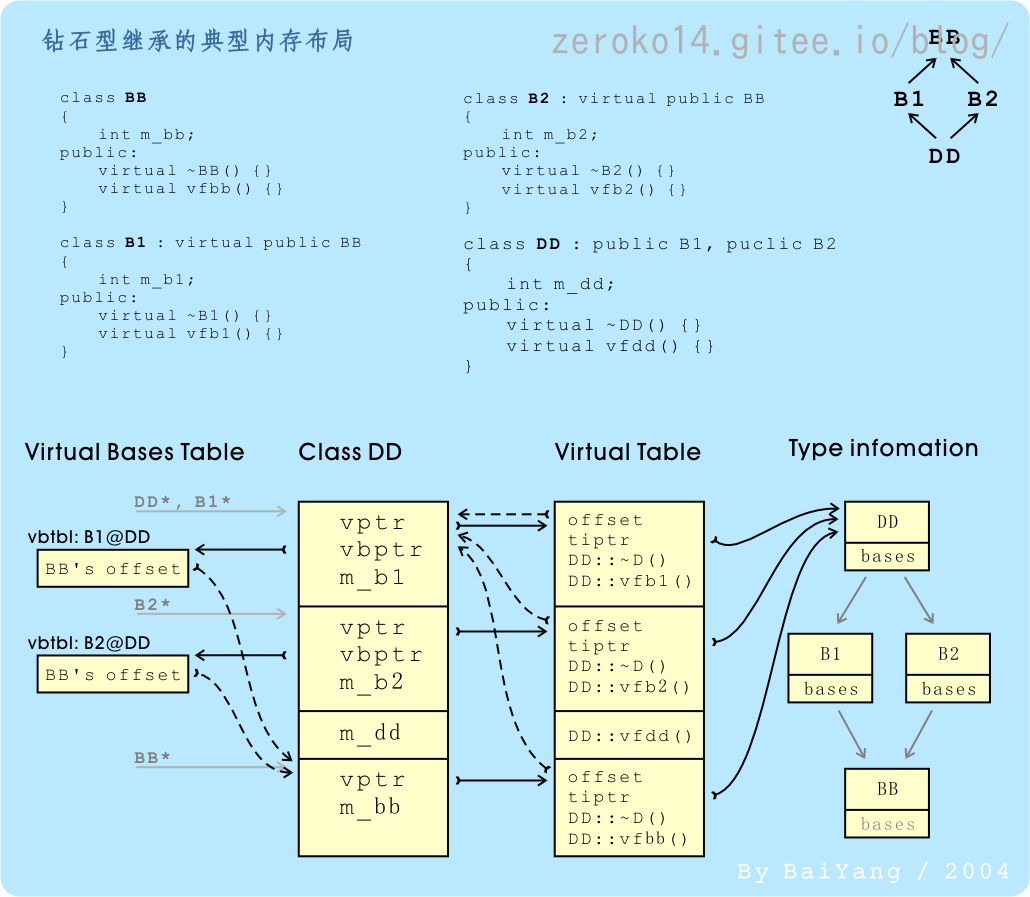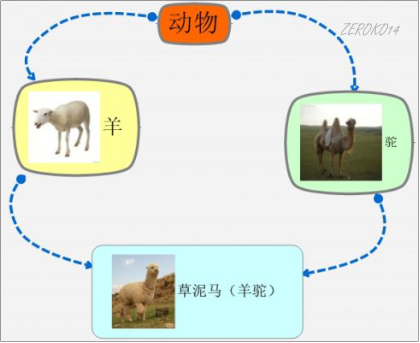
这种继承所带来的问题:草泥马继承自动物的函数和数据**继承了两份**,其实我们应该清楚,这份数据我们**只需要一份**就可以,并且还伴随二义性问题。
对于这种菱形继承所带来的两个问题,c++为我们提供了一种方式,采用**虚基类**。
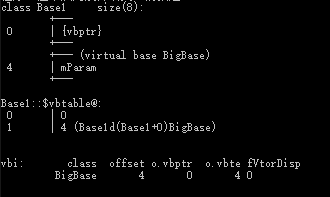
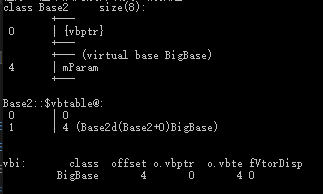
**作用:**编译器帮我们做了一些幕后工作,使得这种菱形问题在继承时候能**只继承一份数据**,并且也解决了二义性的问题。使模型变成了Base1和 Base2 Derived三个类对象共享了一份BigBase数据。
##### 虚继承实现原理
```cpp
class BigBase {
public:
BigBase() { mParam = 0; }
void func() { cout << "BigBase::func" << endl; }
public: int mParam;
};
#if 0 //虚继承
class Base1 : virtual public BigBase {};
class Base2 : virtual public BigBase {};
#else //普通继承
class Base1 : public BigBase {};
class Base2 : public BigBase {};
#endif
class Derived : public Base1, public Base2 {};
结果如下:
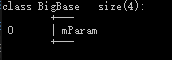
| 普通继承 | 虚继承 | |
|---|---|---|
| BigBase: | 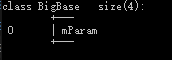 |
 |
| Base1: | 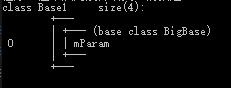 |
 |
| Base2: | 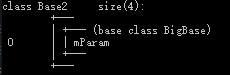 |
 |
| Derived: | 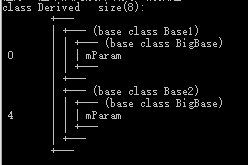 |
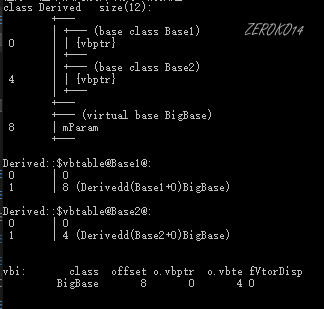 |
- BigBase 菱形最顶层的类,内存布局图没有发生改变。
- Base1和Base2通过虚继承的方式派生自BigBase,这两个对象的布局图中可以看出编译器为我们的对象中增加了一个vbptr (virtual base pointer),vbptr指向了一张表,这张表保存了当前的虚指针相对于虚基类的首地址的偏移量。
- Derived派生于Base1和Base2,继承了两个基类的vbptr指针,并调整了vbptr与虚基类的首地址的偏移量。
当使用虚继承时,在继承体系中无论被继承多少次,对象内存模型中均只会出现一个虚基类的子对象(这和多继承是完全不同的)

D的存储结构:

指针访问Derived类中Base2虚表中的偏移量4,代码如下:
1 | Derived d; |
虚继承只能解决具备公共祖先的多继承所带来的二义性问题,不能解决没有公共祖先的多继承的.
工程开发中真正意义上的多继承是几乎不被使用,因为多重继承带来的代码复杂性远多于其带来的便利,多重继承对代码维护性上的影响是灾难性的,在设计方法上,任何多继承都可以用单继承代替。
虚基类的构造函数
最派生类:继承结构中建立对象时所指定的类;
最派生类的构造函数的成员初始化列表中必须给出对虚基类的构造函数的调用,如果未列出,则相应的虚基类必须有缺省构造函数;
若A是虚基类,且没有缺省构造函数,则必须如下写明A()初始化列表

p.s.如果不是虚基类,调用父类非默认构造函数只需要传入父类,而如果祖先中有虚基类,那么初始化列表中必须有虚基类。
单个虚基类的案例:
1 | class A |
输出结果为:
p.s.虚基类构造函数永远先于非虚基类构造函数执行
d对象的内存布局图如下:
多个虚基类案例:

1 | class A |
内存布局分析:
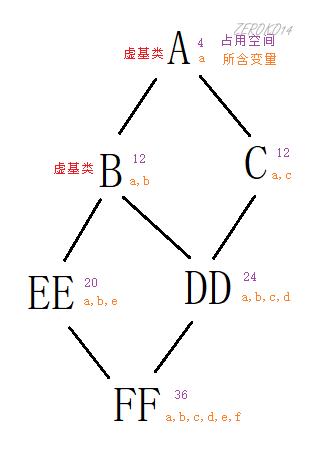
因开发人员命令提示工具问题,单字母类名与多同字母类名同等看待
| 类名 | 内存布局 |
|---|---|
| AAA | 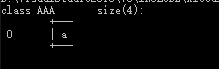 |
| BB | 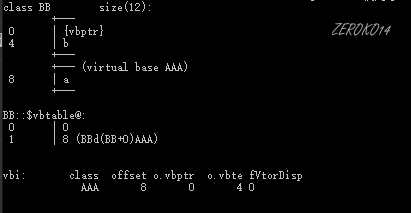 |
| CC | 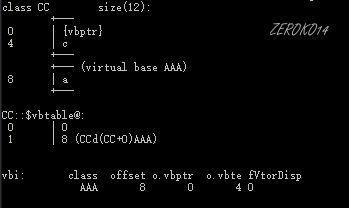 |
| DD | 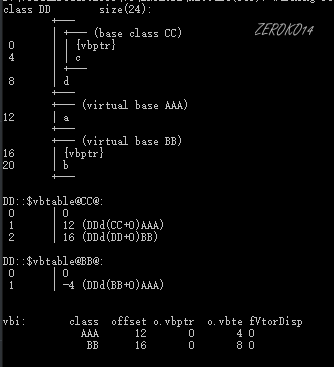 |
| EE | 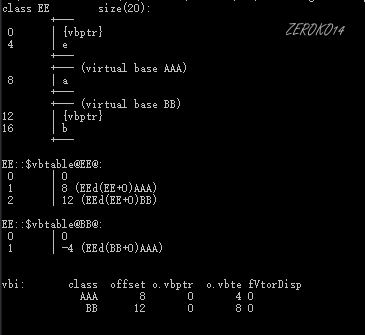 |
| FF | 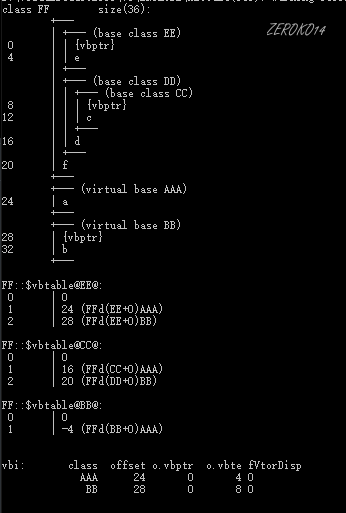 |
多态
多态是面向对象程序设计语言中数据抽象和继承之外的第三个基本特征。
多态性(polymorphism)提供接口与具体实现之间的另一层隔离
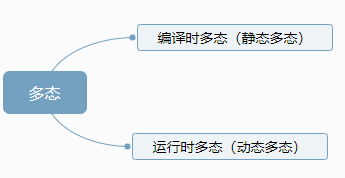
静态多态:运算符重载和函数重载
动态多态条件:
- 先有继承关系
- 父类中有虚函数,子类重写父类中的虚函数
- 父类的指针或引用指向子类的对象
静态多态和动态多态的区别:就是函数地址是早绑定(静态联编)还是晚绑定(动态联编)。
如果函数的调用,在编译阶段就可以确定函数的调用地址,并产生代码,就是静态多态(编译时多态),就是说地址是早绑定的。而如果函数的调用地址不能编译不能在编译期间确定,而需要在运行时才能决定,这这就属于晚绑定(动态多态,运行时多态)。
重写(覆盖):是指派生类中存在重新定义的函数。其函数名,参数列表,返回值类型,所有都必须同基类中被重写的函数一致。只有函数体不同(花括号内),派生类调用时会调用派生类的重写函数,不会调用被重写函数。重写的基类中被重写的函数必须有virtual修饰。
动态多态案例:
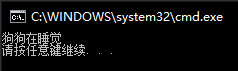
1 | class Animal |
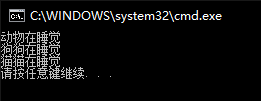
若把Animal类中sleep函数前的virtual去掉,结果如下:
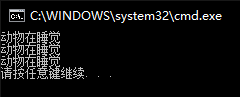
则不能实现运行时多态
父类引用/指向子类对象的四种方式
1 | class ITestOutput//纯虚类,接口ITestOutput |
指针,被指向对象为栈上分配内存
1 | TestOutput testoutput; |
指针,被指向对象为堆上分配内存
1 | ITestOutput* i = new TestOutput; |
引用,被引用对象为栈上分配内存
1 | TestOutput testObj; |
引用,被引用对象为堆上分配内存
1 | ITestOutput* p = new TestOutput |
动态多态原理
原理详解
向上类型转换及问题
若上面代码未用虚函数,则运行结果如上图
问题抛出: 我们给Sleep函数传入的对象是dog和cat,输出的结果却是动物在睡觉。
把函数体与函数调用相联系称为绑定(捆绑,binding)
当绑定在程序运行之前(由编译器和连接器)完成时,称为**早绑定(early binding).**C语言中只有一种函数调用方式,就是早绑定。
上面的问题就是由于早绑定引起的,因为编译器在只有Animal地址时并不知道要调用的正确函数。编译是根据指向对象的指针或引用的类型来选择函数调用。这个时候由于sleep的参数类型是Animal&,编译器确定了应该调用的sleep是Animal::sleep的,而不是真正传入的对象Dog::sleep。
分割线中小插曲
p.s.C++允许用父类的指针或引用指向子类的对象,但不强制类型转换的情况下,父类指针或引用是访问不到子类新增的成员的(编译器决定)
1 | class MyClass |
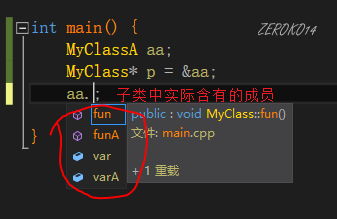
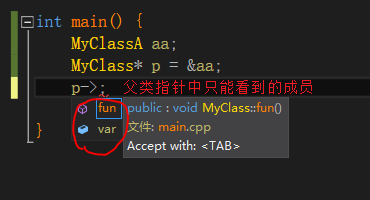
任何妄图使用父类指针或引用想调用子类中的未覆盖父类的成员函数的行为均被编译器视为非法,但实际上可以通过指针的方式间接访问虚函数表来达到违反C++语义的行为
解决上面的问题的方法就是迟绑定(迟捆绑,动态绑定,运行时绑定,late binding),意味着绑定要根据对象的实际类型,发生在运行。
迟绑定实现方案原理
对于特定的函数进行动态绑定,c++要求在基类中声明这个函数的时候使用virtual关键字,动态绑定也就对virtual函数起作用.
- 为创建一个需要动态绑定的虚成员函数,可以简单在这个函数声明前面加上virtual关键字,定义时候不需要.
- 如果一个函数在基类中被声明为virtual,那么在所有派生类中它都是virtual的.
- 在派生类中virtual函数的重定义称为重写(override).
- Virtual关键字只能修饰成员函数.
