PE
PE
ZEROKO14什么是可执行文件
可执行文件(executable file)指的是可以由操作系统进行加载执行的文件。
可执行文件的格式:
- windows平台:PE(Portable Executable)文件结构
- Linux平台:ELF(Executable and Linking Format)文件结构
哪些领域会用到PE文件结构
- 病毒与反病毒
- 外挂与反外挂
- 加壳与脱壳(保护与破解)
- 无源码修改功能,软件汉化等等
如何识别PE文件
PE文件的特征(PE指纹)
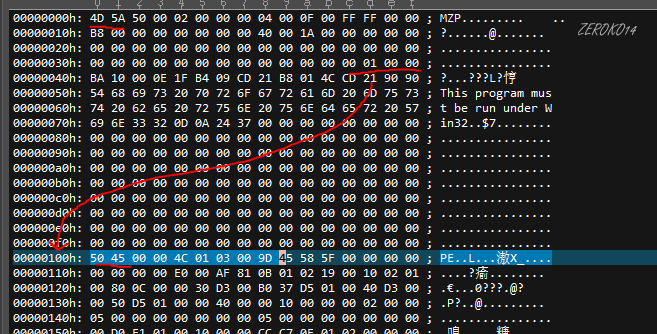
分别打开.exe .dll .sys 等文件,观察特征前2个字节
UE二进制方式打开文件,前两个字节是4D 5A表示得字符是MZ,然后0x3c的地址处如果说是E0 00 00 00,就到000000E0地址处查看前两个字节是不是50 45,表示得字符是PE,如果上述的都满足,就说明这个文件是PE文件。

不要仅仅通过文件名的后缀名来认定PE文件(因为后缀名是可以改的)
PE文件结构
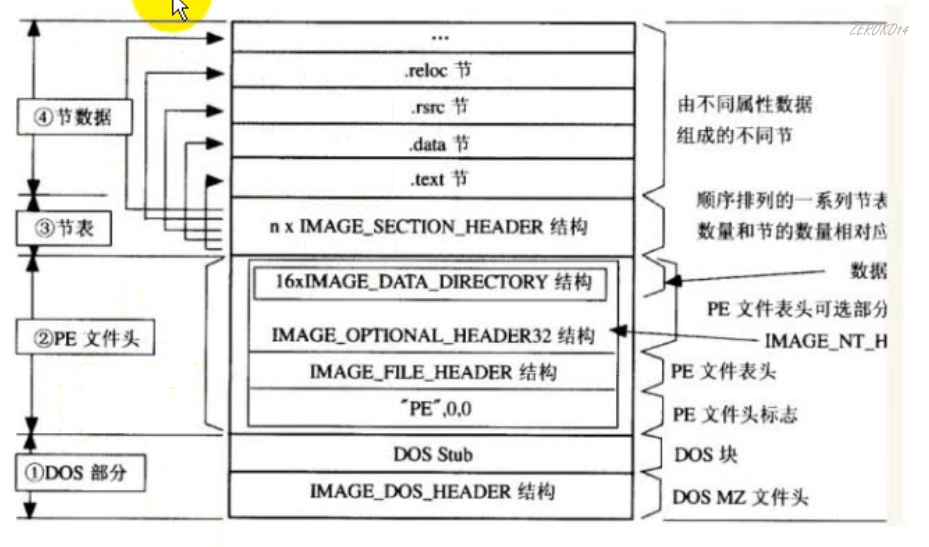
- DOS部分是历史遗留问题,以前是DOS系统
- PE文件头是给windows用的
- 节表,当前文件一共分成多少部分,就是一个索引目录
- 节数据,存具体的数据
WINNT.H的文件中定义了PE文件需要用到的结构体

详细的结构体信息参考pe结构.pdf
PE在文件中结构参考
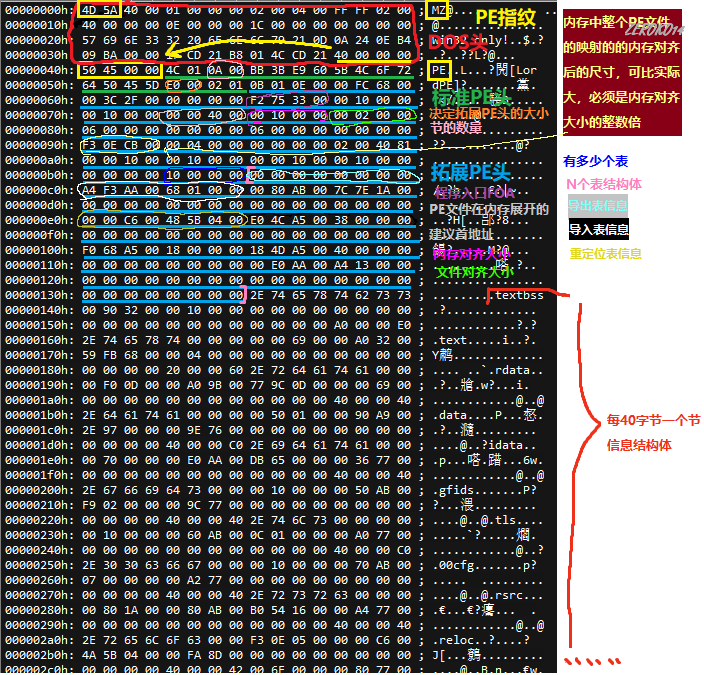
主要结构体
DOS部分
IMAGE_DOS_HEADER结构:
DOS MZ文件头,固定为64个字节
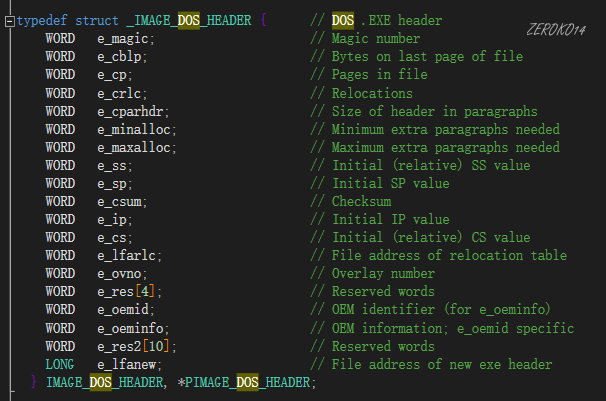
1 | //这个结构体都是给16位程序看的,所以都是无用的,只有e_magic和e_lfanew有用,是例外 |
只有e_magic和e_lfanew有用,e_magic修改的话直接不能打开了,e_lfanew指向PE头的地址,修改的话,对应位置也要改为PE头和其后续的内容
DOS Stub(DOS块)
大小不确定,这块数据是给链接器用的,链接器会往里面插入数据;DOS块的内容,不会影响程序执行,所以可以肆意修改(因为是DOS系统历史遗留问题,PE保留了这个结构,仅在dos系统有用)
默认内容为弹框显示当前程序在dos系统不可用(仅在dos系统有效)
DOS块不是一个结构体,是由一堆单个字节的数据组成的数据
IMAGE_DOS_HEADER结构中的e_lfanew指向了PE头,从DOS MZ部分尾到PE头之间的就是DOS块
整个DOS块可以全部修改都不影响程序运行
PE文件头
真正有用的数据是从PE头开始的