- 构造函数不能为虚函数
***注意:***可以在派生类声明前使用关键字virtual(这也是无害的,建议加上,让人一看代码就知道这个函数是对父类函数进行重写的)
首先,我们看看编译器如何处理虚函数。当编译器发现我们的类中有虚函数的时候,编译器会创建一张虚函数表,把虚函数的函数入口地址放到虚函数表中,并且在类中秘密增加一个指针,这个指针就是vpointer(缩写vptr),这个指针是指向对象的虚函数表。在多态调用的时候,根据vptr指针,找到虚函数表来实现动态绑定。
在编译阶段,编译器秘密增加了一个vptr指针,但是此时vptr指针并没有初始化指向虚函数表(vtable),什么时候vptr才会指向虚函数表?在对象构建的时候,也就是在对象初始化调用构造函数的时候。编译器首先默认会在我们所编写的每一个构造函数中,增加一些vptr指针初始化的代码。如果没有提供构造函数,编译器会提供默认的构造函数,那么就会在默认构造函数里做此项工作,初始化vptr指针,使之指向本对象的虚函数表。
起初,子类继承基类,子类继承了基类的vptr指针,这个vptr指针是指向基类虚函数表,当子类调用构造函数,使得子类的vptr指针指向了子类的虚函数表。
当子类无重写基类虚函数时:
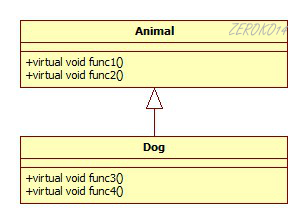
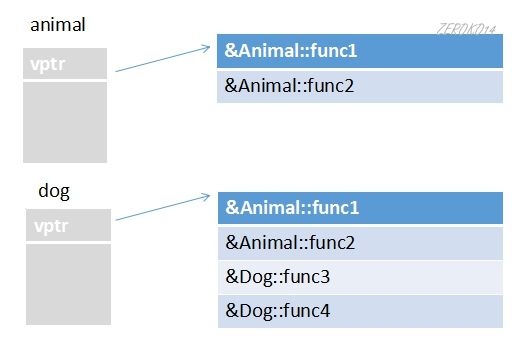
当子类重写基类虚函数时:
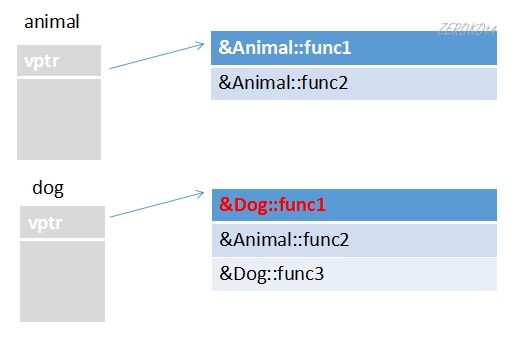
没用虚函数的情况:
1 | class A |
使用虚函数的情况:
1 | class A |
内存布局详解
- 当父类写了虚函数后,类内部的结构发生了改变,多了vfptr(虚函数表指针),指向vftable(虚函数表)
- 虚函数表内部记录着虚函数的入口地址
- 当父类指针或引用指向子类对象,发生多态,调用的时候是从虚函数表中找函数入口地址
加了虚函数指针后,内存布局:
上面运行多态
| 类名 | 对象内存布局 |
|---|---|
| Animal | 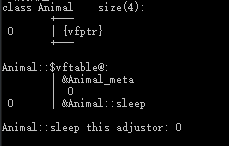 |
| Cat | 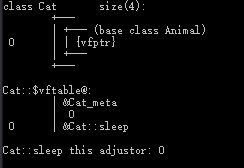 |
| Dog | 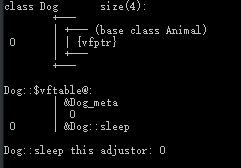 |
案例中用父类指针手动调用子类函数
1 | Dog d; |

单继承中虚函数
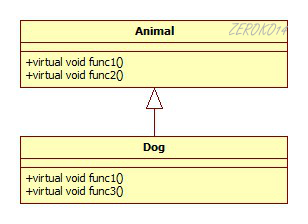
在单继承形式下,子类的完全获得父类的虚函数表和数据。子类如果重写了父类的虚函数(如fun),就会把虚函数表原本fun对应的记录(内容MyClass::fun)覆盖为新的函数地址(内容MyClassA::fun),否则继续保持原本的函数地址记录。如果子类定义了新的虚函数,虚函数表内会追加一条记录,记录该函数的地址(如MyClassA::funA)。
1 | class Animal |
| 类名 | 内存布局 |
|---|---|
| Animal | 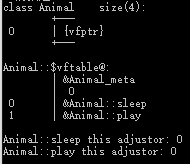 |
| Cat | 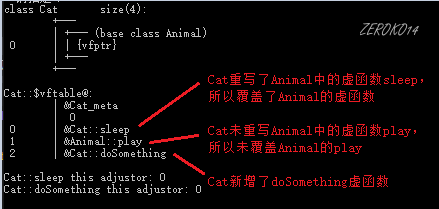 |
1 | MyClass*pc=new MyClassA; |
编译器在处理第二条语句时,发现这是一个多态的调用,那么就会按照如下对虚函数的多态访问机制调用函数fun。
$$
*(this指针+调整量)虚函数在vftable内的偏移
$$
多重继承中的虚函数
1 | class MyClass |
图解上面代码:

MyClassC对象空间布局如下:
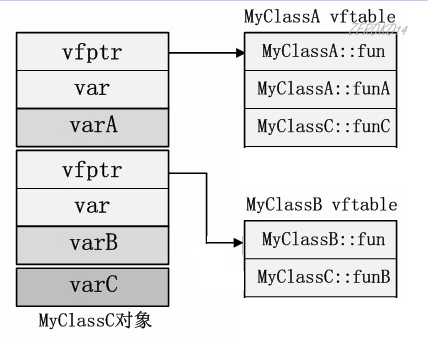
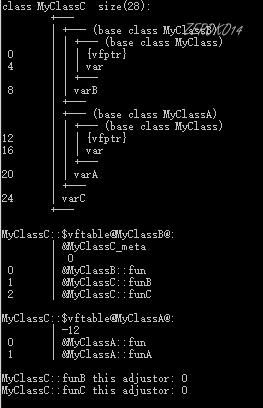
【重点解读】
和单重继承类似,多重继承时MyClassC会把所有的父类全部按序包含在自身内部。而且每一个父类都对应一个单独的虚函数表。
多重继承下,子类不再具有自身的虚函数表,它的虚函数表与第一个父类的虚函数表合并了。同样的,如果子类重写了任意父类的虚函数,都会覆盖对应的函数地址记录。如果MyClassC重写了fun函数(两个父类都有该函数),那么两个虚函数表的记录都需要被覆盖!
多重继承中同时存在虚继承和虚函数
上面案例修改为如下:
1 | class MyClassA:virtual public MyClass |
虚继承的引入把对象的模型变得十分复杂,除了每个基类(MyClassA和MyClassB)和公共基类(MyClass)的虚函数表指针需要记录外,每个虚拟继承了MyClass的父类还需要记录一个虚基类表vbtable的指针vbptr。
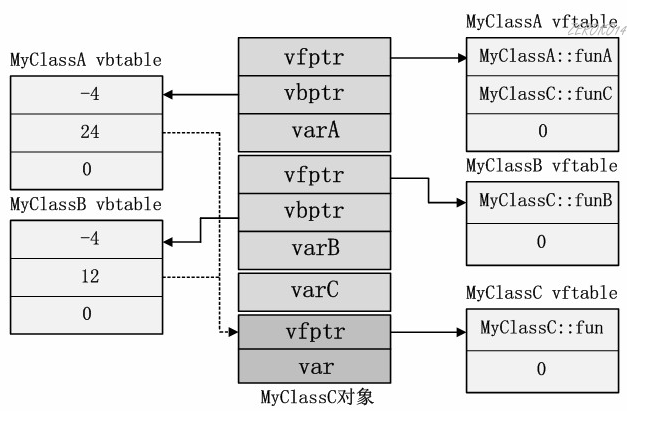
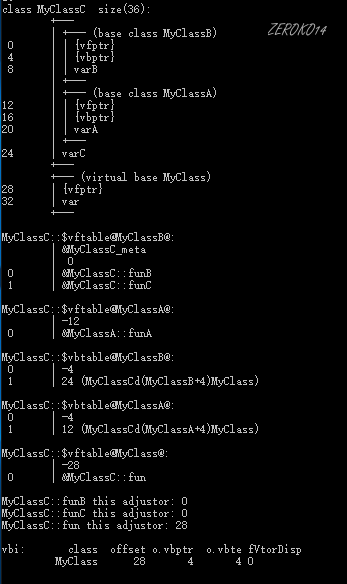
虚基类表每项记录了被继承的虚基类子对象相对于虚基类表指针的偏移量。比如MyClassA的虚基类表第二项记录值为24,正是MyClass::vfptr相对于MyClassA::vbptr的偏移量,同理MyClassB的虚基类表第二项记录值12也正是MyClass::vfptr相对于MyClassA::vbptr的偏移量。
和虚函数表不同的是,虚基类表的第一项记录着当前子对象相对与虚基类表指针的偏移。MyClassA和MyClassB子对象内的虚表指针都是存储在相对于自身的4字节偏移处,因此该值是-4。假定MyClassA和MyClassC或者MyClassB内没有定义新的虚函数,即不会产生虚函数表,那么虚基类表第一项字段的值应该是0。
通过以上的对象组织形式,编译器解决了公共虚基类的多份拷贝的问题。通过每个父类的虚基类表指针,都能找到被公共使用的虚基类的子对象的位置,并依次访问虚基类子对象的数据。至于虚基类定义的虚函数,它和其他的虚函数的访问形式相同,本例中,如果使用虚基类指针MyClass*pc访问MyClassC对象的fun,将会被转化为如下形式:
$$
*(pc+28)0
$$
通过以上的描述,我们基本认清了C++的对象模型。尤其是在多重、虚拟继承下的复杂结构。通过这些真实的例子,使得我们认清C++内class的本质
【注意】
指针的位置和基类成员在派生类成员中的内存布局是不确定的,也就是说标准里面没有规定int a必须要放在最后,只不过g++编译器的实现而已。c++标准大概只规定了这套机制的原理,至于具体的实现,比如各成员的排放顺序和优化,由各个编译器厂商自己定
多继承中的虚表内存布局
- 当有多个虚函数表时,虚函数表的结果是0,代表没有下一个虚函数表
- 非末尾的其他虚函数表由什么代表结束在不同操作系统中不一样,代表有下一个虚函数表
- 父类中没有,而子类中有的虚函数,都填入第一个虚函数表中
【注意】vs在打印对象虚函数表的时候,只打印最上层基类声明的虚函数。
即,虚函数表显示不全,需要用监视或内存窗口手动显示虚表的所有内容
多态的实际开发意义
- 多态的好处
- 代码可读性强
- 组织结构清晰
- 扩展性强
面向对象程序设计原则**【开闭原则】**:对扩展进行开放,对修改进行关闭
解释:开闭原则含义是说一个软件实体应该通过扩展来实现变化,而不是通过修改已有的代码来实现变化的。
原因:没有修改底层模块,代码改变量少,可以有效的防止风险的扩散。
开闭原则实现方法就是多态
- 开闭原则的好处:
- 提高复用性
- 提高维护性
- 提高拓展性
未采用开闭原则案例:
1 | //计算器 |
这种程序不利于扩展,维护困难,如果修改功能或者扩展功能需要在源代码基础上修改
面向对象程序设计一个基本原则:开闭原则(对修改关闭,对扩展开放)
1 | //抽象基类 |
多态的案例:
1 | class Cpu |
纯虚函数和抽象类
在设计时,常常希望基类仅仅作为其派生类的一个接口。这就是说,仅想对基类进行向上类型转换,使用它的接口,而不希望用户实际的创建一个基类的对象。同时创建一个纯虚函数允许接口中放置成员原函数,而不一定要提供一段可能对这个函数毫无意义的代码。
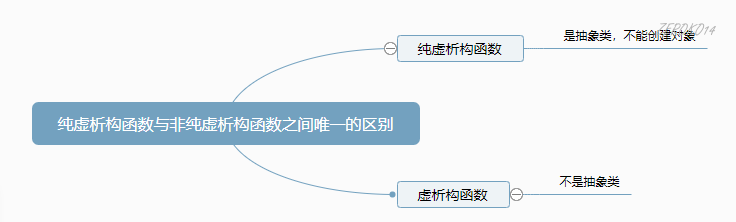
为了上面的目的,可以在基类中加入至少一个纯虚函数(pure virtual function),使得基类称为抽象类(abstract class).
纯虚函数使用关键字virtual,并在其后面加上=0。如果试图去实例化一个抽象类,编译器则会阻止这种操作。
1
virtual 返回类型 函数名()=0;
当继承一个抽象类的时候,必须实现所有的纯虚函数,否则由抽象类派生的类也是一个抽象类。
Virtual void fun() = 0;告诉编译器在vftable中为函数保留一个位置,但在这个特定位置不放地址。
建立公共接口目的是为了将子类公共的操作抽象出来,可以通过一个公共接口来操纵一组类,且这个公共接口不需要事先实现(或者不需要完全实现)。
案例如下:

1 | //抽象制作饮品 |
纯虚函数和多继承
多继承带来了一些争议,但是接口继承可以说一种毫无争议的运用了。
绝大数面向对象语言都不支持多继承,但是绝大数面向对象对象语言都支持接口的概念,c++中没有接口的概念,但是可以通过纯虚函数实现接口。
$$
不同点在于:接口类中只有函数原型定义,没有任何数据定义。
$$
多重继承接口不会带来二义性和复杂性问题。接口类只是一个功能声明,并不是功能实现,子类需要根据功能说明定义功能实现。
只有纯虚函数的抽象类
其他语言中的接口实际上就是只有纯虚函数的抽象类
这种格式的意义在于:
契约定义
接口首先是一种契约,它定义了一个类必须实现哪些方法,但不关心这些方法的具体实现。这种契约的机制允许不同的类实现相同的接口,从而可以在不同的实现之间进行切换,而不影响使用这些类的代码。
解耦
接口是解耦合的强大工具。通过依赖于接口而不是具体的实现,我们可以改变具体的实现而不需要修改依赖于这些接口的代码。这对于构建易于测试、维护和扩展的系统尤为重要。
多继承
在很多面向对象的编程语言中,类只能从一个类继承(单继承),但是可以实现多个接口。这提供了一种形式的多继承,允许对象拥有来自多个源的行为。
灵活性和可拓展性
接口使得代码更加灵活和可拓展。例如,如果你的应用开始时使用的是一种算法或数据结构,随着应用的发展,你可能需要替换为更高效的实现。如果你的代码依赖于接口而不是具体的实现,这种替换会变得非常简单。
接口与多态性
关于多态性,虽然通过继承(包括抽象类和具体类的继承)也能实现多态性,但接口提供了另一种方式。接口允许不同的类共享同一个接口的定义,这意味着我们可以使用接口类型的引用来调用实现了该接口的任何类的实例的方法。
例如,考虑一个日志系统,你可能有多种方式来记录日志(文件、数据库、远程服务等)。如果所有这些日志记录器实现了同一个接口(比如ILogger),那么你可以在不同的记录器之间切换而不改变使用这些记录器的代码。这种灵活性是使用接口的直接好处。
以一段csharp为例子看接口(只有纯虚函数的抽象类)的作用
1 | public interface IHuntable |
这样,Farmer类中的feedAnimal方法可以接受任何实现了IHuntable接口的对象作为参数,这样就利用到了多态性:
1 | public void feedAnimal(IHuntable ht, Animal a) |
可见,接口能实现更灵活的多态
[[CSharp入门#对接口和抽象类的理解|实际开发中,经常会同时使用接口和抽象类。接口定义行为的契约,而抽象类提供部分实现]]
虚析构和纯虚析构
虚析构函数和纯虚构函数都是为了解决基类的指针指向派生类对象,并用基类的指针删除派生类对象产生的“只调用了基类的析构函数而没有调用派生类的析构函数”的问题
1 |
|
返回结果为:
1 | A 构造 |
如果在A的析构函数定义前加virtual,结果为
1 | A 构造 |
纯虚析构函数
纯虚析构函数在c++中是合法的,但是在使用的时候有一个额外的限制:必须在类外为纯虚析构函数提供一个函数体。
1 | //非纯虚析构函数 |
如果类的目的不是为了实现多态作为基类来使用,就不要声明虚析构函数,反之,则应该为类声明虚析构函数。(原因如下)
这是因为在使用继承和多态的情况下,如果一个基类指针指向一个派生类对象,并且通过基类指针删除该对象时,如果基类的析构函数不是虚函数,那么只会调用基类的析构函数,而不会调用派生类的析构函数。这可能导致派生类中的资源无法正确释放,从而引发内存泄漏或其他问题。
通过将基类的析构函数声明为虚函数,可以解决这个问题。当通过基类指针删除派生类对象时,会首先调用派生类的析构函数,然后再调用基类的析构函数,确保派生类中的资源得到正确释放。
因此,如果你的类可能会被继承,并且在使用多态时需要通过基类指针来删除对象,那么应该将析构函数声明为虚函数。这样可以确保在删除对象时调用正确的析构函数,避免资源泄漏和其他问题。
然而,如果你的类不会被继承或不会用于多态,那么声明虚析构函数可能会带来额外的开销。因此,在这种情况下,可以不声明虚析构函数。这样可以避免不必要的开销,并保持代码的简洁性。
重写 重载 重定义 区别
- 重载,同一作用域的同名函数
- 同一个作用域
- 参数个数,参数顺序,参数类型不同
- 和函数返回值,没有关系
- const也可以作为重载条件 //do(const Teacher& t){} do(Teacher& t)
- 重定义(隐藏)
- 有继承
- 子类(派生类)重新定义父类(基类)的同名成员(非virtual函数)
- 子类隐藏父类所有同名重载函数,可以用作用域显式调用
- 重写(覆盖)
- 有继承
- 子类(派生类)重写父类(基类)的virtual函数
- 函数返回值,函数名字,函数参数,必须和基类中的虚函数一致
多态与别的语言的区别盘点
[[CSharp入门#CSharp与C++多态对比|CSharp与C++多态对比]]
位域
[[C语言入门#位域|C语言中的位域]]只能用于整型数据类型(如int、char等),而C++还支持对非整数类型的位域进行定义,如布尔类型、枚举类型等。
对齐规则的差异:
- 在C语言中,位域的对齐规则是相对于结构体的起始位置,不同位域之间可能会进行位填充以满足对齐要求。
- 在C++中,位域的对齐规则是相对于前一个位域的结束位置,不会进行位填充,因此位域之间不会有空隙。
C++既可以使用struct,也可以使用class
1 | //C++的位域案例 |
模板
模板参数列表中除了允许包含类型模板参数,也允许包含非类型模板参数,这些参数可以是整型(包括但不限于 int, long, long long, unsigned 及其对应的带符号整型)、枚举类型、指针或引用(到对象或函数),以及std::nullptr_t。对于整数类型,用户可以在模板实例化时传入一个整数常量表达式作为模板参数的值
1 | template <int N> |
函数模板
c++提供了函数模板(function template.)所谓函数模板,***实际上是建立一个通用函数,其函数类型和形参类型不具体制定,用一个虚拟的类型来代表。这个通用函数就成为函数模板。***凡是函数体相同的函数都可以用这个模板代替,不必定义多个函数,只需在模板中定义一次即可。在调用函数时系统会根据实参的类型来取代模板中的虚拟类型,从而实现不同函数的功能。
- c++提供两种模板机制:函数模板和类模板
$$
模板用于表达逻辑结构相同,但具体数据元素类型不同的数据对象的通用行为
$$
目的:用模板是为了实现泛型,可以减轻编程的工作量,增强函数的重用性。
格式:
1
2template<typename T>
template<class T>//上下两种完全一样,T是自定义通用数据类型名称两种使用方式:
- 自动类型推导 — 通过参数必须要推导出一致的T才可以使用
- 显示指定类型 — mySwap<int>(a,b);
下面是实现对通用基本数据类型数组进行排序的案例:
1 | //通用模板实现数据交换 |
函数模板和普通函数区别
- 函数模板如果使用自动类型推导,是不可以发生隐式类型转换的,可以使用显示指定类型方式调用函数模板,此时可以发生隐式类型转换
- 普通函数,可以发生隐式类型转换
1 | //函数模板 |
函数模板和普通函数的调用规则
若函数模板和普通函数都可以调用,那么优先调用普通函数,若想强制调用函数模板,可以使用空模板参数列表
1
myPrint<>(a,b);//空模板
函数模板也可以发生重载(肯定呀,本质上就是编译器帮你把所有用到的各种类型都写了)
若函数模板能产生更好的匹配(不用隐式转换的情况),那么优先使用函数模板
1 | //函数模板 |
函数模板机制原理剖析
函数模板机制结论:
- 编译器并不是把函数模板处理成能够处理任何类型的函数,只是基本数据类型
- 函数模板通过具体类型产生不同的函数
- 两次编译,在声明的地方对模板代码本身进行编译(语法检测),在调用的地方对参数替换后的代码进行编译(产生不同的函数)(这也就是模板的分文件特殊化的原因)
函数模板分文件编写
函数模板的分文件编写与类模板分文件编写一致,参考类模板的分文件编写章节
函数模板特化
也称为模板具体化
上面提到模板并不是真实的通用,对于自定义的数据类型,可以使用具体化技术,实现对自定义数据类型的特殊使用。
格式如下:
1 | template<> bool myCompare(Person &a,Person &b); |
案例:
1 | class Person |
函数模板特化有两种形式:明确特化和部分特化。
明确特化是指为特定类型或参数提供完全不同的函数实现。它使用template<>语法来声明特化版本,并提供特定的实现。
下面是一个示例,展示了如何对函数模板进行明确特化:
1 | // 声明一个函数模板 |
在上面的示例中,我们定义了一个函数模板print,它可以打印任意类型的值。然后,通过使用template<>语法,我们对print<int>进行了明确特化,为int类型提供了一个特殊的实现。
部分特化是指对函数模板的一部分参数进行特化。它使用模板参数的部分列表来匹配特定的实例,并提供特定的实现。
下面是一个示例,展示了如何对函数模板进行部分特化:
1 | // 声明一个函数模板 |
在上面的示例中,我们对print<T, int>进行了部分特化,为特定的参数组合提供了一个特殊的实现。
类模板
类模板和函数模板的区别
类模板不可以使用自动类型推导,只能用显示指定类型
1
2Person<string,int> p;
//Person p;//错误类模板中,可以有默认参数(函数模板不可以有)
1
template<class T,class T2=int>
类模板中的成员函数,并不是一开始就创建的,而是在运行阶段确定出T的数据类型才去创建
1 | class AA |
类模板做函数参数
- 三种方式
指定传入类型
参数模板化
整个类模板化
1 | template<class T1,class T2> |
类模板和派生
两种情况如下:
类模板派生普通类
1 | //类模板 |
类模板派生类模板
1 | //父类类模板 |
本质上是一样的。
类模板中的成员函数类外实现
写法如下:
1 | template<class T1, class T2> |
上述代码中如果不按照这个格式写,会报错如下:

类模板的分文件编写
类模板中的成员函数,不会一开始就创建,因此导致分文件编写时,连接不到函数的实现,出现无法解析的外部命令错误。
[[qt]]编译器可以顺利通过编译并执行,但是在Linux和vs编辑器下如果只包含头文件,那么会报错链接错误,需要包含cpp文件,但是如果类模板中有友元类,那么编译失败!
原因:
- 类模板需要二次编译,在出现模板的地方编译一次,在调用模板的地方再次编译
- C++编译规则为独立编译(编译器编译源码 逐个编译单元编译的)
两种解决方式:
- 直接包含.cpp文件,实现和声明都放在一个文件中,就不用两个文件了(不推荐)
- 将.cpp文件后缀名改为.hpp(其实本质依旧是将类声明和实现写到同一个文件中)(调用的时候include的是hpp)(也可以用.cpp.impl后缀,虚幻引擎使用.inl后缀)
总之就是:模板的定义必须和声明放在同一个文件中
更详细的流程可以参考此知乎链接
函数模板的分文件编写与类模板分文件编写一致
这也导致了 C++的模板库,基本是开源的
如果库的用户不需要去产生这个模板的新的实例化类型,则可以在库内部的模板实现文件中对所有可能的类型进行显式实例化。如果库的用户有产生新的实例化类型的需求,则无法隐藏实现
Person.h
1 |
|
Person.cpp
1 | template<class T1, class T2> |
main.cpp
1 |
|
类模板和静态成员
直接看案例:
1 | template<class T > |
类模板中的友元函数
- 友元函数在类中声明时,函数名后接<>表示函数模板要到类外找。
- 也可以友元函数直接写成函数模板
1 |
|
设计一个动态数组模板类(MyArray),完成对不同类型元素的管理:(重点案例)(其中涉及到内存泄露检测)
动态数组模板类
头文件dynamicArray.h
1 |
|
源文件dynamicArray.hpp
1 |
|
main文件main.cpp
1 |
|
**【重点】**memmove用于拷贝字节,如果目标区域和源区域有重叠的话,memmove能够保证源串在被覆盖之前将重叠区域的字节拷贝到目标区域中,但复制后源内容会被更改。但是当目标区域与源区域没有重叠则和memcpy函数功能相同。
【重点】(崩溃的调试定位问题技巧)崩溃的时候在弹出的对话框按相应按钮进入调试,按Alt+7键查看Call Stack即“调用堆栈”里面从上到下列出的对应从里层到外层的函数调用历史。双击某一行可将光标定位到此次调用的源代码或汇编指令处,看不懂时双击下一行,直到能看懂为止。
类模板特化
模板特化是从C++98标准开始引入的特性,并在后续的C++标准中进行了一些改进和扩展。因此,无论是C++98、C++11、C++14、C++17还是C++20,都支持模板特化。
在C++中,你可以通过使用template<>语法来实现模板特化。下面是一个示例,展示了如何对一个类模板进行明确特化:
1 | // 声明一个类模板 |
在上面的示例中,我们定义了一个类模板MyClass,并为其提供了一个通用的实现。然后,通过使用template<>语法,我们对MyClass<int>进行了明确特化,并提供了一个特定的实现。
你还可以进行部分特化,对模板的一部分参数进行特化。下面是一个示例:
1 | // 声明一个类模板 |
在上面的示例中,我们对MyClass<T, int>进行了部分特化,为特定的参数组合提供了一个特殊的实现。
模板模板参数
模板模板参数(Template Template Parameters)是在C++98标准中引入的。这意味着从C++98开始,就可以使用模板模板参数来定义模板,将模板作为另一个模板的参数。
模板模板参数是C++中的一项强大的模板技术,它提供了更高级的模板编程能力,使得代码更加灵活和通用。它允许你以模板作为参数传递给其他模板,从而实现更复杂的泛型编程和模板元编程。
类型转换
静态类型转换(static_cast)
语法:static_cast<目标变量>(原变量/原对象)
- 允许内置数据类型转换
- 允许父子之间的指针或引用的转换(上行转换是安全的,下行转换是不安全的,但都允许)
1 | //无继承关系指针转换 |
动态类型转换(dynamic_cast)
语法:dynamic_cast<目标变量>(原变量/原对象)
- 不允许内置数据类型转换
- 允许父子之间指针或引用的上行转换
- 但若发生多态,总是安全的,下行转换在多态的情况下也可以用dynamic_cast转换
总结:将一切不安全的情况扼杀于萌芽
1 | //继承关系指针 |
1 | //多态 |
常量转换(const_cast)
作用:该运算符用来修改指针或引用类型的const属性
- 常量指针被转化成非常量指针或非常量指针被转化成常量指针,并且仍然指向原来的对象;
- 常量引用被转换成非常量引用或非常量引用被转换成常量引用,并且仍然指向原来的对象;
***注意:***不能直接对非指针和非引用的变量使用const_cast操作符去直接移除它的const.
1 | //常量指针 |
重新解释转换(reinterpret_cast)
这是最不安全的一种转换机制,最有可能出问题,同时也最自由,什么都可以转。
理解:等同于C语言的强制类型转换
1 | int a=10;//int转int* |
异常
异常的基本概念
Bjarne Stroustrup说:提供异常的基本目的就是为了处理上面的问题。基本思想是:让一个函数在发现了自己无法处理的错误时抛出(throw)一个异常,然后它的(直接或者间接)调用者能够处理这个问题。也就是《C++ primer》中说的:将问题检测和问题处理相分离。
一种思想:在所有支持异常处理的编程语言中(例如java),要认识到的一个思想:在异常处理过程中,由问题检测代码可以抛出一个对象给问题处理代码,通过这个对象的类型和内容,实际上完成了两个部分的通信,通信的内容是“出现了什么错误”。当然,各种语言对异常的具体实现有着或多或少的区别,但是这个通信的思想是不变的。
一句话:异常处理就是处理程序中的错误。所谓错误是指在程序运行的过程中发生的一些异常事件(如:除0溢出,数组下标越界,所要读取的文件不存在,空指针,内存不足等等)。
C语言中的异常处理(C++中仍然可以)
使用整型的返回值标识错误
使用errno宏(可以简单的理解为一个全局整型变量)去记录错误。(可用perror输出)
上述方法的两个缺陷
- 返回值意义不一致问题,例如0表示错误还是1表示错误
- 函数的返回值只有一个,虽然可以通过指针或引用来返回另外的值,但这样就会令你的程序晦涩难懂
异常的必要之处
- 部分函数使用异常更好处理,比如构造函数没有返回值,不方便使用错误码方式处理。比如
T& operator这样的函数,如果pos越界了只能使用异常或者终止程序处理,没办法通过返回
值表示错误 - 很多的第三方库都包含异常,比如boost、gtest、gmock等等常用的库,那么我们使用它们
也需要使用异常
c++异常机制相比C语言异常处理的优势?
C语言中没有内建的异常机制,类似于其他高级语言中的try-catch块。通常,C语言程序员会使用错误码或者返回值来处理异常情况
- 函数的返回值可以忽略,但异常不可忽略。如果程序出现异常,但是没有被捕获,程序就会终止,这多少会促使程序员开发出来的程序更健壮一点。而如果使用C语言的error宏或者函数返回值,调用者都有可能忘记检查,从而没有对错误进行处理,结果造成程序莫名其面的终止或出现错误的结果。
- 整型返回值没有任何语义信息。而异常却包含语义信息,有时你从类名就能够体现出来。
- 整型返回值缺乏相关的上下文信息。异常作为一个类,可以拥有自己的成员,这些成员就可以传递足够的信息。
- 异常处理可以在调用跳级。这是一个代码编写时的问题:假设在有多个函数的调用栈中出现了某个错误,使用整型返回码要求你在每一级函数中都要进行处理。而使用异常处理的栈展开机制,只需要在一处进行处理就可以了,不需要每级函数都处理。
C异常机制缺陷案例:
1 | //如果判断返回值,那么返回值是错误码还是结果? |
异常的一直不处理,最终程序会终止,调用std::terminate(),该函数中默认调用std::abort(),最终中止程序运行
异常基本语法
异常的关键词:try catch throw
- 若有异常则通过throw操作创建一个异常对象或变量并抛出,throw类似return会结束当前函数。
- 将可能抛出异常的程序段放到try块之中。
- catch如果想捕获其他类型,catch(…)
- 如果在try段执行期间没有引起异常,那么跟在try后面的catch字句就不会执行。
- catch子句会根据出现的先后顺序被检查,匹配的catch语句捕获并处理异常(或继续抛出异常)
- 异常必须有函数进行处理,如果匹配的处理未找到,则运行函数terminate将自动被调用,其缺省功能调用abort终止程序。
- 处理不了的异常,可以在catch的最后一个分支,使用throw,向上抛。
- 异常可以是自定义类型
1 | int A_MyDivide(int a, int b){ |
c++异常处理使得异常的引发和异常的处理不必在一个函数中,这样底层的函数可以着重解决具体问题,而不必过多的考虑异常的处理。上层调用者可以在适当的位置设计对不同类型异常的处理。
异常严格类型匹配
捕捉方式是通过严格类型匹配。(即不存在隐式类型转换)
1 | class MyException//自定义异常 |
栈解旋(unwinding)
异常被抛出后,从进入try块起,到异常被抛掷前,这期间在栈上构造的所有对象,都会被自动析构。析构的顺序与构造的顺序相反,这一过程称为栈的解旋(unwinding).
1 | class Person{ |

异常接口声明
可以在函数声明中列出可能抛出异常的所有类型,即限定抛出异常的类型
1
void func() throw(A,B,C);//这个函数func能够且只能抛出类型A,B,C及其子类型的异常。
如果在函数声明中没有包含异常接口声明,则此函数可以抛任何类型的异常
一个不抛任何类型异常的函数可声明为:void func() throw(),代表不允许抛出异常
如果一个函数抛出了它的异常接口声明所不允许抛出的异常,unexcepted函数会被调用,该函数默认行为调用terminate函数中断程序。
1 | //可抛出所有类型异常 |
分别在qt vs linux下做测试!
- Qt and Linux 正确!