PE标识不能破坏,操作系统在启动一个程序的时候会检测该标识,映射到内存后可破坏
PE文件头的数据结构
1 | //32位 |
PE文件头NtHeader包含三个部分
- PE文件头标记 Signature,存的是‘P’ ‘E’,0,0(4个字节)
- 标准PE头 FileHeader(20个字节)(这个FileHeader英文名是对应010 Editor中的名字)
- 拓展PE头 OptionalHeader(这个结构体32位(默认224个字节)和64位(默认240个字节)文件不一样)
标准PE头
固定20个字节
1 | typedef struct _IMAGE_FILE_HEADER { |
p.s.C:\Windows\SysWOW64存放的是32位PE文件,C:\Windows\System32存放的是64位PE文件
应该根据SizeOfOptionalHeader字段的长度去解析后面的拓展PE头的数据
OD原版是默认识别224位拓展pe头的。
Characteristics字段含义:
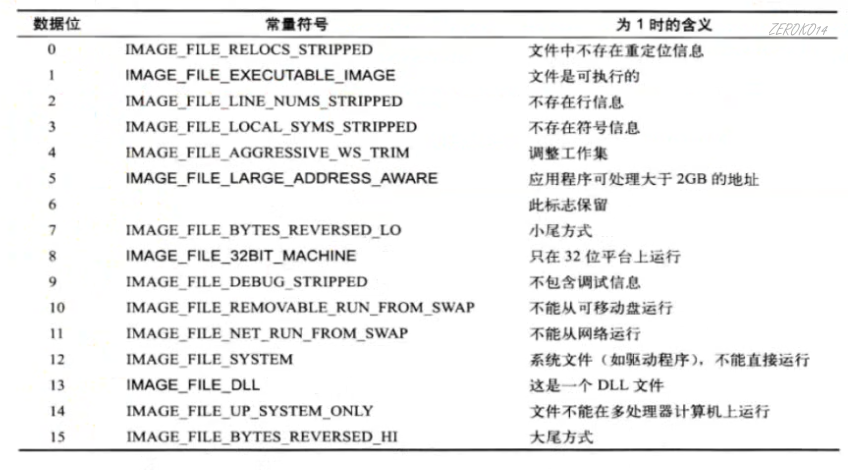
32位notepad.exe比如0x0102,展开成二进制为0000 0001 0000 0010,意思是第1位和第8位是1,所以对照上图,文件是可执行的并且只在32位平台运行
64位notepad.exe比如0x0022,展开成二进制为0000 0000 0010 0010,意思是第1位和第5位是1,所以对照上图,文件是可执行的并且应用程序可处理大于2GB的地址
应用程序可处理大于2GB的地址的理解:应用程序在32位有4GB的存储空间,内核部分用了2G,应用程序可处理低2G的内存空间,这个设置最高可以达到用户地址3G,部分游戏优化器会这么做
拓展PE头
32位的拓展PE头默认占224个字节,但可以靠修改标准PE头中的SizeOfOptionalHeader修改它的大小,然后往里面添加东西
拓展PE头有三类:1.32位 2.64位 3.嵌入式
结构如下:(下面的”没用”表示不具备参考意义,可以随意修改的)(注意重点)
1 | //32位的拓展PE头结构 |
文件对齐的意思:假设DOS头加上PE头加上节表大小为0x302,且FileAlignment存的是0x200,则SizeOfHeaders里面文件对齐的数值为0x400
OD原版的分析功能,参考了这个SizeOfCode字段来确定读入的代码数,而这个字段只是一个参考字段,因此这里可以作为反OD原版其中一个方案的方式,把这个数设置得超大直接读不了那么多而让od崩溃,或者设置得比较大,让od很卡(一般8位16进制高位给个1)。
DllCharacteristics详细选项(WORD拆分为16位,按位对应含义)

其中IMAGE_DLLCHARACTERISTICS_DYNAMIC_BASE很重要,决定了是否随机基址.