- vs2015接口声明不影响使用,但不能正常发挥限制异常抛出类型的作用
异常变量生命周期
1 | class MyException |
《修改位1》是throw MyException(); 《修改位2》是 catch(MyException e);
调用拷贝构造函数,效率低

《修改位1》是throw MyException(); 《修改位2》是catch(MyException& e);
只调用默认构造函数,效率高,推荐
《修改位1》是throw &MyException(); 《修改位2》是catch(MyException* e);
对象会提前释放掉,不能再非法操作
显然3的情况:在catch中调用e的函数会报错,因为MyException已被析构



总结,第二种方式才是正确的做法
异常的多态使用
- 提供基类异常类BaseException,内含纯虚函数virtual void printError()=0;
- 空指针异常类和越界异常类继承BaseException
- 重写virtual void printError()函数
- 测试:利用父类引用指向子类对象
1 | //越界异常 |
异常原理
[[C语言入门#栈区(stack)|函数调用解析参考]]
C语言的函数栈架构主要承载着以下几个部分:
- 1、传递参数:通常,函数的调用参数总是在这个函数栈框架的最顶端。
- 2、传递返回地址:告诉被调用者的 return 语句应该 return 到哪里去,通常指向该函数调用的下一条语句(代码段中的偏移)。
- 3、存放调用者的当前栈指针:便于清理被调用者的所有局部变量、并恢复调用者的现场。
- 4、存放当前函数内的所有局部变量:所有局部和临时变量都是存储在栈上的。

使用了异常处理机制的C++函数调用
首先澄清一点,这里说的 “C++ 函数”是指:
- 该函数可能会直接或间接地抛出一个异常:即该函数的定义存放在一个 C++ 编译(而不是传统 C)单元内,并且该函数没有使用 “throw()” 异常过滤器。
- 该函数的定义内使用了 try 块。
以上两者满足其一即可。为了能够成功地捕获异常和正确地完成栈回退(stack unwind),编译器必须要引入一些额外的数据结构和相应的处理机制。我们首先来看看引入了异常处理机制的栈框架大概是什么样子
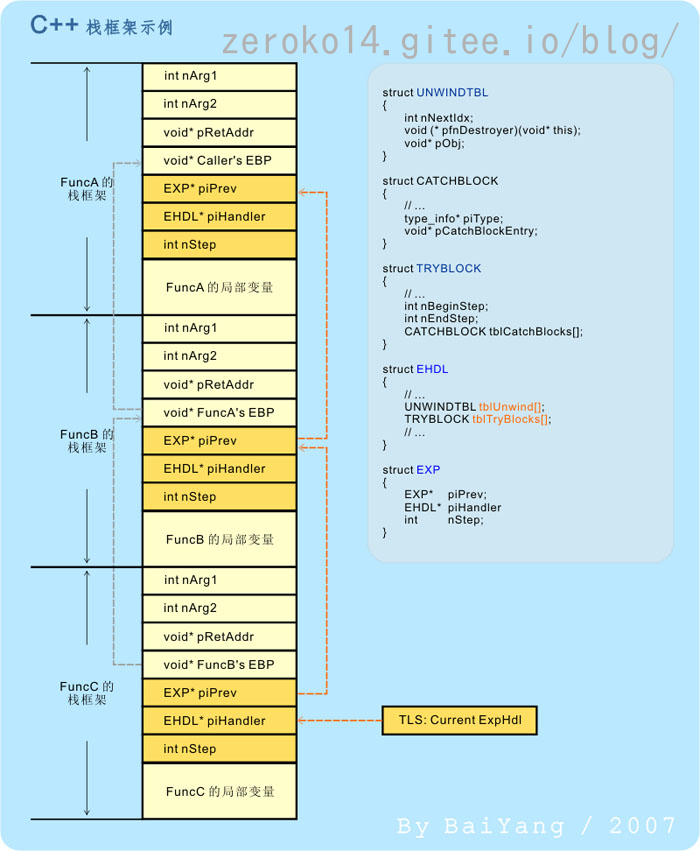
由上图可见,在每个 C++ 函数的栈框架中都多了一个 EXP 类型的结构体。进一步分析就会发现,这是一个典型的单向链表式结构
piPrev成员指向链表的上一个节点,它主要用于在函数调用栈中逐级向上寻找匹配的 catch 块,并完成栈回退工作。piHandler成员指向完成异常捕获和栈回退所必须的数据结构(主要是两张记载着关键数据的表:“try”块表:tblTryBlocks及“栈回退表”:tblUnwind)。nStep成员用来定位 try 块,以及在栈回退表中寻找正确的入口。
需要说明的是:编译器会为每一个 “C++ 函数”定义一个 EHDL 结构,不过只会为包含了 “try” 块的函数定义 tblTryBlocks 成员。此外,异常处理器还会为每个线程维护一个指向当前异常处理框架的指针。该指针指向异常处理器链表的链尾,通常存放在某个 TLS 槽(Thread-Local Storage Slot)或能起到类似作用的地方。
栈回退(stack unwind)
“栈回退”是伴随异常处理机制引入 C++ 中的一个新概念,主要用来确保在异常被抛出、捕获并处理后,所有生命期已结束的对象都会被正确地析构,它们所占用的空间会被正确地回收。下面描述编译器是如何实现栈回退机制的:

图中的 “FuncUnWind” 函数内,所有真实代码均以黑色和蓝色字体标示,编译器生成的代码则由灰色和橙色字体标明。此时,在图里给出的 nStep 变量和 tblUnwind 成员作用就十分明显了。
nStep 变量用于跟踪函数内局部对象的构造、析构阶段。再配合编译器为每个函数生成的 tblUnwind 表,就可以完成退栈机制。 表中的 pfnDestroyer 字段记录了对应阶段应当执行的析构操作(析构函数指针);pObj 字段则记录了与之相对应的对象 this 指针偏移。将 pObj 所指的偏移值加上当前栈框架基址(EBP),就是要代入 pfnDestroyer 所指析构函数的 this 指针,这样即可完成对该对象的析构工作。而 nNextIdx 字段则指向下一个需要析构对象所在的行(下标)。
在发生异常时,异常处理器首先检查当前函数栈框架内的 nStep 值,并通过 piHandler 取得 tblUnwind[] 表。然后将 nStep 作为下标带入表中,执行该行定义的析构操作,然后转向由 nNextIdx 指向的下一行,直到 nNextIdx 为 -1 为止。在当前函数的栈回退工作结束后,异常处理器可沿当前函数栈框架内 piPrev 的值回溯到异常处理链中的上一节点重复上述操作,直到所有回退工作完成为止。
值得一提的是,nStep 的值完全在编译时决定,运行时仅需执行若干次简单的整形立即数赋值(通常是直接赋值给CPU里的某个寄存器)。此外,对于所有内部类型以及使用了默认构造、析构方法(并且它的所有成员和基类也使用了默认方法)的类型,其创建和销毁均不影响 nStep 的值。
栈回退的触发:当发生异常且没有立即捕获时,C++ 会启动栈回退过程(stack unwinding)。栈回退会逐层销毁当前作用域中的对象(调用这些对象的析构函数),以确保资源得到释放。
析构函数在栈回退中的执行:在栈回退过程中,对象的析构函数会被调用。如果析构函数抛出异常,就会与原始异常相冲突,因为此时已经有一个异常正在传播。
异常处理机制的限制:C++ 的异常处理机制无法同时处理两个异常,所以如果在栈回退(异常传播)过程中析构函数再抛出新的异常,就会导致“异常中的异常”问题,这会调用
std::terminate()并结束程序。析构函数处理异常:
- 析构函数不应主动抛出异常:在 C++ 中,析构函数的一个核心原则是“不抛异常”。如果析构函数中的代码可能会抛出异常,应该尽量用 try-catch 捕获,并在必要时记录日志,而不是将异常传播到析构函数外。
- 在特殊情况下使用 std::uncaught_exceptions():如果析构函数确实执行了可能引发异常的复杂操作(例如文件操作、资源释放等),此时可以使用 [[C++11与14#uncaught_exceptions|C++17引入的std::uncaught_exceptions()]] 来检测当前是否存在未捕获的异常,以决定是否抑制抛出新的异常。
异常捕获
一个异常被抛出时,就会立即引发C++的异常捕获机制
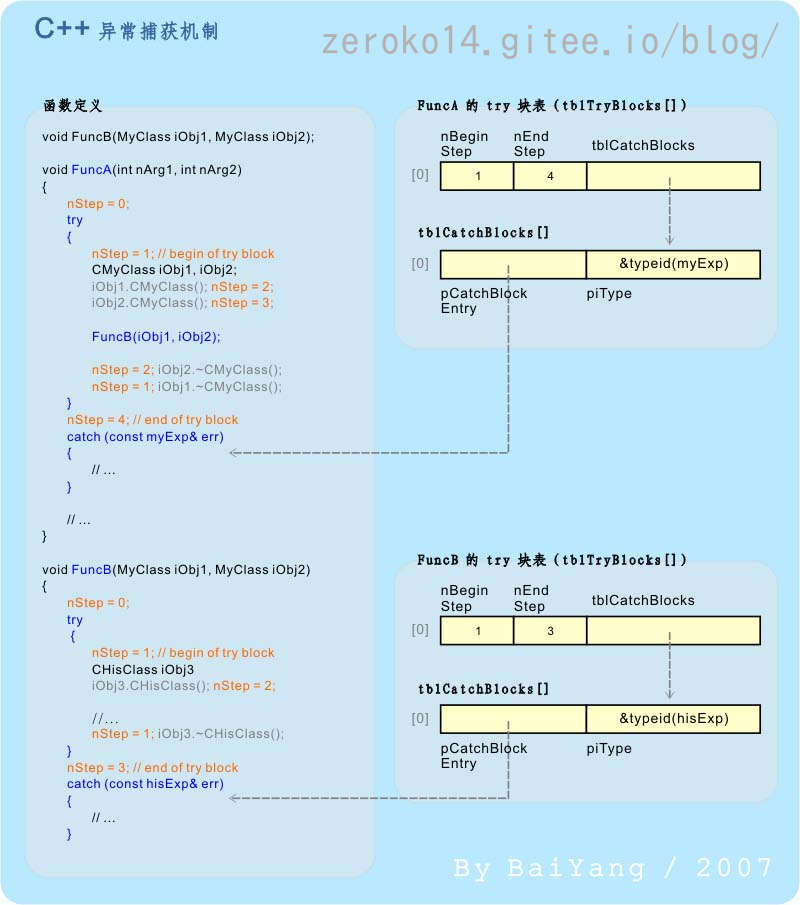
在上一小节中,我们已经看到了 nStep 变量在跟踪对象构造、析构方面的作用。实际上 nStep 除了能够跟踪对象创建、销毁阶段以外,还能够标识当前执行点是否在 try 块中,以及(如果当前函数有多个 try 块的话)究竟在哪个 try 块中。这是通过在每一个 try 块的入口和出口各为 nStep 赋予一个唯一 ID 值,并确保 nStep 在对应 try 块内的变化恰在此范围之内来实现的。
在具体实现异常捕获时,首先,C++ 异常处理器检查发生异常的位置是否在当前函数的某个 try 块之内。这项工作可以通过将当前函数的 nStep 值依次在 piHandler 指向 tblTryBlocks[] 表的条目中进行范围为 [nBeginStep, nEndStep) 的比对来完成。
例如:上图中的 FuncB 在 nStep == 2 时发生了异常,则通过比对 FuncB 的 tblTryBlocks[] 表发现 2∈[1, 3),故该异常发生在 FuncB 内的第一个 try 块中。其次,如果异常发生的位置在当前函数中的某个 try 块内,则尝试匹配该 tblTryBlocks[] 相应条目中的 tblCatchBlocks[] 表。tblCatchBlocks[] 表中记录了与指定 try 块配套出现的所有 catch 块相关信息,包括这个 catch 块所能捕获的异常类型及其起始地址等信息。若找到了一个匹配的 catch 块,则复制当前异常对象到此 catch 块,然后跳转到其入口地址执行块内代码。否则,则说明异常发生位置不在当前函数的 try 块内,或者这个 try 块中没有与当前异常相匹配的 catch 块,此时则沿着函数栈框架中 piPrev 所指地址(即:异常处理链中的上一个节点)逐级重复以上过程,直至找到一个匹配的 catch 块或到达异常处理链的首节点。对于后者,我们称为发生了未捕获的异常,对于 C++ 异常处理器而言,未捕获的异常是一个严重错误,将导致当前进程被强制结束。
抛出异常

在编译一段 C++ 代码时,编译器会将所有 throw 语句替换为其 C++ 运行时库中的某一指定函数,这里我们叫它 __CxxRTThrowExp(与本文提到的所有其它数据结构和属性名一样,在实际应用中它可以是任意名称)。该函数接收一个编译器认可的内部结构(我们叫它 EXCEPTION 结构)。这个结构中包含了待抛出异常对象的起始地址、用于销毁它的析构函数,以及它的 type_info 信息。对于没有启用 RTTI 机制(编译器禁用了 RTTI 机制或没有在类层次结构中使用虚表)的异常类层次结构,可能还要包含其所有基类的 type_info 信息,以便与相应的 catch 块进行匹配。
在图中的深灰色框图内,我们使用 C++ 伪代码展示了函数 FuncA 中的 “throw myExp(1);” 语句将被编译器最终翻译成的样子。实际上在多数情况下,__CxxRTThrowExp 函数即我们前面曾多次提到的“异常处理器”,异常捕获和栈回退等各项重要工作都由它来完成。__CxxRTThrowExp 首先接收(并保存)EXCEPTION 对象;然后从 TLS:Current ExpHdl 处找到与当前函数对应的 piHandler、nStep 等异常处理相关数据;并按照前文所述的机制完成异常捕获和栈回退。由此完成了包括“抛出”->“捕获”->“回退”等步骤的整套异常处理机制。
总结
程序在抛出异常后,则通过当前的 ExpHdl 获得 piHandle,该结构体中记录着栈回退表和 try 语句块的信息,首先去 try 语句块中寻找匹配的 catch 语句块,如果没有找到则进行进行栈回退到上一层的函数,重复这个过程直到找到匹配的 catch 语句块,如果一直到达异常处理链的顶点都没有找到,则强制结束进程。当然也有可能在当前的栈帧中就没有 try 语句块,那就直接进行栈回退去匹配 catch 语句块
Windows中的结构化异常处理
Microsoft Windows 带有一种名为“结构化异常处理”的机制,非常著名的“内存访问违例”出错对话框就是该机制的一种体现。Windows 结构化异常处理与前文讨论的 C++ 异常处理机制有惊人的相似之处,同样使用类似的链式结构实现。对于 Windows 下的应用程序,只需使用 SetUnhandledExceptionFilter API 注册异常处理器;用 FS:[0] 替代前文所述的 TLS: Current ExpHdl 等很少的改动,即可将此两种错误处理机制合而为一。这样做的优势十分明显:
- 由于可直接借助操作系统提供的机制,所以简化了 C++ 异常处理器的实现。
- 使“
catch (...)” 块得以捕获操作系统产生的异常(如:“内存访问违例”等等)。 - 使操作系统的异常处理机制能够捕获所有 C++ 异常。
实际上,大多数 Windows 下的 C++ 编译器的异常机制均使用这种方式实现。
开销分析
了解其某一特性的实现原理主要是为了避免错误地使用该特性。要达到这个目的,还要在了解实现原理的基础上进行一些额外的开销分析工作:
| 特性 | 时间开销 | 空间开销 |
|---|---|---|
| EHDL | 无运行时开销 | 每“C++函数”一个 EHDL 对象,其中的 tblTryBlocks[] 成员仅在函数中包含至少一个 try 块时使用。典型情况下小于 64 字节。 |
| C++栈框架 | 极高的 O(1) 效率,每次调用时进行3次额外的整形赋值和一次 TLS 访问。 | 每 调用两个指针和一个整形开销。典型情况下小于 16 字节。 |
| step 跟踪 | 极高的 O(1) 效率每次进出 try 块或对象构造/析构一次整形立即数赋值。 | 无(已记入 C++ 栈框架中的相应项目)。 |
| 异常的抛出、捕获和栈回退 | 异常的抛出是一次 O(1) 级操作。在单个函数中进行捕获和栈回退也均为 O(1) 操作。但异常捕获的总体成本为 O(m),其中 m 等于当前函数调用栈中,从抛出异常的位置到达匹配 catch 块之间所经过的函数调用中,包含 try 块(即:定义了有效 tblTryBlocks[])的函数个数。栈回退的总成本为 O(n),其中 n 等于当前函数调用栈中,从抛出异常的位置到达匹配 catch 块之间所经过的函数调用数。 | 在异常处理结束前,需保存异常对象及其析构函数指针和相应的 type_info 信息。具体根据对象尺寸、编译器选项(是否开启 RTTI)及异常捕获器的参数传递方式(传值或传址)等因素有较大变化。典型情况下小于 256 字节。 |
可以看出,在没有抛出异常时,C++ 的异常处理机制是十分有效的。在有异常被抛出后,可能会依当前函数调用栈的情形进行若干次整形比较(try块表匹配)操作,但这通常不会超过几十次。对于大多数 15 年前的 CPU 来说,整形比较也只需 1 时钟周期,所以异常捕获的效率还是很高的。栈回退的效率则与 return 语句基本相当。
考虑到即使是传统的函数调用、错误处理和逐级返回机制也不是没有代价的。这些开销在绝大多数情形下仍可以接受。空间开销方面,每“C++ 函数”一个 EHDL 结构体的引入在某些极端情形下会明显增加目标文件尺寸和内存开销。但是典型情况下,它们的影响并不大,但也没有小到可以完全忽略的程度。如果正在为一个资源严格受限的环境开发应用程序,你可能需要考虑关闭异常处理和 RTTI 机制以节约存储空间。
以上讨论的是一种典型的异常机制的实现方式,各具体编译器厂商可能有自己的优化和改进方案,但总体的出入不会很大。
全局终止处理程序
在头文件<exception>中
1 | std::terminate_handler set_terminate( std::terminate_handler f ); |
在 C++ 中,当一个异常没有被捕获时,程序会被 std::terminate 函数终止。默认情况下,这可能会调用 std::abort 来终止程序。但是你可以通过 set_terminate 函数来改变这个行为。
如果某个线程抛出了异常,但没有被捕获,那么该线程将会终止,并且会调用 std::terminate 。此时, set_terminate 设置的处理程序会被调用。 这也意味着无论在哪个线程中抛出未处理的异常,都会导致调用同一个终止处理程序。
虽然每个线程有自己的调用栈和异常处理机制,但 C++ 的设计使得未处理的异常能够通过 std::terminate 机制统一处理
这个函数本质上只是一个终止时被执行的程序,和异常机制无关
无法捕获的异常
致命错误(fatal errors)或运行时错误(runtime errors)。这些错误通常是由于程序在运行时遇到了一些无法恢复的情况而导致,无法通过 C++ 的异常处理机制进行捕获。
以下是一些常见的致命错误类型及其详细介绍:
- 栈溢出(Stack Overflow) 栈溢出通常发生在递归调用过深或分配了过多的局部变量时。当程序的栈空间被耗尽时,操作系统会终止该进程。这种情况不会抛出 C++ 异常,因此无法被捕获。
- 内存访问违规(Segmentation Fault) 当程序试图访问未分配或不允许访问的内存区域时,会导致内存访问违规。这种错误会导致操作系统发送信号(如 SIGSEGV),并终止程序执行。
- 非法指针解引用(Dereferencing Null or Invalid Pointers) 尝试解引用空指针或无效指针会导致程序崩溃。这种情况通常会导致访问违规错误,无法通过 C++ 的异常处理机制捕获。
- 资源耗尽(Resource Exhaustion) 当系统资源(如文件描述符、内存等)耗尽时,程序可能会崩溃。例如,过多的文件打开可能会导致无法打开新文件的错误。
- 断言失败(Assertion Failures) 使用
assert语句进行调试时,如果条件不满足,会导致程序终止。虽然这不是传统意义上的异常,但它会导致程序崩溃。 - 其他系统级错误 一些系统级错误(如硬件故障)也可能导致程序崩溃
C++标准异常库
标准库介绍
标准库中也提供了很多的异常类,它们是通过类继承组织起来的。异常类继承层级结构图如下:
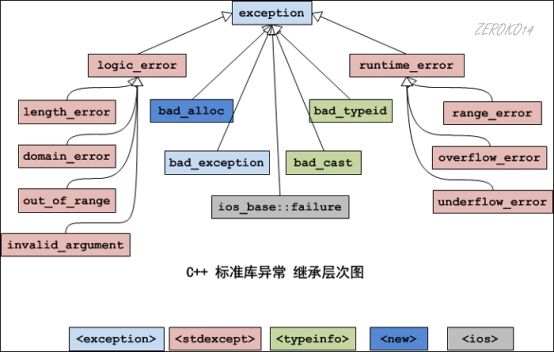
每个类所在的头文件在图下方标识出来。(颜色对应其头文件)
标准异常类的成员:
- 在上述继承体系中,每个类都有提供了构造函数、复制构造函数、和赋值操作符重载。
- logic_error类及其子类、runtime_error类及其子类,它们的构造函数是接受一个string类型的形式参数,用于异常信息的描述
- 所有的异常类都有一个what()方法,返回const char* 类型(C风格字符串)的值,描述异常信息。
标准异常类的具体描述:
| 异常名称 | 描述 |
|---|---|
| exception | 所有标准异常类的父类 |
| bad_alloc | 当operator new and operator new[],请求分配内存失败时 |
| bad_exception | 这是个特殊的异常,如果函数的异常抛出列表里声明了bad_exception异常,当函数内部抛出了异常抛出列表中没有的异常,这是调用的unexpected函数中若抛出异常,不论什么类型,都会被替换为bad_exception类型 |
| bad_typeid | 使用typeid操作符,操作一个NULL指针,而该指针是带有虚函数的类,这时抛出bad_typeid异常 |
| bad_cast | 使用dynamic_cast转换引用失败的时候 |
| ios_base::failure | io操作过程出现错误 |
| logic_error | 逻辑错误,可以在运行前检测的错误 |
| runtime_error | 运行时错误,仅在运行时才可以检测的错误 |
logic_error的子类:
| 异常名称 | 描述 |
|---|---|
| length_error | 试图生成一个超出该类型最大长度的对象时,例如vector的resize操作 |
| domain_error | 参数的值域错误,主要用在数学函数中。例如使用一个负值调用只能操作非负数的函数 |
| out_of_range | 超出有效范围 |
| invalid_argument | 参数不合适。在标准库中,当利用string对象构造bitset时,而string中的字符不是’0’或’1’的时候,抛出该异常 |
runtime_error的子类:
| 异常名称 | 描述 |
|---|---|
| range_error | 计算结果超出了有意义的值域范围 |
| overflow_error | 算术计算上溢 |
| underflow_error | 算术计算下溢 |
| invalid_argument | 参数不合适。在标准库中,当利用string对象构造bitset时,而string中的字符不是’0’或’1’的时候,抛出该异常 |
案例如下:
1 |
|
编写自己的异常类
- 标准库中的异常是有限的;
- 在自己的异常类中,可以添加自己的信息。(标准库中的异常类值允许设置一个用来描述异常的字符串)。
如何编写自己的异常类?
- 建议自己的异常类要继承标准异常类。因为C++中可以抛出任何类型的异常,所以我们的异常类可以不继承自标准异常,但是这样可能会导致程序混乱,尤其是当我们多人协同开发时。
- 当继承标准异常类时,应该重载父类的what函数和虚析构函数。
- 因为栈展开的过程中,要复制异常类型,那么要根据你在类中添加的成员考虑是否提供自己的复制构造函数。
1 | //自定义异常类 |
Function-try-block
围绕函数体建立异常处理程序
是一种 函数体 的替代语法形式,是函数定义的一部分。
它的行为比较复杂,对于普通函数和构造函数析构函数在到达catch-block结尾时候的行为不太一致,可以认为是比较坑的。
函数 try 块的主要目的是应对从构造函数中的成员初始化器列表抛出的异常,进行记录并重抛,修改异常对象并重抛,抛出一个不同的异常,或终止程序。它们很少为析构函数或常规函数所用。
1 |
|
在进入任何构造函数上的函数 try 块的 catch 子句前,所有完整构造的成员和基类都会被销毁。
如果构造函数或析构函数上使用的函数 try 块的 catch 子句访问对象的基类或非静态成员,则行为未定义。
异常安全
什么是异常安全的函数,需要满足下面两条:
- 不泄露任何资源
- 不允许数据结构遭到损坏
面对构造和析构:
- 构造函数提供强异常保证:确保构造函数要么成功完成创建对象,要么失败后不影响程序状态(强异常保证)
- 析构函数提供无失败保证:确保析构函数不会抛出异常,以保证资源安全地释放。(最稳妥是使用 [[C++11与14#noexcept]] 修饰析构函数)
局部异常处理的思想重点在于:
抛出异常的合理性:构造函数中若遇到无法恢复的错误(如内存不足),应抛出异常;但对于非关键性错误(如一些简单的参数错误),可以考虑通过其他手段处理,减少异常的传播成本。
C++异常的弊端
性能开销
C++ 异常在实现上需要运行时支持和额外的元数据表(如异常处理表),导致:
- 额外的二进制体积:异常表和元数据增加了可执行文件大小。
- 性能不可预测:异常路径的执行开销高,可能导致分支预测失败和缓存抖动。
- 零成本异常模型:即使不抛异常,生成的二进制也会包含额外的异常元数据,增加了代码体积。
实时系统中的不可预测性
在 嵌入式系统 或 硬实时系统(如航空航天、汽车控制系统)中,时间可预测性非常关键。
C++ 异常的不可预测性来源于:
- 异常传播时间不确定。
- 栈回溯(stack unwinding)的时间不可控。
catch块匹配的复杂度取决于异常层次结构和运行时开销。
实时系统中,异常可能导致任务无法按时完成,破坏系统的时间约束。
异常安全与资源泄漏风险
如果代码没有正确实现 RAII(资源获取即初始化),异常可能导致资源泄漏:
使用 RAII 可以解决这个问题,但需要额外的代码管理规范。因此,一些公司选择完全禁用异常,以强制开发者显式管理资源释放。
兼容性与跨语言调用
在混合使用 C 和 C++ 的项目中,异常处理会带来兼容性问题。
C 语言不支持异常。
解决方式是确保异常不会越过 C 和 C++ 的边界,即确保所有异常在进入 C 函数之前被捕获,并在 C++ 层进行处理
跨语言异常传播困难(如 C++ 调用 Python 或 Rust)。
异常引擎在不同平台上实现差异较大(如 Windows SEH、Itanium ABI)。
调试复杂度增加
异常会引入更复杂的栈回溯(Stack Unwinding),使调试变得困难。
- 栈回溯过程复杂,难以准确定位异常发生的源头。
- 异常可能被多个
catch块拦截,导致错误难以重现。
代码可读性与维护性下降
- 滥用异常可能掩盖逻辑错误,降低代码可读性。
- 异常与正常控制流混杂,维护难度增加。
C++输入和输出流
流的概念和流类库的结构
程序的输入指的是从输入文件将数据传送给程序,程序的输出指的是从程序将数据传送给输出文件。
C++输入输出包含以下三个方面的内容:
对系统指定的标准设备的输入和输出。即从键盘输入数据,输出到显示器屏幕。这种输入输出称为标准的输入输出,简称标准I/O。
以外存磁盘文件为对象进行输入和输出,即从磁盘文件输入数据,数据输出到磁盘文件。以外存文件为对象的输入输出称为文件的输入输出,简称文件I/O。
对内存中指定的空间进行输入和输出。通常指定一个字符数组作为存储空间(实际上可以利用该空间存储任何信息)。这种输入和输出称为字符串输入输出,简称串I/O。
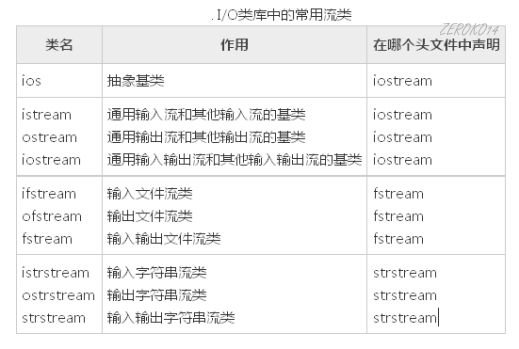
C++编译系统提供了用于输入输出的iostream类库。iostream这个单词是由3个部 分组成的,即i-o-stream,意为输入输出流。在iostream类库中包含许多用于输入输出的 类。常用的见表
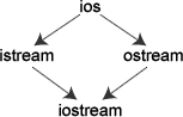
ios是抽象基类,由它派生出istream类和ostream类,两个类名中第1个字母i和o分别代表输入(input)和输出(output)。 istream类支持输入操作,ostream类支持输出操作, iostream类支持输入输出操作。iostream类是从istream类和ostream类通过多重继承而派生的类。其继承层次见上图表示。
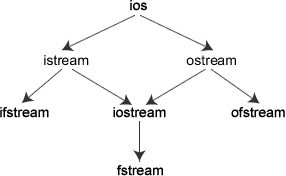
C++对文件的输入输出需要用ifstrcam和ofstream类,两个类名中第1个字母i和o分别代表输入和输出,第2个字母f代表文件 (file)。ifstream支持对文件的输入操作, ofstream支持对文件的输出操作。类ifstream继承了类istream,类ofstream继承了类ostream,类fstream继承了 类iostream。见图
I/O类库中还有其他一些类,但是对于一般用户来说,以上这些已能满足需要了。
与iostream类库有关的头文件
iostream类库中不同的类的声明被放在不同的头文件中,用户在自己的程序中用#include命令包含了有关的头文件就相当于在本程序中声明了所需 要用到的类。可以换 —种说法:头文件是程序与类库的接口,iostream类库的接口分别由不同的头文件来实现。常用的有
- iostream 包含了对输入输出流进行操作所需的基本信息。
- fstream 用于用户管理的文件的I/O操作。
- strstream 用于字符串流I/O。
- stdiostream 用于混合使用C和C + +的I/O机制时,例如想将C程序转变为C++程序。
- iomanip 在使用格式化I/O时应包含此头文件。
在iostream头文件中定义的流对象
在 iostream 头文件中定义的类有 ios,istream,ostream,iostream,istream 等。
在iostream头文件中不仅定义了有关的类,还定义了4种流对象,
| 对象 | 含义 | 对应设备 | 对应的类 | c语言中相应的标准文件 |
|---|---|---|---|---|
| cin | 标准输入流 | 键盘 | istream_withassign | stdin |
| cout | 标准输出流 | 屏幕 | ostream_withassign | stdout |
| cerr | 标准错误流 | 屏幕 | ostream_withassign | stderr |
| clog | 标准日志流 | 屏幕 | ostream_withassign | stderr |
在iostream头文件中定义以上4个流对象用以下的形式(以cout为例):
ostream cout ( stdout);
在定义cout为ostream流类对象时,把标准输出设备stdout作为参数,这样它就与标准输出设备(显示器)联系起来,如果有
cout <<3;
就会在显示器的屏幕上输出3。
在iostream头文件中重载运算符
“<<”和“>>”本来在C++中是被定义为左位移运算符和右位移运算符的,由于在iostream头文件中对它们进行了重载, 使它们能用作标准类型数据的输入和输出运算符。所以,在用它们的程序中必须用#include命令把iostream包含到程序中。
1 |
- >>a表示将数据放入a对象中。
- <<a表示将a对象中存储的数据拿出。
标准I/O流
标准I/O对象:cin,cout,cerr,clog
cout流对象
cout是console output的缩写,意为在控制台(终端显示器)的输出。强调几点。
cout不是C++预定义的关键字,它是ostream流类的对象,在iostream中定义。 顾名思义,流是流动的数据,cout流是流向显示器的数据。cout流中的数据是用流插入运算符“<<”顺序加入的。如果有:
cout<<”I “<<”study C++ “<<”very hard. << “hello world !”;按顺序将字符串”I “, “study C++ “, “very hard.”插人到cout流中,cout就将它们送到显示器,在显示器上输出字符串”I study C++ very hard.”。cout流是容纳数据的载体,它并不是一个运算符。人们关心的是cout流中的内容,也就是向显示器输出什么。
用“cout<<”输出基本类型的数据时,可以不必考虑数据是什么类型,系统会判断数据的类型,并根据其类型选择调用与之匹配的运算符重载函数。这个过程都是自动的,用户不必干预。如果在C语言中用prinf函数输出不同类型的数据,必须分别指定相应的输出格式符,十分麻烦,而且容易出错。C++的I/O机制对用户来说,显然是方便而安全的。
cout流在内存中对应开辟了一个缓冲区,用来存放流中的数据,当向cout流插人一个endl时,不论缓冲区是否已满,都立即输出流中所有数据,然后插入一个换行符, 并刷新流(清空缓冲区)。注意如果插人一个换行符”\n“(如cout<<a<<”\n”),则只输出和换行,而不刷新cout 流(但并不是所有编译系统都体现出这一区别)。
在iostream中只对”<<”和”>>”运算符用于标准类型数据的输入输出进行了重载,但未对用户声明的类型数据的输入输出进行重载。如果用户声明了新的类型,并希望用”<<”和”>>”运算符对其进行输入输出,按照重运算符重载来做。
cerr流对象
cerr流对象是标准错误流,cerr流已被指定为与显示器关联。cerr的 作用是向标准错误设备(standard error device)输出有关出错信息。cerr与标准输出流cout的作用和用法差不多。但有一点不同:cout流通常是传送到显示器输出,但也可以被重定向输出到磁盘文件,而cerr流中的信息只能在显示器输出。当调试程序时,往往不希望程序运行时的出错信息被送到其他文件,而要求在显示器上及时输出,这时 应该用cerr。cerr流中的信息是用户根据需要指定的。
clog流对象
clog流对象也是标准日志流,它是console log的缩写。它的作用和cerr相同,都是在终端显示器上显示出错误信息。区别:cerr是不经过缓冲区,直接向显示器上输出有关信息,而clog中的信息存放在缓冲区中,缓冲区满后或遇endl时向显示器输出。
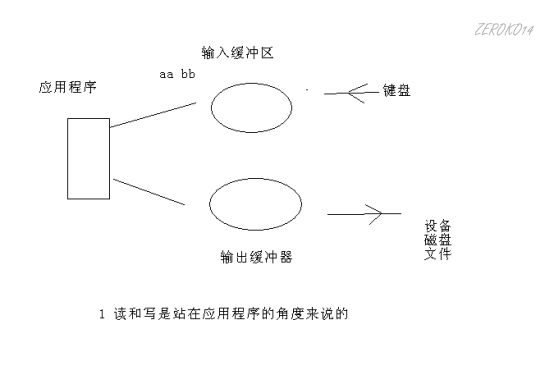
缓冲区的概念:
标准输入流
标准输入流对象cin,重点掌握的函数
- cin.get() //一次只能读取一个字符
- cin.get(一个参数) //读一个字符
- cin.get(两个参数) //可以读字符串
- cin.getline()//读字符串
- cin.ignore()//忽略,默认忽略1个,若填入参数n代表忽略n个字符
- cin.peek()//偷窥,从缓冲区只看不取
- cin.putback()//放回,放回缓冲区队列头
- cin.fail()//标志位
- cin.clear()//标志位复位为0(用来更改cin的状态标示符的)
- cin.sync()//用来清除缓存区的数据流(vs2015环境下不能使用,尽量用cin.ignore替代)
【重点注意】cin.clear和cin.fail的区别
1 | int main() |
【重点注意】cin.get和cin.getline的区别


- cin.get:遇换行符结束读取,换行符遗留在缓冲区,所以要处理。
- cin.getline:已读取了size-1个字符或遇到了文件尾或遇到了分隔符结束读取,若遇到换行符结束读取,丢弃换行符(换行符不在缓冲区也不被buf取走,而是直接丢掉)。
【重点注意】cin.ignore和cin.sync的区别
cin.ignore(a,ch)
从输入流(cin)中提取字符,提取的字符被忽略(ignore),不被使用。每抛弃一个字符,它都要计数和比较字符:如果计数值达到a或者被抛弃的字符是ch,则cin.ignore()函数执行终止;否则,它继续等待。
它的一个常用功能就是用来清除以回车结束的输入缓冲区的内容,消除上一次输入对下一次输入的影响。
比如可以这么用:
cin.ignore(1024,’\n’),通常把第一个参数设置得足够大,这样实际上总是只有第二个参数’\n’起作用,所以这一句就是把回车(包括回车)之前的所以字符从输入缓冲(流)中清除出去。
cin.sync()
sync()的作用就是清除输入缓冲区。成功时返回0,失败时badbit会置位,函数返回-1.