1 | //64位的拓展PE头结构 |
1 | typedef unsigned __int64 ULONGLONG;//无符号64位int |
嵌入式设备PE拓展头
1 | typedef struct _IMAGE_ROM_OPTIONAL_HEADER { |
节表 SectionHeaders
真正的数据都存在节里
有多少个节呢,节从哪开始到哪结束,存储的是什么数据,能读能写等等这些信息都存在节表里,相当于[节数据](#节数据 Section)的目录
节表实际上是一个结构体数组,每一个结构体成员40个字节,每一个结构体都可以描述一个节的特性(所有节相关的重要特性都记录在节表中)
标准PE头中的NumberOfSections字段决定节的数量
1 | typedef struct _IMAGE_SECTION_HEADER { |
上面的Misc字段详解【理解】
Misc的大小有可能比SizeOfRawData大,也有可能比SizeOfRawData小
有初始值的全局变量和没有初始值的全局变量,没有初始值的全局变量在文件中是不给他分配位置的,但在内存中是有位置且初始化了值的
由于上面这点,所以Misc的大小有可能比SizeOfRawData大,但是又由于Misc是未内存对齐的数据大小,所以Misc 内存对齐后的大小有可能比SizeOfRawData小
实际在内存中到底占多大取决于SizeOfRawData和Misc的大小比较,若SizeOfRawData大则直接占SizeOfRawData的大小的空间,若Misc大则按照Misc内存对齐后的大小占用空间
Characteristics节的属性详解(DWORD拆分为32位,按位对应含义)
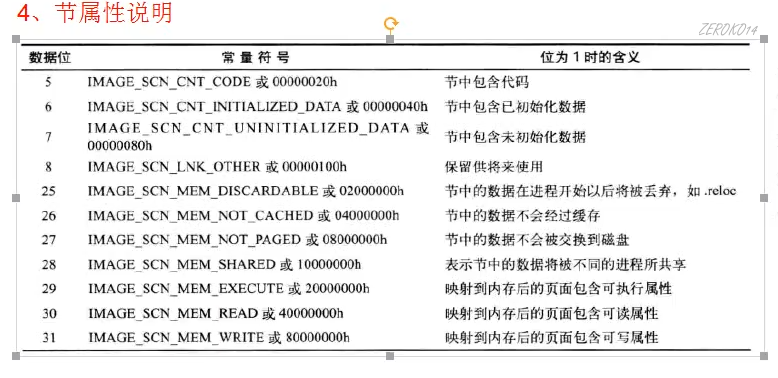
比如Characteristics中二进制1100 0000 0000 0000 0000 0000 0100 0000
表示的是节中包含已初始化数据,映射到内存后的页面包含可读可写属性。
由此可知这个节存的都是可读可写的全局变量(参考[[C语言入门#内存布局|C语言入门部分内存布局]]的
全局初始化数据区/静态数据区)
比如观察一个实际的文件的
.text节表中,只有IMAGE_SCN_CNT_CODE,IMAGE_SCN_MEM_EXECUTE和IMAGE_SCN_MEM_READ被置为1
.rsrc节表中,只有个IMAGE_SCN_CNT_INITIALIZED_DATA和IMAGE_SN_MEM_READ被置为1
rsrc节表一般用于存储Windows可执行文件中的资源信息,如图标、位图、字符串、对话框等。这些资源可以被程序在运行时动态加载和使用。
编译完了以后很多成员是没有意义的,所以也可以往这里成员里写入自己想写入的东西
节表后面会被编译器插入很多数据,这些数据不能动,不然会出问题
节数据 Section
节数据的开始位置一定是拓展PE头里的SizeOfHeaders字段的地址位置。