另外,对于绑定了输出的输入流,调用sync(),还会刷新输出缓冲区。
【重点注意】实践得知,vs2015下,sync并不能清空输入缓冲区,因此用ignore替代
1 | cin.ignore(std::numeric_limits<int>::max(), '\n');//把第一个参数设置得足够大,这样实际上总是只有第二个参数'\n'起作用,所以这一句就是把回车(包括回车)之前的所以字符从输入缓冲(流)中清除出去,用此来达到清空数据流的操作;这样就能吃掉一大段了,但理论上依旧不能保证吃掉一行 |
程序执行时有一个标志变量来标志输入的异常状态,其中有三位标志位分别用来标志三种异常信息,他们分别是:failbit,eofbit,badbit。这三个标志位在标志变量中是这样分配的:
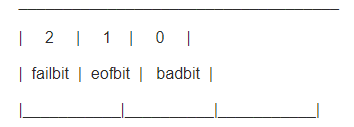
ios类定义了这四个常量badbit, eofbit, failbit, goodbit,其实这四个标志常量就是取对应标志位的掩码,也即输入的四种异常情况!
- ios::badbit 001 输入(输出)流出现致命错误,不可挽回
- ios::eofbit 010 已经到达文件尾
- ios::failbit 100 输入(输出)流出现非致命错误,可挽回
- ios::goodbit 000 流状态完全正常, 各异常标志位都为0
可以用输出语句来验证这几个常量的值:
1 | cout << ios:: failbit << endl; |
【注意】cin>>与cin.getline的返回值相同
当读取不匹配类型的值或EOF时会造成流错误而返回NULL。(只有goodbit才会返回非NULL)
其他函数讲解:
1 | //cin.get |
标准输出流
- cout.flush() //刷新缓冲区 Linux下有效
- cout.put() //向缓冲区写字符
- cout.write() //从buff中向缓冲区写num个字节到当前输出流中。
1 | //cout.flush 刷新缓冲区,linux下有效 |
格式化输出
在输出数据时,为简便起见,往往不指定输出的格式,由系统根据数据的类型采取默认的格式,但有时希望数据按指定的格式输出,如要求以十六进制或八进制形式输出一个整数,对输出的小数只保留两位小数等。有两种方法可以达到此目的。
- 使用控制符的方法;
- 使用流对象的有关成员函数。
使用流对象的有关成员函数
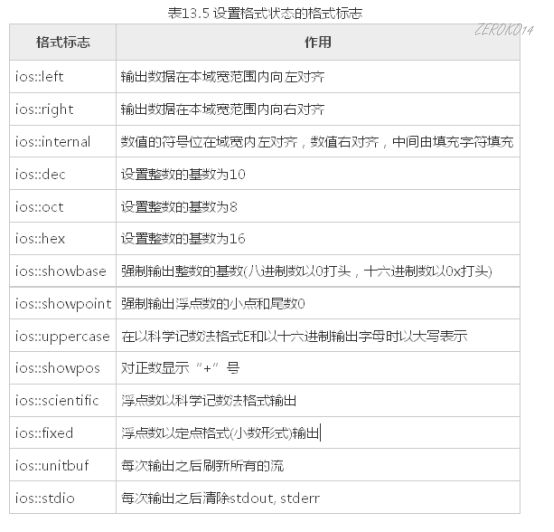
通过调用流对象cout中用于控制输出格式的成员函数来控制输出格式。用于控制输出格式的常用的成员函数如下:

流成员函数setf和控制符setiosflags括号中的参数表示格式状态,它是通过格式标志来指定的。格式标志在类ios中被定义为枚举值。因此在引用这些格式标志时要在前面加上类名ios和域运算符“::”。格式标志见表13.5。
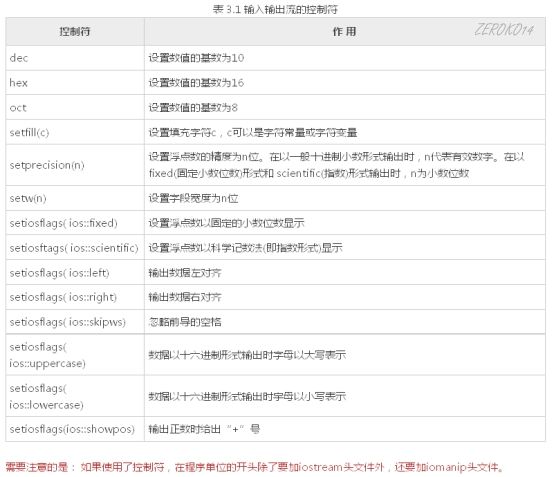
控制符格式化输出
C++提供了在输入输出流中使用的控制符(有的书中称为操纵符)。(需要iomanip头文件)
1 | //通过流成员函数 |
对程序的几点说明(注意点)
成员函数width(n)和控制符setw(n)只对其后的第一个输出项有效。(之后依然按按系统默认的域宽输出)
如果要求在输出数据时都按指定的同一域宽n输出,不能只调用一次width(n), 而必须在输出每一项前都调用一次width(n)
在表13.5中的输出格式状态分为5组,每一组中同时只能选用一种(例如dec、hex和oct中只能选一,它们是互相排斥的)。在用成员函数setf和 控制符setiosflags设置输出格式状态后,如果想改设置为同组的另一状态,应当调用成员函数unsetf(对应于成员函数self)或 resetiosflags(对应于控制符setiosflags),先终止原来设置的状态。然后再设置其他状态,大家可以从本程序中看到这点。程序在开始虽然没有用成员函数self和控制符setiosflags设置用dec输出格式状态,但系统默认指定为dec,因此要改变为hex或oct,也应当先 用unsetf 函数终止原来设置。若未终止格式就设置别的格式,设置的格式均不起作用,系统依然以未终止格式输出。
用setf 函数设置格式状态时,可以包含两个或多个格式标志,由于这些格式标志在ios类中被定义为枚举值,每一个格式标志以一个二进位代表,因此可以用位或运算符“|”组合多个格式标志。如:
1
cout.setf(ios::internal I ios::showpos); //包含两个状态标志,用"|"组合
可以看到:对输出格式的控制,既可以用控制符,也可以用cout流的有关成员函数,二者的作用是相同的。控制符是在头文件iomanip中定义的,因此用控制符时,必须包含iomanip头文件。cout流的成员函数是在头文件iostream 中定义的,因此只需包含头文件iostream,不必包含iomanip。许多程序人员感到使用控制符方便简单,可以在一个cout输出语句中连续使用多种控制符。
文件读写
头文件:<fstream>
文件流类和文件流对象
输入输出是以系统指定的标准设备(输入设备为键盘,输出设备为显示器)为对象的。在实际应用中,常以磁盘文件作为对象。即从磁盘文件读取数据,将数据输出到磁盘文件。
和文件有关系的输入输出类主要在fstream.h这个头文件中被定义,在这个头文件中主要被定义了三个类,由这三个类控制对文件的各种输入输出操作,他们分别是ifstream、ofstream、fstream,其中fstream类是由iostream类派生而来,他们之间的继承关系见下图所示:
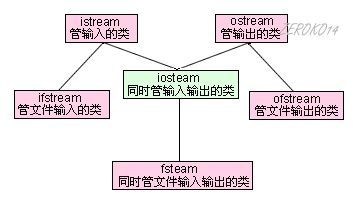 (图中打错了,应该是fstream)
(图中打错了,应该是fstream)
由于文件设备并不像显示器屏幕与键盘那样是标准默认设备,所以它在fstream头文件中是没有像cout那样预先定义的全局对象,所以我们必须自己定义一个该类的对象。ifstream类,它是从istream类派生的,用来支持从磁盘文件的输入。ofstream类,它是从ostream类派生的,用来支持向磁盘文件的输出。
fstream类,它是从iostream类派生的,用来支持对磁盘文件的输入输出。
C++打开文件
所谓打开(open)文件是一种形象的说法,如同打开房门就可以进入房间活动一样。 打开文件是指在文件读写之前做必要的准备工作,包括:
- 为文件流对象和指定的磁盘文件建立关联,以便使文件流流向指定的磁盘文件。
- 指定文件的工作方式,如:该文件是作为输入文件还是输出文件,是ASCII文件还是二进制文件等。
以上工作可以通过两种不同的方法实现:
调用文件流的成员函数open。如
1
2ofstream outfile; //定义ofstream类(输出文件流类)对象outfile
outfile.open("f1.dat",ios::out); //使文件流与f1.dat文件建立关联第2行是调用输出文件流的成员函数open打开磁盘文件f1.dat,并指定它为输出文件,文件流对象outfile将向磁盘文件f1.dat输出数据。ios::out是I/O模式的一种,表示以输出方式打开一个文件。或者简单地说,此时f1.dat是一个输出文件,接收从内存输出的数据。
磁盘文件名可以包括路径,如”c:\new\f1.dat”,如缺省路径,则默认为当前目录下的文件。
在定义文件流对象时指定参数
在声明文件流类时定义了带参数的构造函数,其中包含了打开磁盘文件的功能。因此,可以在定义文件流对象时指定参数,调用文件流类的构造函数来实现打开文件的功能。
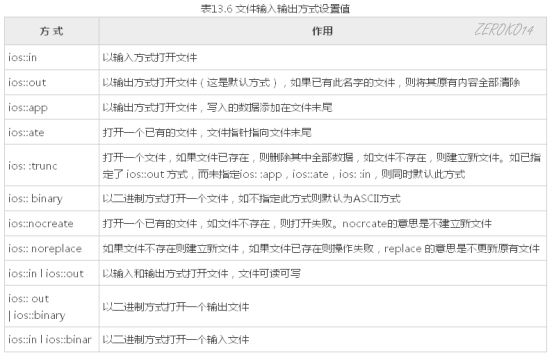
几点说明:
- 新版本的I/O类库中不提供ios::nocreate和ios::noreplace。
- 每一个打开的文件都有一个文件指针,该指针的初始位置由I/O方式指定,每次读写都从文件指针的当前位置开始。每读入一个字节,指针就后移一个字节。当文件指针移到最后,就会遇到文件结束EOF(文件结束符也占一个字节,其值为-1),此时流对象的成员函数eof的值为非0值(一般设为1),表示文件结束了。
- 可以用“位或”运算符“|”对输入输出方式进行组合,如表13.6中最后3行所示那样。还可以举出下面一些例子:
ios::in | ios:: noreplace //打开一个输入文件,若文件不存在则返回打开失败的信息
ios::app | ios::nocreate //打开一个输出文件,在文件尾接着写数据,若文件不存在,则返回打开失败的信息
ios::out l ios::noreplace //打开一个新文件作为输出文件,如果文件已存在则返回打开失败的信息
ios::in l ios::out I ios::binary //打开一个二进制文件,可读可写
但不能组合互相排斥的方式,如 ios::nocreate l ios::noreplace。 - 如果打开操作失败,open函数的返回值为0(假),如果是用调用构造函数的方式打开文件的,则流对象的值为0。可以据此测试打开是否成功。如
if(outfile.open(“f1.bat”, ios::app) ==0)
cout <<”open error”;
或
if( !outfile.open(“f1.bat”, ios::app) )
cout <<”open error”;
C++关闭文件
在对已打开的磁盘文件的读写操作完成后,应关闭该文件。关闭文件用成员函数close。如:outfile.close( ); //将输出文件流所关联的磁盘文件关闭
**所谓关闭,实际上是解除该磁盘文件与文件流的关联,原来设置的工作方式也失效,这样,就不能再通过文件流对该文件进行输入或输出。**此时可以将文件流与其他磁盘文件建立关联,通过文件流对新的文件进行输入或输出。如:
1 | outfile.open("f2.dat",ios::app|ios::nocreate);//(文件路径,打开方式) |
此时文件流outfile与f2.dat建立关联,并指定了f2.dat的工作方式。
C++对ASCII文件的读写操作
如果文件的每一个字节中均以ASCII代码形式存放数据,即一个字节存放一个字符,这个文件就是ASCII文件(或称字符文件)。程序可以从ASCII文件中读入若干个字符,也可以向它输出一些字符。
用流插入运算符“<<”和流提取运算符“>>”输入输出标准类型的数据。“<<”和“ >>”都巳在iostream中被重载为能用于ostream和istream类对象的标准类型的输入输出。由于ifstream和 ofstream分别是ostream和istream类的派生类;因此它们从ostream和istream类继承了公用的重载函数,所以在对磁盘文件的操作中,可以通过文件流对象和流插入运算符“<<”及 流提取运算符“>>”实现对磁盘 文件的读写,如同用cin、cout和<<、>>对标准设备进行读写一样。
用文件流的put、get、geiline等成员函数进行字符的输入输出,:用C++流成员函数put输出单个字符、C++ get()函数读入一个字符和C++ getline()函数读入一行字符。
1 | int main(){ |
4种ASCII读写方式
1 | //打开文件 |
【注意】全局getline和ifstream流对象中的getline的区别
- ifstream的对象ifs中存在ifs.getline(读到哪个buf,读多少num)函数
- 此外还存在一个全局函数(需要
头文件)getline(从哪读ifs,读到哪buf(string类型),分隔符[可选项])
【注意】
1 | //将文件指针移动到文件开头(file为文件流对象) |
C++对二进制文件的读写操作
二进制文件不是以ASCII代码存放数据的,它将内存中数据存储形式不加转换地传送到磁盘文件,因此它又称为内存数据的映像文件。因为文件中的信息不是字符数据,而是字节中的二进制形式的信息,因此它又称为字节文件。
对二进制文件的操作也需要先打开文件,用完后要关闭文件。在打开时要用ios::binary指定为以二进制形式传送和存储。二进制文件除了可以作为输入文件或输出文件外,还可以是既能输入又能输出的文件。这是和ASCII文件不同的地方。
用成员函数read和write读写二进制文件
对二进制文件的读写主要用istream类的成员函数read和write来实现。这两个成员函数的原型为
1 | istream& read(char *buffer,int len); |
字符指针buffer指向内存中一段存储空间。len是读写的字节数。调用的方式为:
1 | a. write(p1,50); |
上面第一行中的a是输出文件流对象,write函数将字符指针p1所给出的地址开始的50个字节的内容不加转换地写到磁盘文件中。在第二行中,b是输入文件流对象,read 函数从b所关联的磁盘文件中,读入30个字节(或遇EOF结束),存放在字符指针p2所指的一段空间内。
1 | class Person{ |
断言
断言就是对一个表达式的判断,当表达式为假时就输出诊断消息并调用abort()函数中止程序。
断言的使用格式:assert (bool_constexpr );
如果指定的表达式为 false,程序会终止并显示诊断消息。
assert.h 和 cassert 头文件分别是用于在 C 和 C++ 中进行断言(assertion)的头文件
- 断言语句仅在定义了
_DEBUG时才进行编译。- 在发布版本中,断言不会产生开销或性能成本。
断言不能代替程序中的错误检查,只能出现于理所当然正确的地方
RAII
RAII可管理的资源远不止堆空间,还包括文件句柄,网络连接,锁,窗体句柄等一切需要成对获取与释放的资源
C++与C性能分析
其实对一个优秀的编译器而言,C++的各种特性本身就是使用C/汇编加以千锤百炼而最优化实现的。可以说,想用C甚至汇编比编译器更高效地实现某个C++特性几乎是不可能的。要是真能做到这一点的话,就应该去写个编译器造福广大程序员才对
相对与传统C程序而言,C++中有可能引入额外运行时开销的新特性包括:
虚基类
虚函数
RTTI(dynamic_cast和typeid)
异常
异常,对于大多数现代编译器来说,在正常情况(未抛出异常)下,try块中的代码执行效率和普通代码一样高,而且由于不再需要使用传统上通过返回值或函数调用来判断错误的方式,代码的实际执行效率还可能进一步提高。抛出和捕捉异常的效率也只是在某些情况下才会稍低于函数正常返回的效率,何况对于一个编写良好的程序,抛出和捕捉异常的机会应该不多。
对象的构造和析构
对象的构造和析构开销也不总是存在。对于不需要初始化/销毁的类型,并没有构造和析构的开销,相反对于那些需要初始化/销毁的类型来说,即使用传统的C方式实现,也至少需要与之相当的开销。这里要注意的一点是尽量不要让构造和析构函数过于臃肿,特别是在一个类层次结构中更要注意。时刻保持你的构造、析构函数中只有最必要的初始化和销毁操作,把那些并不是每个(子)对象都需要执行的操作留给其他方法和派生类去解决
C++之所以 被广泛认为比C“低效”,其根本原因在于:由于程序员对某些特性的实现方式及其产生的开销不够了解,致使他们在错误的场合使用了错误的特性。而这些错误基本都集中在:
- 把异常当作另一种流控机制,而不是仅将其用于错误处理中
- 一个类和/或其基类的构造、析构函数过于臃肿,包含了很多非初始化/销毁范畴的代码
- 滥用或不正确地使用RTTI、虚函数和虚基类机制
将C源代码封装成C++类代码
- 将宏定义—>常量const
- 主要是整形和字符串
- 一些连续的整形值可以定义成枚举类型
- 宏函数
- 简单的宏函数可以改写成内联函数
- 如果比较复杂,可以改写成类的成员函数
- 若成员函数都用到了某个变量,可以将这个变量设置为类的成员变量
- 通过类的访问控制权限控制
- 一般只有public成员可以对外界访问,不被外界访问的可以设置成private成员或者protect成员
内存泄露检测知识点(调试技巧注意点篇)
【重点】(崩溃的调试定位问题技巧)崩溃的时候在弹出的对话框按相应按钮进入调试,按Alt+7键查看Call Stack即“调用堆栈”里面从上到下列出的对应从里层到外层的函数调用历史。双击某一行可将光标定位到此次调用的源代码或汇编指令处,看不懂时双击下一行,直到能看懂为止。
VC编译选项“基本运行时检查”的作用
C++如何使用第三方库
- C++最原始的方法就是自己建一个deps目录,把依赖的库的源代码直接放里面
- apt-get install libxxx-dev
libxxx-dev是一个开发包,通常包含用于编译和链接程序的头文件和库 - C++有大量的包管理器,包括 buckaroo、vcpkg、cget、conan、conda、cpm、cppan、hunter 等。
- xmake内含自己的包管理器
p.s.这里提一嘴谷歌的构建工具bazel,以及魔改版的blade
homebrew
配合cmake使用开发包
在 CMakeLists.txt 中设置 CMAKE_PREFIX_PATH:
Homebrew 将包安装在固定的目录,通常是
/opt/homebrew/Cellar/。在 CMakeLists.txt 文件中,需要手动设置
CMAKE_PREFIX_PATH变量,指向 Homebrew 包的安装目录:
1
set(CMAKE_PREFIX_PATH /opt/homebrew/Cellar/)#如果是在intel mac上应该是/opt/homebrew/xxx
这样 CMake 就能够找到 Homebrew 安装的包的头文件和库文件。
使用 find_package() 命令查找并链接包:
在 CMakeLists.txt 中使用
find_package()命令来查找需要的包,例如 OpenCV:
1
find_package(OpenCV REQUIRED)
然后在目标库上链接该包:
1
target_link_libraries(my_target PRIVATE ${OpenCV_LIBS})
vcpkg包管理器
vcpkg是Microsoft的跨平台开源软件包管理器,极大地简化了 Windows、Linux 和 macOS 上第三方库的下载与安装。如果项目要使用第三方库,建议通过 vcpkg 来安装它们。vcpkg 同时支持开源和专有库。
源码级兼容
在编写C++程序时,一直有二进制兼容的问题。在可执行文件链接到三方库时,编译器的类型和版本的统一非常重要。Vcpkg通过下载源码(而不是二进制文件)的方式来提供三方库。
下载与安装
下面介绍的是二进制方式安装:
下载
git clone https://github.com/microsoft/vcpkg编译
- Windows平台:在cmd中执行Vcpkg工程目录下的“bootstrap-vcpkg.bat”命令,编译好后会在同级目录下生成vcpkg.exe文件。
- Linux/mac平台:在命令行中执行在vcpkg工程目录下
sudo bash ./bootstrap-vcpkg.sh命令,会生成一个可执行文件vcpkg。定义环境变量VCPKG_ROOT="~/vcpkg"
想到处使用别忘了添加到path中,比如mac:
export PATH=$PATH:$VCPKG_ROOT
注意clion想要使用系统带的vcpkg,路径就设置为~/vcpkg,全局就可以使用同一个vcpkg
使用
查看Vcpkg支持的库 vcpkg search xxxx
安装一个库 vcpkg install xxxx
查看已安装的库 vcpkg list
移除已经安装的库 vcpkg remove xxxx
集成使用
Vcpkg提供了一套机制,可以全自动的适配目录,而开发者不需要关心已安装的库的目录在哪里,也不需要设置
集成到全局:
vcpkg integrate install1
2
3//输入vcpkg integrate install后,返回:
Applied user-wide integration for this vcpkg root.`
`CMake projects should use: "-DCMAKE_TOOLCHAIN_FILE=/Users/zeroko/vcpkg/scripts/buildsystems/vcpkg.cmake"表示集成成功,并提供了一个在CMake项目中使用vcpkg的提示。你可以将该指令添加到你的CMake构建命令中,以确保CMake能够正确地使用vcpkg安装的库。
在项目根目录执行命令:
cmake -DCMAKE_TOOLCHAIN_FILE=/Users/zeroko/vcpkg/scripts/buildsystems/vcpkg.cmake .(.表示CMakeLists.txt的路径位置)具体而言,
vcpkg integrate install命令会执行以下操作:在当前用户的目录下创建一个名为
.vcpkg-root的隐藏文件夹,用于存储vcpkg的集成信息。将vcpkg的路径添加到系统环境变量中,以便在构建项目时能够找到vcpkg。
针对不同的开发环境,自动配置构建工具(如CMake、MSBuild等)的相关设置,以确保它们能够正确地使用vcpkg。
移除集成:
vcpkg integrate remove
之后与CMake一起使用时,需添加依赖以及在设置路径
与CMAKE配合使用
以openssl库为例
vcpkg install openssl,成功的话将返回如下:1
2
3
4# 寻找添加的库
find_package(OpenSSL REQUIRED)
# 添加库链接
target_link_libraries(${PROJECT_NAME} PRIVATE OpenSSL::SSL OpenSSL::Crypto)CMakeLists.txt编写如下:(
/Users/zeroko/vcpkg/为vcpkg安装的根目录)
1 | cmake_minimum_required(VERSION 3.5) |
vcpkg与homebrew的区别
- Homebrew 主要针对 macOS 平台,而 vcpkg 支持 Windows、Linux 和 macOS
- Homebrew 主要使用 CMake 作为构建系统,而 vcpkg 支持多种构建系统,包括 MSBuild、Ninja 和 CMake
boost库
boost库是一个优秀的。可移植,开源的C++库,它是由C++标准委员会库工作自成员发起,它是对STL的延续和扩充,设计理念和STL比较接近,都是利用泛型让复用达到最大化,其中有些内容经常成为下一代C++标准库内容,在C++社区影响很大,是不折不扣的“准”标准库。
相比STL,boost更加实用。STL集中在算法部分,而boost包含了不少工具类,可以完成比较具体的工作。当下在C/C++开发中,熟练掌握boost的使用可谓是必备的。
boost主要包含一下几个大类:字符串及文本处理、容器、迭代子(Iterator)、算法、函数对象和高阶编程、泛型编程、模板元编程、预处理元编程、并发编程、数学相关、纠错和测试、数据结构、输入/输出、跨语言支持、内存相关、语法分析、杂项。 有一些库是跨类别包含的,就是既属于这个类别又属于那个类别。
C++通用开源框架和库
2022-08-24 记录
- Apache C++ Standard Library:是一系列算法,容器,迭代器和其他基本组件的集合
- ASL :Adobe源代码库提供了同行的评审和可移植的C++源代码库。
- Boost :大量通用C++库的集合。
- BDE :来自于彭博资讯实验室的开发环境。
- Cinder:提供专业品质创造性编码的开源开发社区。
- Cxxomfort:轻量级的,只包含头文件的库,将C++ 11的一些新特性移植到C++03中。
- Dlib:使用契约式编程和现代C++科技设计的通用的跨平台的C++库。
- EASTL :EA-STL公共部分
- ffead-cpp :企业应用程序开发框架
- Folly:由Facebook开发和使用的开源C++库
- JUCE :包罗万象的C++类库,用于开发跨平台软件
- libPhenom:用于构建高性能和高度可扩展性系统的事件框架。
- LibSourcey :用于实时的视频流和高性能网络应用程序的C++11 evented IO
- LibU :C语言写的多平台工具库
- Loki :C++库的设计,包括常见的设计模式和习语的实现。
- MiLi :只含头文件的小型C++库
- openFrameworks :开发C++工具包,用于创意性编码。
- [[Qt]] :跨平台的应用程序和用户界面框架
- Reason :跨平台的框架,使开发者能够更容易地使用Java,.Net和Python,同时也满足了他们对C++性能和优势的需求。
- ROOT :具备所有功能的一系列面向对象的框架,能够非常高效地处理和分析大量的数据,为欧洲原子能研究机构所用。
- STLport:是[[STL]]具有代表性的版本
- STXXL:用于额外的大型数据集的标准模板库。
- Ultimate++ :C++跨平台快速应用程序开发框架
- Windows Template Library:用于开发Windows应用程序和UI组件的C++库
- Yomm11 :C++11的开放multi-methods.
人工智能
- btsk :游戏行为树启动器工具
- Evolving Objects:基于模板的,ANSI C++演化计算库,能够帮助你非常快速地编写出自己的随机优化算法。
- Neu:C++11框架,编程语言集,用于创建人工智能应用程序的多用途软件系统。
异步事件循环
- Boost.Asio:用于网络和底层I/O编程的跨平台的C++库。
- libev :功能齐全,高性能的时间循环,轻微地仿效libevent,但是不再像libevent一样有局限性,也修复了它的一些bug。
- libevent :事件通知库
- libuv :跨平台异步I/O。
音频
声音,音乐,数字化音乐库
- FMOD :易于使用的跨平台的音频引擎和音频内容的游戏创作工具。
- Maximilian :C++音频和音乐数字信号处理库
- OpenAL :开源音频库—跨平台的音频API
- Opus:一个完全开放的,免版税的,高度通用的音频编解码器
- Speex:免费编解码器,为Opus所废弃
- Tonic:C++易用和高效的音频合成
- Vorbis:Ogg Vorbis是一种完全开放的,非专有的,免版税的通用压缩音频格式。
生物信息
基因组学和生物技术
- libsequence:用于表示和分析群体遗传学数据的C++库。
- SeqAn:专注于生物数据序列分析的算法和数据结构。
- Vcflib :用于解析和处理VCF文件的C++库
- Wham:直接把联想测试应用到BAM文件的基因结构变异。
压缩和归档库
- bzip2:一个完全免费,免费专利和高质量的数据压缩
- doboz:能够快速解压缩的压缩库
- PhysicsFS:对各种归档提供抽象访问的库,主要用于视频游戏,设计灵感部分来自于Quake3的文件子系统。
- KArchive:用于创建,读写和操作文件档案(例如zip和 tar)的库,它通过QIODevice的一系列子类,使用gzip格式,提供了透明的压缩和解压缩的数据。
- LZ4 :非常快速的压缩算法
- LZHAM :无损压缩数据库,压缩比率跟LZMA接近,但是解压缩速度却要快得多。
- LZMA :7z格式默认和通用的压缩方法。
- LZMAT :及其快速的实时无损数据压缩库
- miniz:单一的C源文件,紧缩/膨胀压缩库,使用zlib兼容API,ZIP归档读写,PNG写方式。
- Minizip:Zlib最新bug修复,支持PKWARE磁盘跨越,AES加密和IO缓冲。
- Snappy :快速压缩和解压缩
- ZLib :非常紧凑的数据流压缩库
- ZZIPlib:提供ZIP归档的读权限。
并发执行和多线程
- Boost.Compute :用于OpenCL的C++GPU计算库
- Bolt :针对GPU进行优化的C++模板库
- C++React :用于C++11的反应性编程库
- Intel TBB :Intel线程构件块
- Libclsph:基于OpenCL的GPU加速SPH流体仿真库
- OpenCL :并行编程的异构系统的开放标准
- OpenMP:OpenMP API
- Thrust :类似于C++标准模板库的并行算法库
- HPX :用于任何规模的并行和分布式应用程序的通用C++运行时系统
- VexCL :用于OpenCL/CUDA 的C++向量表达式模板库。
- 容器
- C++ B-tree :基于B树[[数据结构#树和二叉树|数据结构]],实现命令内存容器的模板库
- Hashmaps:C++中开放寻址哈希表算法的实现
密码学
- Bcrypt :一个跨平台的文件加密工具,加密文件可以移植到所有可支持的操作系统和处理器中。
- BeeCrypt:
- Botan:C++加密库
- Crypto++:一个有关加密方案的免费的C++库
- GnuPG:OpenPGP标准的完整实现
- GnuTLS :实现了SSL,TLS和DTLS协议的安全通信库
- Libgcrypt
- libmcrypt
- LibreSSL:免费的SSL/TLS协议,属于2014 OpenSSL的一个分支
- LibTomCrypt:一个非常全面的,模块化的,可移植的加密工具
- libsodium:基于NaCI的加密库,固执己见,容易使用
- Nettle 底层的加密库
- OpenSSL :一个强大的,商用的,功能齐全的,开放源代码的加密库。
- Tiny AES128 in C :用C实现的一个小巧,可移植的实现了AES128ESB的加密算法
数据库
SQL服务器,ODBC驱动程序和工具
- hiberlite :用于Sqlite3的C++对象关系映射
- Hiredis:用于[[数据库#Redis|Redis数据库]]的很简单的C客户端库
- LevelDB:快速键值存储库
- LMDB:符合[[数据库]]四大基本元素的嵌入键值存储
- MySQL++:封装了MySql的C API的C++ 包装器
- RocksDB:来自Facebook的嵌入键值的快速存储
- SQLite:一个完全嵌入式的,功能齐全的关系[[数据库]],只有几百KB,可以正确包含到你的项目中。
调试库
内存和资源泄露检测,单元测试
- Boost.Test:Boost测试库
- Catch:一个很时尚的,C++原生的框架,只包含头文件,用于单元测试,测试[[驱动开发]]和行为驱动开发。
- CppUnit:由JUnit移植过来的C++测试框架
- CTest:CMake测试驱动程序
- googletest:谷歌C++测试框架
- ig-debugheap:用于跟踪内存错误的多平台调试堆
- libtap:用C语言编写测试
- MemTrack —用于C++跟踪内存分配
- microprofile- 跨平台的网络试图分析器
- minUnit :使用C写的迷你单元测试框架,只使用了两个宏
- Remotery:用于web视图的单一C文件分析器
- UnitTest++:轻量级的C++单元测试框架
- 游戏引擎
- Cocos2d-x :一个跨平台框架,用于构建2D游戏,互动图书,演示和其他图形应用程序。
- Grit :社区项目,用于构建一个免费的游戏引擎,实现开放的世界3D游戏。
- Irrlicht :C++语言编写的开源高性能的实时#D引擎
- Polycode:C++实现的用于创建游戏的开源框架(与Lua绑定)。
图形用户界面
- CEGUI :很灵活的跨平台GUI库
- FLTK :快速,轻量级的跨平台的C++GUI工具包。
- GTK+:用于创建图形用户界面的跨平台工具包
- gtkmm :用于受欢迎的GUI库GTK+的官方C++接口。
- imgui:拥有最小依赖关系的立即模式图形用户界面
- libRocket :libRocket 是一个C++ HTML/CSS 游戏接口中间件
- MyGUI :快速,灵活,简单的GUI
- Ncurses:终端用户界面
- QCustomPlot :没有更多依赖关系的[[Qt]]绘图控件
- Qwt :用户与技术应用的[[Qt]] 控件
- QwtPlot3D :功能丰富的基于[[Qt]]/OpenGL的C++编程库,本质上提供了一群3D控件
- OtterUI :OtterUI 是用于嵌入式系统和互动娱乐软件的用户界面开发解决方案
- PDCurses 包含源代码和预编译库的公共图形函数库
- wxWidgets C++库,允许开发人员使用一个代码库可以为widows, Mac OS X,Linux和其他平台创建应用程序
图形
- bgfx:跨平台的渲染库
- Cairo:支持多种输出设备的2D图形库
- Horde3D 一个小型的3D渲染和动画引擎
- magnum C++11和OpenGL 2D/3D 图形引擎
- Ogre 3D 用C++编写的一个面向场景,实时,灵活的3D渲染引擎(并非游戏引擎)
- OpenSceneGraph 具有高性能的开源3D图形工具包