节数据中的每个节也是要按照拓展PE头里的SizeOfHeaders字段进行文件对齐
PE文件的两种状态
上述所有结构都是针对PE在硬盘文件中的状态
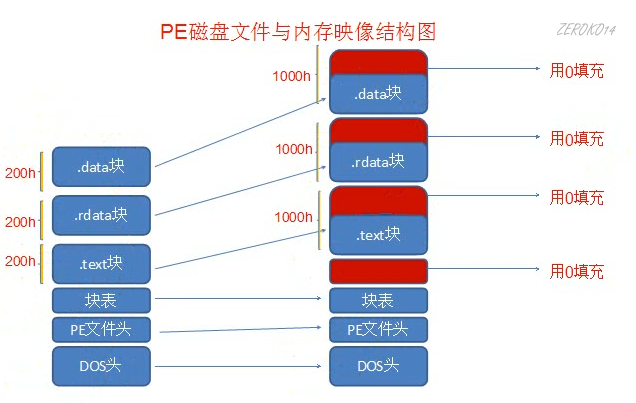
如图,PE文件在内存是按照SectionAlignment内存对齐,如果SectionAlignment和FileAlignment一样的话,那么PE在磁盘文件和在内存中就是一样的
块表和节表是一样的。
通过WinHex图示按钮可以查看exe在内存中的视图
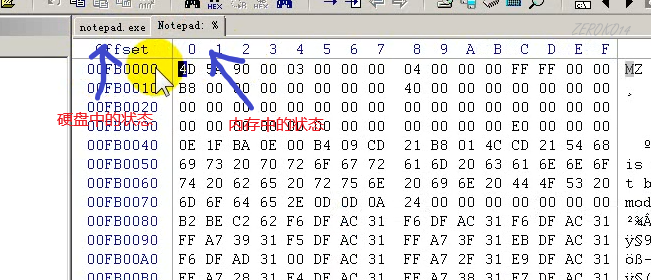
在内存中节的大小按照拓展PE头中的SectionAlignment字段进行的内存对齐,而不是文件对齐
上图PE磁盘文件与内存映像结构图中为什么每个刚好是0x1000,就是因为拓展PE头中的SectionAlignment字段为0x1000,并且每个节的真正字节大小为:小于等于0x1000
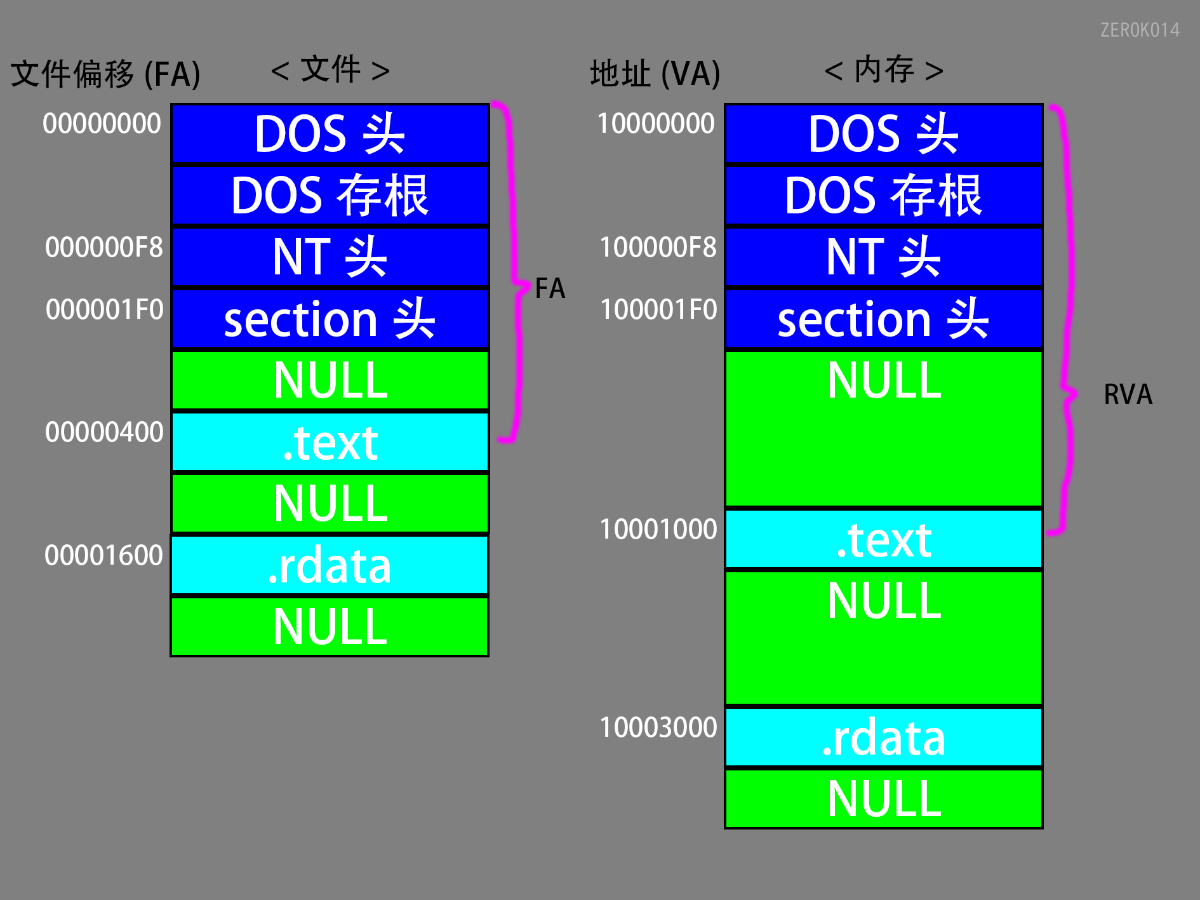
RVA到FOA的转换
RVA:Relative Virtual Address(相对虚拟地址)
FOA:File Offset Address(文件偏移地址)
相对虚拟地址到文件偏移地址的转换(内存对齐与文件对齐不一样的情况)
得到RVA的值:内存地址-ImageBase
判断RVA是否位于PE头中,如果是:FOA==RVA
判断RVA位于哪个节:
RVA>=节.VirtualAddress
RVA<节.VirtualAddress+节.virtualSize
差值=RVA-节.VirtuallAddress;
FOA=节.PointerToRawData+差值;
想要找的目标地址到当前节头的差值在文件中和在内存中是一样的
如果文件对齐和内存对齐是一样的,那么直接FOA=内存地址-ImageBase。也就是FOA=RVA
PE的空白区添加代码
加壳:通常的目的就是为了隐藏程序的入口。
病毒:感染了程序,在程序执行之前先做病毒的事情。
让程序执行之前,先执行我们添加的代码,再执行程序
空白区添加代码的步骤
构造要写入的代码(这里的例子是弹出一个对话框)(E8这种CALL是不依赖于导入表的)
1
2
36A 00 6A 00 6A 00 6A 00 E8 00 00 00 00 E9 00 00 00 00
//6A 00为push 0 E8为call,后面填入messagebox的call的地址-E8指令当前的地址-5
E9 为jmp,后面的00000000要填入程序入口地址-E9指令当前的地址-5(跳回程序入口)上面目前构造的硬编码只可以在自己的电脑上执行,若上面构造的硬编码为在任何机器上都可以执行,那么他就是一段标准的shellCode,后续会讲在PE的空白处构造一段代码
修改入口地址为空白区新增代码的所在地址
扩大节
我们可以在任意空白区添加自己的代码,但如果添加的代码比较多,空白区不够怎么办?
扩大节。扩大最后一节就无需修正前面的节了
扩大节的步骤:
1.分配一块新的空间,大小为S(直接增加内存对齐的倍数省事)
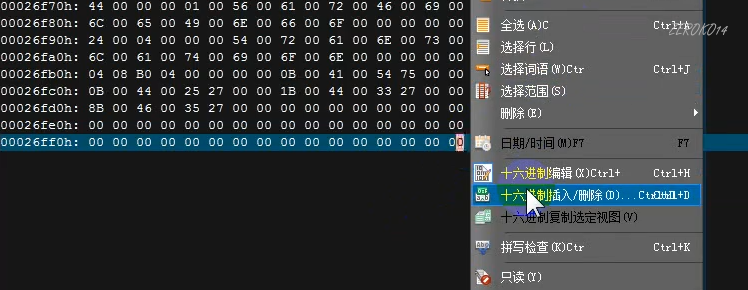
将最后一个节的SizeOfRawData和VirtualSize改为N(看谁大)
N=(SizeOfRawData或者VirtualSize按照内存对齐后的值)+S
修改SizeOfImage(拓展PE头里的字段)大小
SizeOfImage新值=SizeOfImage旧值按内存对齐+S
扩大节的目的是为了插入代码执行的,所以当前节必须是可执行的,如果不行,则还需要手动修改当前节的节表里的当前节结构体的Characteristics节的属性字段,改成可执行字段
新增节
扩大节,新增的代码和原代码混在一起了。
还有一种方法是新增一个自己的节
新增节的步骤
- 判断是否有足够的空间,可以添加一个节表(不确定不够的话是否可以修改sizeOfHeader强行增加,010Editor中可以)
- 修改节表末尾节的大小(只是为了省事,不修改的话麻烦一丢丢,下面例子修改了末尾节)
- 在节表中新增一个成员
- 修改PE头中节的数量
- 修改sizeOfImage的大小
- 在原有数据的最后,新增一个节的数据(内存对齐的整数倍)
- 修正新增节表的属性
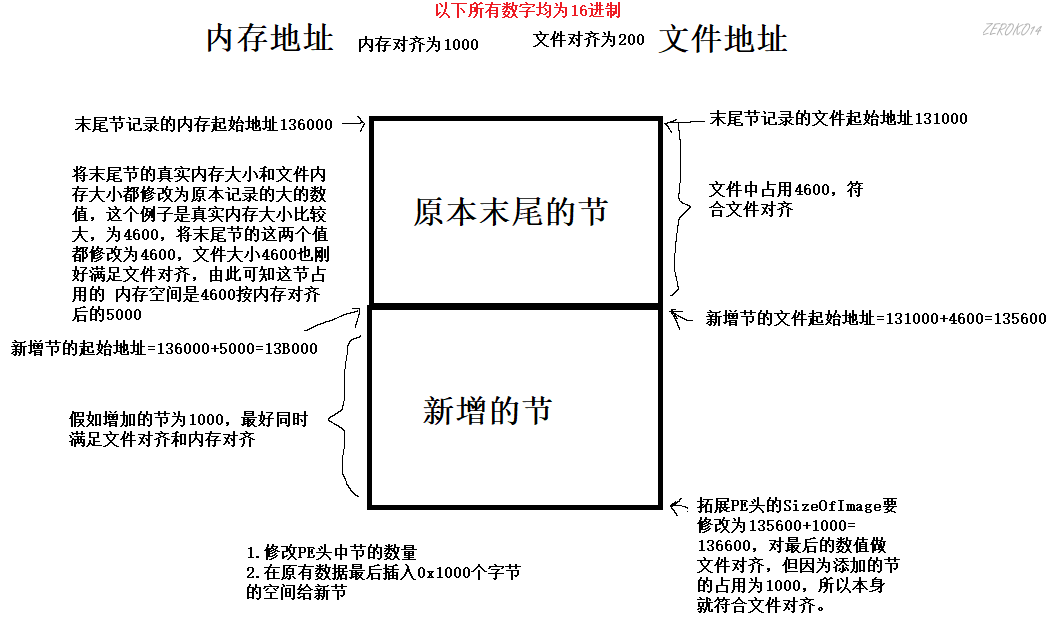
上图右下角有问题,严格来说应该是对最后的数值做内存对齐,这里的写文件对齐是因为,这个案例中文件对齐和内存对齐相等
新增节前:

新增节后:(.tttt为新增节的名称)

合并节
问:如果节表没有地方可以插入成员了怎么办?
答:合并节
| 涉及的节表成员 | 含义 |
|---|---|
| Name | 节名称 |
| VirtualAddress | 节在内存中的偏移 (RVA) |
| Misc | 节的实际大小 |
| SizeOfRawData | 节在文件中对齐后的尺寸 |
| PointerToRawData | 节区在文件中的偏移 |
| Characteristics | 节的属性 |
| 涉及的标准PE头成员 | 含义 |
|---|---|
| NumberOfSections | 节的个数 |
下面合并所有节
合并节的步骤
将每个节都修正内存对齐
将第一个节的内存大小,文件大小改成一样
最后一个节Max=SizeOfRawData>VirtualSize内存对齐后?SizeOfRawData:VirtualSize内存对齐后
第一个节SizeOfRawData=VirtualSize=最后一个节的VirtualAddress+最后一个节Max-SizeOfHeaders内存对齐后的大小
将第一个节的属性改为包含所有节的属性
修改节的数量为1
修正内存对齐
修正内存对齐 使得 节文件对齐后的大小和内存对齐后的大小一致,方便后续合并节
| 涉及的节表成员 | 含义 |
|---|---|
| Misc | 节的实际大小 |
| SizeOfRawData | 节在文件中对齐后的尺寸 |
| PointerToRawData | 节区在文件中的偏移 |
- 计算节内存对齐后的大小
- 计算差值 = 节内存对齐后的大小 - 节文件对齐后的大小
- 计算节在文件中的末尾位置 = 节在文件中的偏移 + 节文件对齐后的大小
- 在节的文件中的末尾位置后填充新空间,新空间的大小为 前面计算的差值
- 修正Misc和SizeOfRawData为节内存对齐后的大小
- 在该节后面的节在文件中的偏移增加差值
计算节内存对齐后的大小
节内存对齐后的大小 = ( max{Misc,SizeOfRawData} ÷ SectionAlignment)向上取整 × SectionAlignment
即节内存对齐后的大小 = ( max{0x62008,0x62200}÷0x1000)向上取整 × 0x1000
即节内存对齐后的大小 = ( max{0x62008,0x62200}÷0x1000)向上取整 × 0x1000
即节内存对齐后的大小 = (0x62200 ÷ 0x1000)向上取整 × 0x1000 = 0x63000
计算差值
差值 = 节内存对齐后的大小 - 节文件对齐后的大小 = 节内存对齐后的大小 - SizeOfRawData
即 差值 = 0x63000 - 0x62200 = 0xE00
计算节在文件中的末尾位置
节在文件中的末尾位置 = 节在文件中的偏移 + 节文件对齐后的大小
即节在文件中的末尾位置 = PointerToRawData + SizeOfRawData
即节在文件中的末尾位置 = 0x1dfa00 + 0x62200 = 0x241C00
填充新空间
找到前面计算出来的节在文件中的末尾位置
选择插入的大小为:0xE00(对应十进制为3584),即插入前面计算出来的差值
插入后,保存
修正节成员
修正Misc和SizeOfRawData为节内存对齐后的大小:0x63000
修正后:
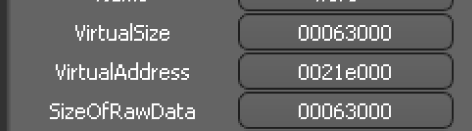
修正后面的节
在该节后面的节在文件中的偏移增加差值
修改其PointerToRawData = PointerToRawData + 差值
即 PointerToRawData = 0x241c00 + 0xe00 = 242A00
表
问:一个可执行程序是由一个PE文件组成的吗?