- Panda3D 用于3D渲染和游戏开发的框架,用Python和C++编写。
- Skia 用于绘制文字,图形和图像的完整的2D图形库
- urho3d 跨平台的渲染和游戏引擎。
图像处理
- Boost.GIL:通用图像库
- CImg :用于图像处理的小型开源C++工具包
- CxImage :用于加载,保存,显示和转换的图像处理和转换库,可以处理的图片格式包括 BMP, JPEG, GIF, PNG, TIFF, MNG, ICO, PCX, TGA, WMF, WBMP, JBG, J2K。
- FreeImage :开源库,支持现在多媒体应用所需的通用图片格式和其他格式。
- GDCM:Grassroots DICOM 库
- ITK:跨平台的开源图像分析系统
- Magick++:ImageMagick程序的C++接口
- MagickWnd:ImageMagick程序的C++接口
- OpenCV :开源计算机视觉类库
- tesseract-ocr:OCR引擎
- VIGRA :用于图像分析通用C++计算机视觉库
- VTK :用于3D计算机图形学,图像处理和可视化的开源免费软件系统。
国际化
- gettext :GNU `gettext’
- IBM ICU:提供Unicode 和全球化支持的C、C++ 和Java库
- libiconv :用于不同字符编码之间的编码转换库
- Json
- frozen :C/C++的Json解析生成器
- Jansson :进行编解码和处理Json数据的C语言库
- jbson :C++14中构建和迭代BSON data,和Json 文档的库
- JeayeSON:非常健全的C++ JSON库,只包含头文件
- JSON++ :C++ JSON 解析器
- json-parser:用可移植的ANSI C编写的JSON解析器,占用内存非常少
- json11 :一个迷你的C++11 JSON库
- jute :非常简单的C++ JSON解析器
- ibjson:C语言中的JSON解析和打印库,很容易和任何模型集成。
- libjson:轻量级的JSON库
- PicoJSON:C++中JSON解析序列化,只包含头文件
- qt-json :用于JSON数据和 QVariant层次间的相互解析的简单类
- QJson:将JSON数据映射到QVariant对象的基于[[Qt]]的库
- RapidJSON:用于C++的快速JSON 解析生成器,包含SAX和DOM两种风格的API
- YAJL :C语言中快速流JSON解析库
日志
- Boost.Log :设计非常模块化,并且具有扩展性
- easyloggingpp:C++日志库,只包含单一的头文件。
- Log4cpp :一系列C++类库,灵活添加日志到文件,系统日志,IDSA和其他地方。
- templog:轻量级C++库,可以添加日志到你的C++应用程序中
机器学习
- Caffe :快速的神经网络框架
- CCV :以C语言为核心的现代计算机视觉库
- mlpack :可扩展的C++机器学习库
- OpenCV:开源计算机视觉库
- Recommender:使用协同过滤进行产品推荐/建议的C语言库。
- SHOGUN:Shogun 机器学习工具
- sofia-ml :用于机器学习的快速增量算法套件
数学
- Armadillo :高质量的C++线性代数库,速度和易用性做到了很好的平衡。语法和MatlAB很相似
- blaze:高性能的C++数学库,用于密集和稀疏算法。
- ceres-solver :来自谷歌的C++库,用于建模和解决大型复杂非线性最小平方问题。
- CGal:高效,可靠的集合[[算法]]集合
- cml :用于游戏和图形的免费C++数学库
- Eigen :高级C++模板头文件库,包括线性代数,矩阵,向量操作,数值解决和其他相关的[[算法]]。
- GMTL:数学图形模板库是一组广泛实现基本图形的工具。
- GMP:用于个高精度计算的C/C++库,处理有符号整数,有理数和浮点数。
多媒体
- GStreamer :构建媒体处理组件图形的库
- LIVE555 Streaming Media :使用开放标准协议(RTP/RTCP, RTSP, SIP) 的多媒体流库
- libVLC :libVLC (VLC SDK)媒体框架
- QtAv:基于[[Qt]]和FFmpeg的多媒体播放框架,能够帮助你轻而易举地编写出一个播放器
- SDL :简单直控媒体层
- SFML :快速,简单的多媒体库
网络
- ACE:C++面向对象网络变成工具包
- Boost.Asio:用于网络和底层I/O编程的跨平台的C++库
- Casablanca:C++ REST SDK
- cpp-netlib:高级[[网络编程]]的开源库集合
- Dyad.c:C语言的异步网络
- libcurl :多协议文件传输库
- Mongoose:非常轻量级的网络服务器
- Muduo :用于Linux多线程服务器的C++非阻塞网络库
- net_skeleton :C/C++的TCP 客户端/服务器库
- nope.c :基于C语言的超轻型软件平台,用于可扩展的服务器端和网络应用。对于C编程人员,可以考虑node.js
- Onion :C语言HTTP服务器库,其设计为轻量级,易使用。
- POCO:用于构建网络和基于互联网应用程序的C++类库,可以运行在桌面,服务器,移动和嵌入式系统。
- RakNet:为游戏开发人员提供的跨平台的开源C++网络引擎。
- Tuf o :用于[[Qt]]之上的C++构建的异步Web框架。
- WebSocket++ :基于C++/Boost Aiso的websocket 客户端/服务器库
- ZeroMQ :高速,模块化的异步通信
物理学
动力学仿真引擎
- Box2D:2D的游戏物理引擎。
- Bullet :3D的游戏物理引擎。
- Chipmunk :快速,轻量级的2D游戏物理库
- LiquidFun:2D的游戏物理引擎
- ODE :开放动力学引擎-开源,高性能库,模拟刚体动力学。
- ofxBox2d:Box2D开源框架包装器。
- Simbody :高性能C++多体动力学/物理库,模拟关节生物力学和机械系统,像车辆,机器人和人体骨骼。
机器人学
- MOOS-IvP :一组开源C++模块,提供机器人平台的自主权,尤其是自主的海洋车辆。
- MRPT:移动机器人编程工具包
- PCL :点云库是一个独立的,大规模的开放项目,用于2D/3D图像和点云处理。
- Robotics Library (RL):一个独立的C++库,包括机器人动力学,运动规划和控制。
- RobWork:一组C++库的集合,用于机器人系统的仿真和控制。
- ROS :机器人操作系统,提供了一些库和工具帮助软件开发人员创建机器人应用程序。
科学计算
- FFTW :用一维或者多维计算DFT的C语言库。
- GSL:GNU科学库。
脚本
- ChaiScript :用于C++的易于使用的嵌入式脚本语言。
- Lua :用于配置文件和基本应用程序脚本的小型快速脚本引擎。
- luacxx:用于创建Lua绑定的C++ 11 API
- SWIG :一个可以让你的C++代码链接到JavaScript,Perl,PHP,Python,Tcl和Ruby的包装器/接口生成器
- V7:嵌入式的JavaScript 引擎。
- V8 :谷歌的快速JavaScript引擎,可以被嵌入到任何C++应用程序中。
序列化
- Cap’n Proto :快速数据交换格式和RPC系统。
- cereal :C++11 序列化库
- FlatBuffers :内存高效的序列化库
- MessagePack :C/C++的高效二进制序列化库,例如 JSON
- protobuf :协议缓冲,谷歌的数据交换格式。
- protobuf-c :C语言的协议缓冲实现
- SimpleBinaryEncoding:用于低延迟应用程序的对二进制格式的应用程序信息的编码和解码。
- Thrift :高效的跨语言IPC/RPC,用于C++,Java,Python,PHP,C#和其它多种语言中,最初由Twitter开发。
视频
- libvpx :VP8/VP9编码解码SDK
- FFmpeg :一个完整的,跨平台的解决方案,用于记录,转换视频和音频流。
- libde265 :开放的h.265视频编解码器的实现。
- OpenH264:开源H.364 编解码器。
- Theora :免费开源的视频压缩格式。
虚拟机
- CarpVM:C中有趣的VM,让我们一起来看看这个。
- MicroPython :旨在实现单片机上Python3.x的实现
- TinyVM:用纯粹的ANSI C编写的小型,快速,轻量级的虚拟机。
Web应用框架
- Civetweb :提供易于使用,强大的,C/C++嵌入式Web服务器,带有可选的CGI,SSL和Lua支持。
- CppCMS :免费高性能的Web开发框架(不是 CMS).
- Crow :一个C++微型web框架(灵感来自于Python Flask)
- Kore :使用C语言开发的用于web应用程序的超快速和灵活的web服务器/框架。
- libOnion:轻量级的库,帮助你使用C编程语言创建web服务器。
- QDjango:使用C++编写的,基于[[Qt]]库的web框架,试图效仿Django API,因此得此名。
- Wt :开发Web应用的C++库。
XML
XML就是个垃圾,xml的解析很烦人,对于计算机它也是个灾难。这种糟糕的东西完全没有存在的理由了。-Linus Torvalds
- Expat :用C语言编写的xml解析库
- Libxml2 :Gnome的xml C解析器和工具包
- libxml++ :C++的xml解析器
- PugiXML :用于C++的,支持XPath的轻量级,简单快速的XML解析器。
- RapidXml :试图创建最快速的XML解析器,同时保持易用性,可移植性和合理的W3C兼容性。
- TinyXML :简单小型的C++XML解析器,可以很容易地集成到其它项目中。
- TinyXML2:简单快速的C++CML解析器,可以很容易集成到其它项目中。
- TinyXML++:TinyXML的一个全新的接口,使用了C++的许多许多优势,模板,异常和更好的异常处理。
- Xerces-C++ :用可移植的C++的子集编写的XML验证解析器。
多项混杂
一些有用的库或者工具,但是不适合上面的分类,或者还没有分类。
- C++ Format :C++的小型,安全和快速格式化库
- casacore :从aips++ 派生的一系列C++核心库
- cxx-prettyprint:用于C++容器的打印库
- DynaPDF :易于使用的PDF生成库
- gcc-poison :帮助开发人员禁止应用程序中的不安全的C/C++函数的简单的头文件。
- googlemock:编写和使用C++模拟类的库
- HTTP Parser :C的http请求/响应解析器
- libcpuid :用于x86 CPU检测盒特征提取的小型C库
- libevil :许可证管理器
- libusb:允许移动访问USB设备的通用USB库
- PCRE:正则表达式C库,灵感来自于Perl中正则表达式的功能。
- Remote Call Framework :C++的进程间通信框架。
- Scintilla :开源的代码编辑控件
- Serial Communication Library :C++语言编写的跨平台,串口库。
- SDS:C的简单动态字符串库
- SLDR :超轻的DNS解析器
- SLRE:超轻的正则表达式库
- Stage :移动机器人模拟器
- VarTypes:C++/Qt4功能丰富,面向对象的管理变量的框架。
- ZBar:‘条形码扫描器’库,可以扫描照片,图片和视频流中的条形码,并返回结果。
- CppVerbalExpressions :易于使用的C++正则表达式
- QtVerbalExpressions:基于C++ VerbalExpressions 库的[[Qt]]库
- PHP-CPP:使用C++来构建PHP扩展的库
- Better String :C的另一个字符串库,功能更丰富,但是没有缓冲溢出问题,还包含了一个C++包装器。
编译器
- C/C++编译器列表
- Clang :由苹果公司开发的
- GCC:GNU编译器集合
- Intel C++ Compiler :由英特尔公司开发
- LLVM :模块化和可重用编译器和工具链技术的集合
- Microsoft Visual C++ :MSVC,由微软公司开发
- Open WatCom :Watcom,C,C++和Fortran交叉编译器和工具
- TCC :轻量级的C语言编译器
在线C/C++编译器列表
- codepad :在线编译器/解释器,一个简单的协作工具
- CodeTwist:一个简单的在线编译器/解释器,你可以粘贴的C,C++或者Java代码,在线执行并查看结果
- coliru :在线编译器/shell, 支持各种C++编译器
- Compiler Explorer:交互式编译器,可以进行汇编输出
- CompileOnline:Linux上在线编译和执行C++程序
- Ideone :一个在线编译器和调试工具,允许你在线编译源代码并执行,支持60多种编程语言。
C/C++调试器列表
- Comparison of debuggers :来自维基百科的调试器列表
- GDB :GNU调试器
- Valgrind:内存调试,内存泄露检测,性能分析工具。
C/C++集成开发环境(IDE)列表
- AppCode :构建与JetBrains’ IntelliJ IDEA 平台上的用于Objective-C,C,C++,Java和Java开发的集成开发环境
- CLion:来自JetBrains的跨平台的C/C++的集成开发环境
- Code::Blocks :免费C,C++和Fortran的集成开发环境
- CodeLite :另一个跨平台的免费的C/C++集成开发环境
- Dev-C++:可移植的C/C++/C++11集成开发环境
- Eclipse CDT:基于Eclipse平台的功能齐全的C和C++集成开发环境
- Geany :轻量级的快速,跨平台的集成开发环境。
- IBM VisualAge :来自IBM的家庭计算机集成开发环境。
- Irony-mode:由libclang驱动的用于Emacs的C/C++微模式
- KDevelop:免费开源集成开发环境
- Microsoft Visual Studio :来自微软的集成开发环境
- NetBeans :主要用于Java开发的的集成开发环境,也支持其他语言,尤其是PHP,C/C++和HTML5。
- Qt Creator:跨平台的C++,Javascript和QML集成开发环境,也是Qt SDK的一部分。
- rtags:C/C++的客户端服务器索引,用于 跟基于clang的emacs的集成
- Xcode :由苹果公司开发
- YouCompleteMe:一个用于Vim的根据你敲的代码快速模糊搜索并进行代码补全的引擎。
构建系统
- Bear :用于为clang工具生成编译[[数据库]]的工具
- Biicode:基于文件的简单依赖管理器。
- CMake :跨平台的免费开源软件用于管理软件使用独立编译的方法进行构建的过程。
- CPM:基于CMake和Git的C++包管理器
- FASTBuild:高性能,开源的构建系统,支持高度可扩展性的编译,缓冲和网络分布。
- Ninja :专注于速度的小型构建系统
- Scons :使用Python scipt 配置的软件构建工具
- tundra :高性能的代码构建系统,甚至对于非常大型的软件项目,也能提供最好的增量构建次数。
- tup:基于文件的构建系统,用于后台监控变化的文件。
静态代码分析
提高质量,减少瑕疵的代码分析工具列表
- Cppcheck :静态C/C++代码分析工具
- include-what-you-use :使用clang进行代码分析的工具,可以#include在C和C++文件中。
- OCLint :用于C,C++和Objective-C的静态源代码分析工具,用于提高质量,减少瑕疵。
- Clang Static Analyzer:查找C,C++和Objective-C程序bug的源代码分析工具
- List of tools for static code analysis :来自维基百科的静态代码分析工具列表W