答:不是
导入表:记录当前PE文件用到哪些PE文件中的哪些函数
导出表:当前的PE文件提供了哪些函数给别的PE文件使用
拓展PE头最后一个字段是一个记录了所有表信息的结构体数组
1 | IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES]; |
1 | // Directory Entries目录入口:结构体数组每个下标对应的含义 |
结构体IMAGE_DATA_DIRECTORY
1 | typedef struct _IMAGE_DATA_DIRECTORY { |
导出表
将DataDirectory[0].VirtualAddress转换为FOA,则可以在对应文件中找到导出表
导出表结构如下:
1 | //40字节 |
举例导出如下:
1 | EXPORTS |
上面导出文件对应的在PE文件中所有导出函数的个数NumberOfFunctions为5,以函数名字导出的函数个数NumberOfNames为3。
NumberOfFunctions为5是因为序号断档也会算进去,12,13,14,15,16刚好5个序号
函数地址表

函数名称表
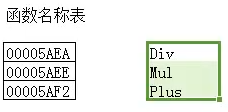
函数名称表是按照字母排序的
序号表
序号表内项的个数取决于名字表里项的个数。
序号表是两个字节为一个项的
序号表是为函数名称表找函数地址表服务的
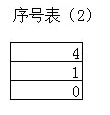
里面的内容表示的是函数名称表中的项在函数地址表中的位置
【总结】重点
通过函数名称在函数名称表找到要找的函数在函数名称表中的下标,通过此下标在函数序号表中找到对应的值,该值表示要找函数在函数地址表中的下标。用此值在函数地址表中找到要找函数的地址。
解读GetProcAddress函数
1 | //功能是检索指定的动态链接库(DLL)中的输出库函数地址 |
原理
- 找名字的话原理就是到函数名称地址表找函数名,找到的话返回下标,用下标到序号表中找到对应的序号,用序号到函数地址表中取出函数地址返回
- 找序号的话原理就是先找到Base字段,确定起始序号,然后找多少序号,就在起始序号上偏移多少序号(要找的序号-起始序号=函数地址表要找的下标),也就用这个在函数地址表找到函数地址
导入表
一个进程是由一组PE文件构成的:
PE文件提供哪些功能:导出表
PE文件需要依赖哪些模块以及依赖这些模块中的哪些函数:导入表
导出表只有一个,导入表有一堆,所以_IMAGE_DATA_DIRECTORY的VirtualAddress存的是导入结构的数组(判断到末尾的依据是读到20个字节的0表示到头了)
导入表是拓展pe头最后一个字段的第2个结构体存了导入表对应的位置(指向的是导入表的第一个结构体),和对应的大小。
导入表(结构体数组)的单个结构体结构:
1 | //共占20个字节,每个该结构体描述一个导入的PE文件 |
导入表:确定依赖的函数
下图是PE文件加载到内存前在文件中的结构
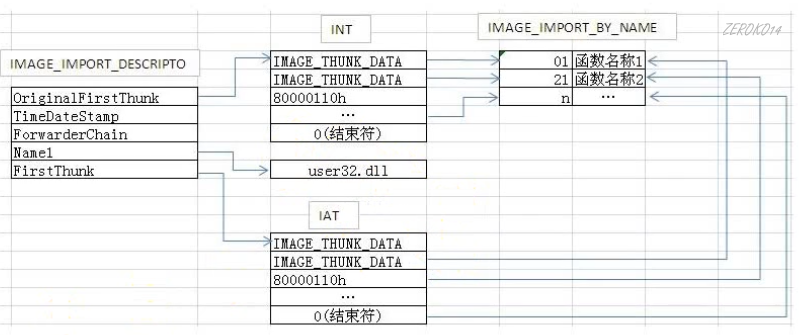
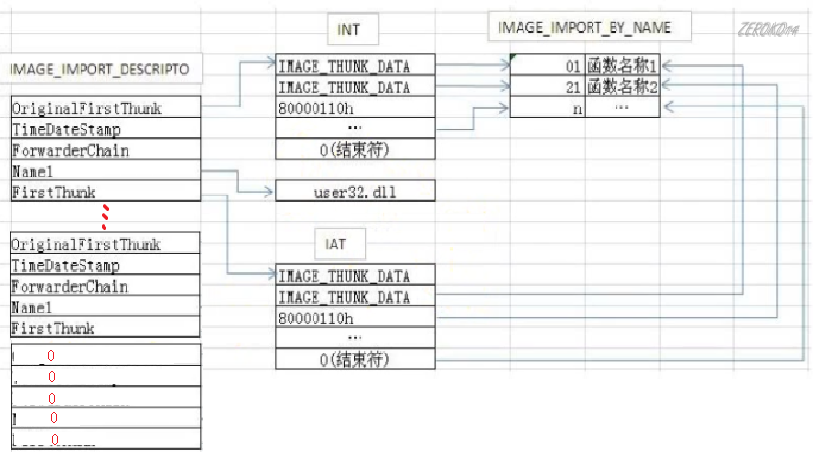
- INT:import name table导入名称表
- IAT:import address table导入地址表
FirstThunk和OriginalFirstThunk在文件中都指向同样的_IMAGE_THUNK_DATA32数组,在文件中都指向内容为INT
INT和IAT中有多少个项表明该PE文件有多少个导入函数(4个字节的0表示结束符)
如图INT和IAT中的项结构是IMAGE_THUNK_DATA
1 | //该结构体只占4个字节,每个该结构体描述一个函数 |
_IMAGE_THUNK_DATA32中内容的判断方式
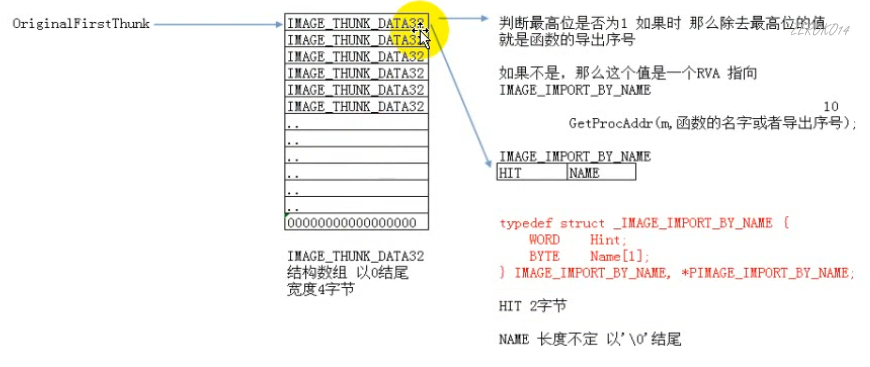
- 判断最高位是否1,若是,那么除去最高位的值就是函数的导出序号
- 若不是,那么这个值是一个RVA指向IMAGE_IMPORT_BY_NAME
1 | typedef struct _IMAGE_IMPORT_BY_NAME { |
导入表:确定函数地址
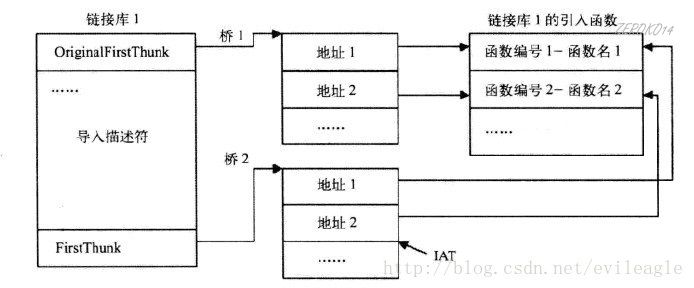
当我们的程序调用了一个别的dll中的函数,编译器就会在我们程序的导入表中生成一个相关的结构。
这些结构的最终目的都是为了程序在运行的时候能得到函数的内存地址。
下面的call是一个间接call,只要我们用的是其他dll中的函数,那么我们这个call生成的都是这种间接call

这个call的地址指向的内容是

直接指向的是函数地址
这是因为PE文件在加载到内存后,导入表的结构会发生变化
在文件中:
加载到内存后:
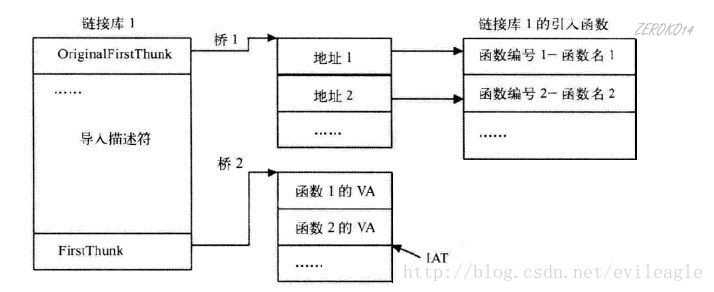
此时FirstThunk指向的不再是OriginalFirstThunk指向的结构
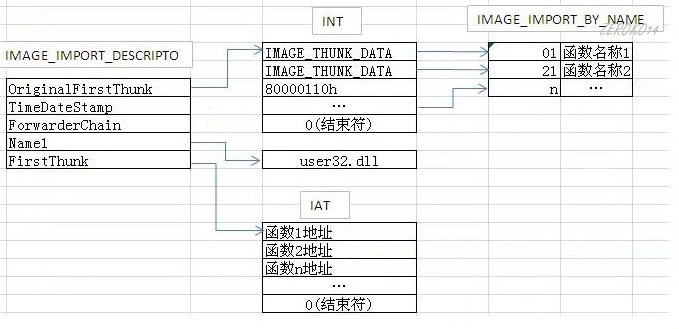
FirstThunk而是指向直接的函数地址(IAT)。加载到内存的时候,由操作系统根据函数名称或导出表中的索引到对应dll的导出表去找内存地址填入FirstThunk指向的数组
脱壳的时候修复导入表就是利用OrignalFirstThunk指向的最终的函数名称获取到函数内存地址,去修复firstThunk指向的IAT
重定位表
举个例子,未初始化的全局变量的虚拟地址不是RVA,而是以固定的虚拟地址写死在汇编中(如下图,x是未初始化的全局变量)。所以在加载到内存中之后如果不是加载到对应的PE文件的imageBase的话会出问题。(xp系统以后都是动态加载,原因就是因为有重定位表)

所以重定位表就是为了解决这个问题的
重定位表:一张记录了所有要修改的地址的地址表
数据目录项的第6个结构,就是重定位表
重定位表是一堆重定位块结构体数组
每个重定位块的结构体:
1 | //实际上是一个物理页(4KB)创建一个重定位块 |
下图一个格子表示一个字节,X为VirtualAddress,Y为SizeOfBlock
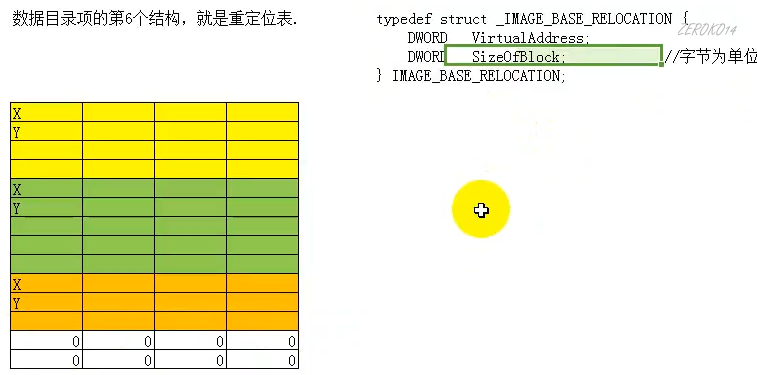
重定位表到连续8个字节为0表示到头了(也就是VirtualAddress和SizeOfBlock都为0表示到头了)。
IMAGE_BASE_RELOCATION结构和后面紧跟的若干个Typeoffset组成了一个块,其大小为结构体中的SizeOfBlock
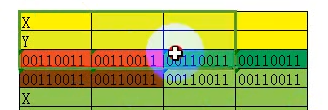
重定位块是按照上图红色部分这样两个字节存一个要修改的地址
因为每个重定位块的VirtualAddress是按照物理页一页(0x1000字节)来分的,所以内部的红色部分实际上真正使用的只需要12位(0xFFF)就能索引到物理页任何一个地址,因此高4位挪作他用。
只有高4位为3的时候,才表明这个数据块内的这个地址是需要被重定位的,不是3表示这里面的值不需要重定位,实际上就是因为这个值只是用来内存对齐用于填位置用的,里面的值是没意义的所以不需要重定位
所以真正重定位针对的地址是:VirtualAddress(图中X)+红色部分组成的地址的低12位。
找到需要重定位的地点之后,怎么重定位呢?前文说到Typeoffset指示了多种重定位类型,其中最常见的为3,在此只介绍这种情况。其他重定位类型的主体思想基本是相似的,只有细微的不同。
我们首先计算得到基地址的偏移量,也就是实际的DLL加载地址减去DLL的推荐加载地址。DLL推荐加载地址保存在拓展PE头中的ImageBase成员中,而实际DLL加载地址并不一定在那位置上。然后我们将VirtualAddress和Typeoffset低12位合力组成的地址所指向的双字加上这个偏移量,重定位就完成了。
$$
(DWORD)(VirtualAddress + Typeoffset的低12位) += (实际DLL加载地址 – 推荐DLL加载地址)
$$
简单加密壳编写
手动映射DLL
exe编译出的debug版是带重定位表的,浮动基址的exe都带有重定位表
将一个DLL贴入内存中,使其可以使用,需要下面三步
- 手动将文件拉伸对齐后写入内存
- 修改IAT表
- 根据重定位表修正内存中基址相关数据
- 调用DLL入口点(入口点可以通过拓展PE头中的AddressOfEntryPoint找到。一般地,它会完成C运行库的初始化,执行一系列安全检查并调用dllmain。)
文件一旦“落地”就也存在着被杀毒软件查杀的风险,因此可以以加密的方式存储到硬盘上。
为什么要修改IAT表和重定位表?
- 程序可以在不重建导入表的情况下工作,但前提是您不使用任何导入的函数。尝试访问尚未解析的导入代码将失败;
- 为简单起见,PE 可执行文件是位置无关的(可以在任何基地址上工作),即使代码不是。为此,该文件包含一个重定位表,用于调整依赖于基地址位置的所有数据。如果可以在首选地址(
pINH->OptionalHeader.ImageBase)加载,这点是可选的,但这意味着如果使用重定位表,则可以在任何地方加载图像,并且可以省略的第一个参数VirtualAlloc(并删除相关检查)。
重载内核练习
内核文件本身就是一个exe文件,实际上内核重载就是内核可执行程序在零环内存中的文件展开
- 手动将文件拉伸对齐后写入内存
- 修改IAT表
- 根据重定位表修正内存中基址相关数据
- 修改新内核系统服务表(老SSDT函数地址-老内核基址+新内核基址=新SSDT函数地址)
- HOOK KiFastCallEntry(HOOK原内核的KiFastCallEntry,如果是目标进程则将跳转改为新内核的系统服务表。)
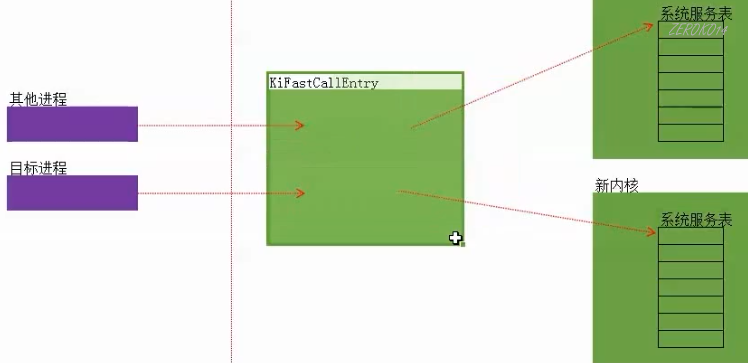
重载内核的弊端:太容易被发现了,随便搜一个内核函数的特征码都能搜索出来两份。
可以尝试加密内核函数,走HOOK的时候才解密